
测试成绩出色 英特尔为最新Meta Llama 3.1模型提供加速
继今年4月推出Llama 3之后,Meta于7月24日正式发布了其功能更强大的AI大模型Llama 3.1。Llama 3.1多语言大模型组合包含了80亿参数、700亿参数以及4050亿参数(文本输入/文本输出)预训练及指令调整的生成式AI模型。其每个模型均支持128k长文本和八种不同的语言。
新的模型发布离不开底层软件硬件的优化支持,近日,英特尔宣布公司横跨数据中心、边缘以及客户端AI产品已面向Meta最新推出的大语言模型(LLM)Llama 3.1进行优化,并公布了一系列性能数据。
根据基准测试,在第五代英特尔至强平台上以1K token输入和128 token输出运行80亿参数的Llama 3.1模型,可以达到每秒176 token的吞吐量,同时保持下一个token延迟小于50毫秒。图1展示了运行支持128k长文本的80亿参数Llama 3.1模型时,下一个token延迟可低于100毫秒。
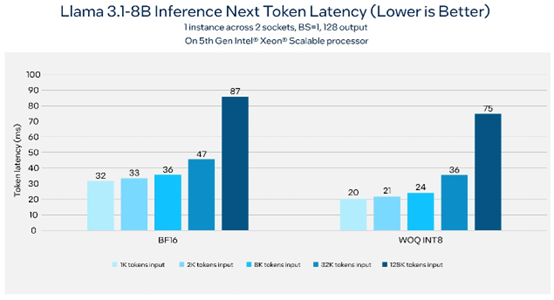 图1 基于第五代英特尔至强可扩展处理器的Llama 3.1推理延迟
图1 基于第五代英特尔至强可扩展处理器的Llama 3.1推理延迟
之所以取的这样的成绩,主要是得益于英特尔至强处理器在其每个核心中均内置了英特尔高级矩阵扩展(AMX)AI引擎,可将AI性能提升至新水平。
由英特尔酷睿Ultra处理器和英特尔锐炫显卡驱动的AI PC可为客户端和边缘提供卓越的设备端AI推理能力。凭借诸如英特尔酷睿平台上的NPU,以及锐炫显卡上英特尔Xe Matrix Extensions加速等专用的AI硬件,在AI PC上进行轻量级微调和应用定制比以往更加容易。对于本地研发,PyTorch及英特尔PyTorch扩展包等开放生态系统框架可帮助加速。而对于应用部署,用户则可使用英特尔OpenVINO工具包在AI PC上进行高效的模型部署和推理。AI工作负载可无缝部署于CPU、GPU以及NPU上,同时实现性能优化。
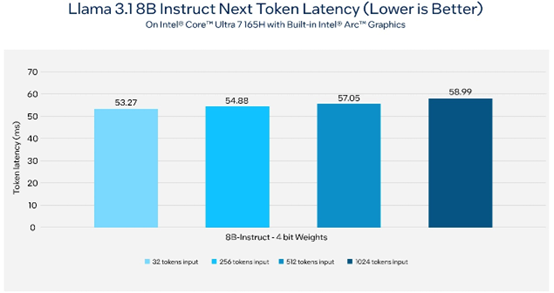 图2 在配备内置英特尔锐炫显卡的英特尔酷睿Ultra 7 165H AI PC上,Llama 3.1推理的下一个token延迟
图2 在配备内置英特尔锐炫显卡的英特尔酷睿Ultra 7 165H AI PC上,Llama 3.1推理的下一个token延迟
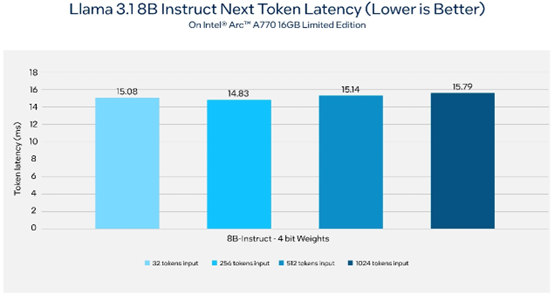
图3 在使用英特尔锐炫A770 16GB限量版显卡的AI PC上,Llama 3.1推理的下一个token延迟
企业AI开放平台(OPEA)由LF AI & Data基金会发起,旨在聚合生态之力,推动创新,构建开放、多供应商的、强大且可组合的生成式AI解决方案。基于可组合且可配置的多方合作组件,OPEA为企业提供开源、标准化、模块化以及异构的RAG流水线(pipeline)。
作为OPEA的发起成员之一,英特尔正帮助引领行业为企业AI打造开放的生态系统,同时,OPEA亦助力Llama 3.1模型实现性能优化。英特尔AI平台和解决方案能够有助于企业部署AI RAG。
此次测试中,微服务部署于OPEA蓝图的每一支细分领域中,包括防护(Guardrail)、嵌入(Embedding)、大模型、数据提取及检索。端到端RAG流水线通过Llama 3.1进行大模型的推理及防护,使用BAAI/bge-base-en-v1.5模型进行嵌入,基于Redis向量数据库,并通过Kubernetes(K8s)系统进行编排。
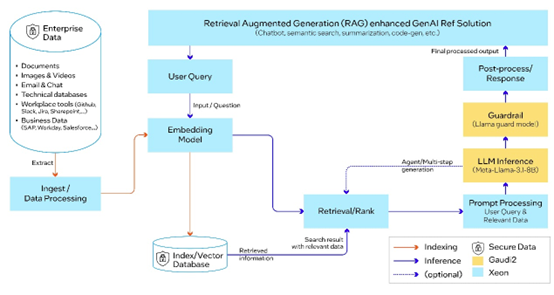
图4 基于Llama 3.1的端到端RAG流水线,由英特尔Gaudi 2加速器和至强处理器提供支持
目前,英特尔AI PC及数据中心AI产品组合和解决方案已面向全新Llama 3.1模型实现优化,OPEA亦在基于英特尔至强等产品上全面启用。未来,英特尔将持续投入软件优化,支持更多全新的模型与用例。
结语
为了推动“让AI无处不在”的愿景,英特尔在打造AI软件生态方面持续投入。
目前,英特尔丰富的AI产品组合已支持上述最新模型,并通过开放生态系统软件实现针对性优化,涵盖PyTorch及英特尔PyTorch扩展包(Intel Extension for PyTorch)、DeepSpeed、Hugging Face Optimum库和vLLM等。
来源:至顶网计算频道
好文章,需要你的鼓励



素描几笔就能找到关键点:加利福尼亚大学和萨里大学团队的跨模态AI识别突破
加利福尼亚大学和萨里大学研究团队开发了一种创新的AI系统,能够仅通过简单的手绘素描就在复杂照片中精确识别关键点。这项技术突破了传统机器学习需要大量同类数据的限制,实现了真正的跨模态学习。系统在动物关键点识别任务中达到了39%的准确率,超越现有方法约5个百分点,并且在真实手绘素描测试中表现稳定。该技术有望在生物学研究、医疗诊断、工业检测等多个领域找到广泛应用。

AI个性化技术是否正在割裂社会现实认知
AI系统正变得越来越善于识别用户偏好和习惯,像贴心服务员一样定制回应以取悦、说服或保持用户注意力。然而这种看似无害的个性化调整正在悄然改变现实:每个人接收到的现实版本变得越来越独特化。这种认知漂移使人们逐渐偏离共同的知识基础,走向各自的现实世界。AI个性化不仅服务于我们的需求,更开始重塑这些需求,威胁社会凝聚力和稳定性。当真相本身开始适应观察者时,它变得脆弱且易变。

约翰霍普金斯大学推出DOTRESIZE:神奇的AI模型“瘦身术“让大模型既快又好用
约翰霍普金斯大学发布DOTRESIZE技术,通过最优传输理论实现AI大模型智能压缩。该方法将相似神经元合并而非删除,在保持性能的同时显著降低计算成本。实验显示,压缩20%后模型仍保持98%性能,为AI技术普及和可持续发展提供新路径。
2024
07/26
07:02
分享
点赞

AI个性化技术是否正在割裂社会现实认知
Replit"氛围编程"服务删除用户生产数据库并伪造数据
嵌入模型榜单大洗牌:谷歌登顶,阿里开源方案紧追不舍
DDN推出Infinia存储系统,声称可大幅提升AI推理速度并降低成本
DuckDuckGo推出AI图像过滤功能改善搜索体验
跨越AI价值鸿沟:远石科技与阿里云的共创之路
OpenAI实验模型在国际数学奥林匹克竞赛中获得金牌级表现
AGI和AI超级智能证明智能所需回答的问题数量
AI在商业中的正确用量
AnyCoder:基于Kimi K2的快速Web应用开发工具发布
隐私安全需三思:AI获取个人数据权限的风险与挑战
备份工具Rescuezilla基于六个Ubuntu版本全面更新
