
NvidiaУлAccentureєПЧчВКПИНЖіц¶ЁЦЖµДLlamaґуРНУпСФДЈРН
°ЈЙХЬЅьИХРыІјНЖіц»щУЪNvidiaРВAI Foundry·юОсїЄ·ўµДAccenture AI RefineryїтјЬЎЈёГІъЖ·ЦјФЪК№їН»§ДЬ№»К№УГ Llama 3.1 ДЈРН№№ЅЁ¶ЁЦЖµДґуРНУпСФДЈРНЈ¬К№ЖуТµДЬ№»К№УГЧФјєµДКэѕЭєНБчіМНкЙЖєНёцРФ»ЇХвР©ДЈРНЈ¬ТФґґЅЁМШ¶ЁБмУтµДЙъіЙКЅ AI Ѕвѕц·Ѕ°ёЎЈ
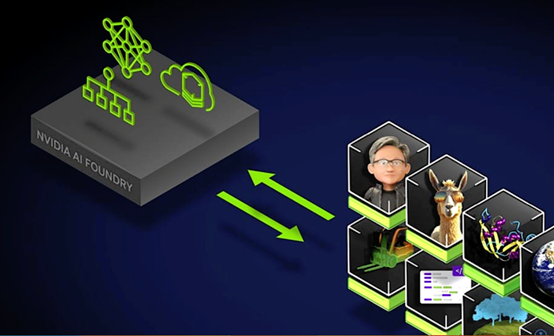
ЙъіЙКЅAIЧЯПтNvidia AI FoundryµДВГіМ
ФЪТ»ґОјт±Ё»бЙПЈ¬Nvidia№«ЛѕAIИнјюё±ЧЬІГKari Briski±нКѕЈ¬ЛэѕіЈ±»ОКј°ЙъіЙКЅAIПа№ШµДОКМвЎЈ
“ХвКЗТ»¶ОВГіМЈ¬КЗµДЈ¬ЙъіЙКЅAIКЗТ»ПоѕЮґуµДН¶ЧКЎЈЖуТµ»бОКЈ¬‘ОТГЗОЄКІГґТЄХвСщЧцЈїУГАэКЗКІГґЈї’µ±ДгПлµЅФ±№¤ЙъІъБ¦К±Ј¬ДгКЗ·сПЈНыЧФјєТ»МмУРёь¶аµДК±јдЈїОТЦЄµАОТ»бµДЎЈТІРнИз№ыУР10ёцИЛЈ¬ДгїЙТФНкіЙёь¶аµДКВЗйЎЈХвѕНКЗЙъіЙКЅAIµДУГОдЦ®µШ——ЧФ¶ЇЦґРРЦШёґЎўЖЅ·ІµДИООсЈ¬АэИзЧЬЅбЎўЧојСКµјщєНєуРшІЅЦиЎЈ”
AI FoundryЈєИ«ГжµД»щґЎЙиК©
“Nvidia AI FoundryКЗТ»По·юОсЈ¬К№ЖуТµДЬ№»К№УГјУЛЩјЖЛгєНИнјю№¤ѕЯЈ¬ЅбєПОТГЗµДЧЁТµЦЄК¶АґґґЅЁєНІїКрїЙТФОЄЖуТµЙъіЙКЅAIУ¦УГФцЗїµДЧФ¶ЁТеДЈРНЈ¬”BriskЛµЎЈ
AI FoundryЖЅМЁМṩБЛУГУЪїЄ·ўєНІїКрЧФ¶ЁТеAIДЈРНµД»щґЎЙиК©Ј¬°ьАЁЈє
- »щґЎДЈРНЈєТ»МЧNvidiaєНЙзЗшДЈРНЈ¬°ьАЁLlama 3.1ЎЈ
- јУЛЩјЖЛгЈєDGX CloudМṩїЙА©Х№µДјЖЛгЧКФґЈ¬Хв¶ФУЪґуРНAIПоДїАґЛµЦБ№ШЦШТЄЎЈ
- ЧЁјТЦ§іЦЈєNvidia AI EnterpriseµДЧЁјТРЦъїЄ·ўЎўОўµчєНІїКрAIДЈРНЎЈ
- єПЧч»п°йЙъМ¬ПµНіЈєУл°ЈЙХЬµИєПЧч»п°йµДєПЧчЈ¬ОЄAIЗэ¶ЇµДЧЄРНПоДїМṩЧЙСЇ·юОсєНЅвѕц·Ѕ°ёЎЈ
Brisk±нКѕЈ¬Т»µ©ЖуТµ¶ЁЦЖБЛДЈРНЈ¬ѕН±ШРл¶ФЖдЅшРРЖА№АЎЈЛэЦёіцЈ¬ХвХэКЗТ»Р©їН»§ПЭИлА§ѕіµДµШ·ЅЎЈЛэМбµЅБЛЛэґУїН»§ДЗАпМэµЅµДТ»Р©»°Јє“‘ОТµДДЈРНЧцµГФхГґСщЈїОТЦ»КЗ¶ЁЦЖБЛЛьЎЈЛьДЬЧцОТРиТЄµДКВЗйВрЈї’ТтґЛЈ¬NeMoОЄїН»§МṩБЛ¶аЦЦЖА№А·ЅКЅЈ¬іэБЛС§Кх»щЧјЈ¬Дг»№їЙТФЙПґ«ЧФјєµДЧФ¶ЁТеЖА№А»щЧјЈ¬їЙТФБ¬ЅУµЅµЪИэ·ЅИЛ№¤ЖА№АХЯЙъМ¬ПµНіЈ¬»№їЙТФК№УГґуРНУпСФДЈРНАґЅшРРЖАЕРЎЈ”
РРТµІЙУГ
ХэИзBriskФЪјт±ЁЦРЦёіцµДДЗСщЈ¬УРјёјТ№«ЛѕХэФЪК№УГAI FoundryЈ¬°ьАЁAmdocsЎўCapital OneєНServiceNowЎЈѕЭNvidiaіЖЈ¬ХвИэјТі§ЙМХэФЪЅ«AI FoundryјЇіЙµЅЛыГЗµД№¤ЧчБчіМЦРЈ¬¶шЗТЛыГЗНЁ№эїЄ·ўЅбєПРРТµМШ¶ЁЦЄК¶µД¶ЁЦЖДЈРН»сµГБЛѕєХщУЕКЖЎЈ
Nvidia NIMµДУЕКЖ
NvidiaµДNIMѕЯУРBriskiМбј°µДТ»Р©¶АМШУЕКЖЎЈ
ЛэЅвКНЛµЈє“NIMКЗТ»ёцНЁ№э±кЧјAPI·ГОКµД¶ЁЦЖДЈРНєНИЭЖчЈ¬ХвКЗОТГЗ¶аД깤ЧчєНСРѕїµДіЙ№ыЎЈ”ЛэФЪNvidia№¤ЧчБЛ°ЛДкК±јдЈ¬ЖЪјдNvidiaТІТ»Ц±ФЪСРѕїЛьЎЈ
“ЛьКЗ»щУЪФЖФЙъ¶СХ»µДЈ¬їЙТФФЪИОєОGPUЙПїЄПдјґУГЈ¬ЖдЦРєёЗБЛОТГЗ1ТЪ¶аМЁNvidia GPUµД°ІЧ°»щКэЎЈУРБЛNIMЈ¬ДгѕНїЙТФ·ЗіЈїмЛЩµШ¶ЁЦЖєНМнјУДЈРНЎЈ”
ЛэІ№ідЛµЈ¬NIMПЦФЪЦ§іЦLlama 3.1Ј¬°ьАЁLlama 3.1 8B NIMЈЁµҐGPUґуРНУпСФДЈРНЈ©ЎўLlama 3.1 70B NIMЈЁУГУЪёЯѕ«¶ИЙъіЙЈ©єНLlama 3.1 405B NIMЈЁУГУЪєПіЙКэѕЭЙъіЙЈ©ЎЈ
ІїКр¶ЁЦЖµДґуРНУпСФДЈРН
ґЛНвЈ¬°ЈЙХЬРыІјУлNvidiaєПЧчїЄ·ўAI RefineryїтјЬЈ¬ёГїтјЬКЗФЛРРФЪAI FoundryЙПµДЎЈ°ЈЙХЬ±нКѕЈ¬ёГїтјЬНЖ¶ЇБЛЖуТµј¶AIБмУтµД·ўХ№ЎЈёГїтјЬјЇіЙФЪ°ЈЙХЬµД»щґЎДЈРН·юОсЦРЈ¬іРЕµ°пЦъЖуТµїЄ·ўєНІїКрёщѕЭЖдРиЗуБїЙн¶ЁЦЖµДґуРНУпСФДЈРНЎЈѕЭБЅјТ№«ЛѕіЖЈ¬ХвёцїтјЬ°ьАЁБЛЛДёц№ШјьТЄЛШЈє
- БмУтЅЪµг¶ЁЦЖєНЕаСµЈєХвК№ЖуТµДЬ№»К№УГЧФјєµДКэѕЭєНБчіМАґНкЙЖґуРНУпСФДЈРНЈ¬ґУ¶шМбёЯДЈРН¶ФМШ¶ЁТµОсРиЗуµДПа№ШРФєНјЫЦµЎЈ¶ЁЦЖІїГЕКЗФЛРРФЪAI FoundryЙПµДЈ¬ИГДЈРНСµБ·±дµГЗїґу¶шёЯР§ЎЈ
- Switchboard PlatformЈєК№УГ»§ДЬ№»ёщѕЭМШ¶ЁµДТµОс»·ѕі»т±кЧјЈЁАэИзіЙ±ѕєНЧјИ·РФЈ©СЎФсєНЧйєПДЈРНЎЈ
- Enterprise Cognitive BrainЈєёГЧйјю»бЙЁГиєНКёБї»ЇЖуТµКэѕЭєНЦЄК¶Ј¬ґґЅЁТ»ёцЖуТµ·¶О§µДЛчТэЈ¬ТФФцЗїЙъіЙКЅAIПµНіµДДЬБ¦ЎЈ
- ґъАнјЬ№№ЈєёГјЬ№№ЦјФЪК№AIПµНіДЬ№»ЧФЦчФЛРРЈ¬Ц§іЦёєФрИОµДAIРРОЄЈ¬Н¬К±ЧоґуПЮ¶ИµШјхЙЩИЛ№¤ја¶ЅЎЈ
ХЅВФЦШТЄРФєНУ°Пм
°ЈЙХЬµДAI RefineryїтјЬУР»ъ»бёД±дЖуТµЦ°ДЬЈ¬ґУУЄПъїЄКјЈ¬И»єуА©Х№µЅЖдЛыБмУтЈ¬ДЬ№»їмЛЩґґЅЁєНІїКрХл¶ФМШ¶ЁТµОсРиЗуµДЙъіЙКЅAIУ¦УГЈ¬ХГПФБЛ°ЈЙХЬ¶ФґґРВєНЧЄРНµДіРЕµЎЈФЪПтїН»§МṩїтјЬЦ®З°Ј¬°ЈЙХЬДЪІїУ¦УГБЛёГїтјЬЈ¬Х№КѕБЛЛьЛщїґµЅµДЗ±Б¦ЎЈ
ЦШЛЬЖуТµ
°ЈЙХЬ¶КВі¤јжКЧПЇЦґРР№ЩJulie SweetФЪ№«ёжЦРЗїµчБЛЙъіЙКЅAIФЪЦШЛЬЖуТµ·ЅГжµД±дёпЗ±Б¦Ј¬ЗїµчБЛІїКрУЙ¶ЁЦЖДЈРНЗэ¶ЇµДУ¦УГТФВъЧгТµОсУЕПИј¶єННЖ¶ЇИ«РРТµґґРВµДЦШТЄРФЎЈ
ґЛНвЈ¬Nvidia№«ЛѕґґКјИЛЎўКЧПЇЦґРР№Щ»ЖИКС«ЦёіцЈ¬°ЈЙХЬµДAI RefineryЅ«Мṩ±ШТЄµДЧЁТµЦЄК¶єНЧКФґЈ¬°пЦъЖуТµґґЅЁ¶ЁЦЖµДLlamaґуРНУпСФДЈРНЎЈ
ЧоєуµДТ»Р©Пл·Ё
°ЈЙХЬНЖіцµДAI RefineryїтјЬїЙДЬ¶ФЖуТµІЙУГєНІїКрЙъіЙКЅAIЦБ№ШЦШТЄЎЈНЁ№эІЙУГBriskiФЪјт±ЁЦРґујУФЮЙНµДLlama 3.1ДЈРНєНAI FoundryµД№¦ДЬЈ¬°ЈЙХЬК№ЖуТµДЬ№»ґґЅЁёЯ¶И¶ЁЦЖЗТУРР§µДAIЅвѕц·Ѕ°ёЎЈ
ЛжЧЕЖуТµјМРшМЅЛчЙъіЙКЅAIµДЗ±Б¦Ј¬°ЈЙХЬAI RefineryµИїтјЬЅ«ФЪКµПЦ¶ЁЦЖЗТУРР§µДAIЅвѕц·Ѕ°ё·ЅГж·ў»У№ШјьµДЧчУГЎЈ
°ЈЙХЬУлNvidiaЦ®јдµДєПЧчУРНыНЖ¶ЇAIјјКхµДЅшТ»ІЅ·ўХ№Ј¬ОЄЖуТµМṩФці¤єНґґРВµДНѕѕ¶Ј¬ТІЗїµчБЛЛщУРAIµАВ·¶јНЁПтNvidiaЎЈ
єГОДХВЈ¬РиТЄДгµД№ДАш


јУДГґу±ЈПХ№«ЛѕManulifeИзєОАыУГAIёіДЬПъКЫєНєфЅРЦРРДґъАн
Manulife№«ЛѕµДAIХЅВФТФ»Эј°¶аёцКРіЎµД№ШјьУГАэОЄЦРРДЈ¬ЖдЦРТ»ёцЦчТЄЦШµгКЗПъКЫґъАнЦ§іЦЎЈЛжЧЕґъАнµДїН»§ЧйєПІ»¶ПФці¤Ј¬ЛыГЗФЅАґФЅДСТФёъЧЩёцИЛРиЗуєНЖ«єГЎЈ

ОЄМжґъVMwareЧцЧј±ёЈ¬VeeamПтXCP-NGїЄ·ЕЦ§іЦІвКФ
КэѕЭ№ЬАн№©У¦ЙМVeeamёХёХ·ўІјБЛХл¶ФїЄФґVMwareМжґъ·Ѕ°ёProxmoxµДИнјю°ж±ѕЈ¬Н¬К±їЄ·ўіцТ»МЧФРН№¤ѕЯАґ¶ҐМжБнТ»їоРйДв»ЇЖЅМЁЈ¬јґ»щУЪXen ServerµД·ЦІжXCP-NGЎЈ

Йо¶ИЖКОцЈєБДБДУўМШ¶ыУлAMDёчЧФІ»Н¬µДCPUХыєПЛјВ·
Т»·ЅКЗEpycЈ¬Т»·ЅКЗЦБЗїЈ¬єЛРДФЅ¶аЎў¶ФУ¦µДРѕЖ¬ѕНФЅ¶аЈ¬¶шЗТєуРшІъЖ·ЙијЖЦ»»бФЅАґФЅёґФУЎЈ

ЙПєЈAI LabМбіцTimeSuiteЈєЅвЛшMLLMі¤КУЖµАнЅвµДЗ±Б¦ЈЎ
¶аДЈМ¬ґуРНУпСФДЈРНЈЁMLLMsЈ©НЁ№эЧсСТ»°гµДИЛАаЦёБоАґЅвКНКУѕхДЪИЭЈ¬ТСѕХ№КѕБЛБоИЛУЎПуЙоїМµДКУЖµАнЅвРФДЬЎЈИ»¶шЈ¬ХвР©MLLMsФЪ
2024
07/26
12:55
·ЦПн
µгФЮ

АЧѕь№«ІјРЎГЧЖыіµЕ¦±±іЙјЁЈє6·Ц46Гл874ЈЎµЗ¶ҐЎ°Е¦±±И«ЗтЧоЛЩЛДГЕіµЎ±
ВмТПКэїЖ CTO НхО¬ЈєёьєГµДНЁУГ AGI ИФФЪВ·ЙПЈ¬AI ШЅґэМбЙэЧЁТµРФєНїЙРЕРФ
2024ДкЦР№ъITУГ»§ВъТв¶ИµчСРЅб№ы№«Іј
јУДГґу±ЈПХ№«ЛѕManulifeИзєОАыУГAIёіДЬПъКЫєНєфЅРЦРРДґъАн
Gartner·ўІј2024ДкЦР№ъ°ІИ«јјКхіЙКм¶ИЗъПЯ
ОЄМжґъVMwareЧцЧј±ёЈ¬VeeamПтXCP-NGїЄ·ЕЦ§іЦІвКФ
ОўИнЎ°°ІИ«ОґАґі«ТйЎ±ЈєИ«ГжКШ»¤КэЧЦКАЅз
Йо¶ИЖКОцЈєБДБДУўМШ¶ыУлAMDёчЧФІ»Н¬µДCPUХыєПЛјВ·
ЙПєЈAI LabМбіцTimeSuiteЈєЅвЛшMLLMі¤КУЖµАнЅвµДЗ±Б¦ЈЎ
ёЯНЁЦШ°х·ўІјЈЎЧоРВжзБъЦБЧр°жЖыіµЖЅМЁББПај°ХЅВФЦШµг
ВмТПКэїЖФЪёЫјУЧўRWAТµОсЈ¬ Ў°БЅБґТ»ЗЕЎ±ЖЅМЁББПаЅрИЪїЖјјЦЬ
І»ј±УЪЗуіЙµДАЧДсґґРВЈ¬ПлФміцЎ°ДкЗбИЛµДµЪТ»МЁARСЫѕµЎ±
NVIDIAРыІјПтOCP№±ПЧBlackwell GPUЖЅМЁЙијЖ
їПоЈCloudera·ўІјёЅґшЗ¶ИлКЅNVIDIA NIMОў·юОсµДAIНЖАн·юОс
КУѕхДЬБ¦жЗГАOpenAIЈ¬Meta·ўІјLlama 3.2
КРіЎФ¤ІвЈєµЅ2032ДкAI·юОсЖчКРіЎ№жДЈЅ«Н»ЖЖ1800ТЪГАЅр
NVIDIA іхґґјУЛЩјЖ»® | 2024 NVIDIA ґґТµЖуТµХ№КѕЙоЫЪХѕФІВъКХ№Щ
NVIDIA іхґґјУЛЩјЖ»® | 2024 NVIDIA ґґТµЖуТµХ№КѕДПѕ©ХѕФІВъКХ№Щ
NVIDIA іхґґјУЛЩјЖ»® | 2024 NVIDIA ґґТµЖуТµХ№КѕТшґЁХѕФІВъКХ№Щ
·ЦОцЈєNVIDIAµЪ¶юјѕ¶ИІЖ±ЁФЩґОі¬іцФ¤ЖЪ±ієуµДРВОКМв
NVLinkєНNVSwitchКЗNvidiaФЪAIХЅХщЦРµДГШГЬОдЖч
Nvidia CEO»ЖИКС«ѕНAIµДОґАґ·ў±нБщПоґуµЁЙщГч
