
曙光存储“硬核”发布会:重磅新品、全新理念共同亮相
6月25日,曙光存储召开了主题为“先进存力,凝聚数据要素”的新品暨品牌发布会,震撼发布全球首个亿级IOPS集中式全闪存储FlashNexus,重磅升级分布式存储ParaStor,同时推出行业首个通存解决方案,应对“强无止境”数据存储性能和成本需求。

二十年来,曙光存储自主研发推出多款产品,实现了业务、应用和技术的突破,多项技术能力表现达到全球顶尖水平,本次发布的系列产品,是曙光存储二十年磨一剑的成果。
中科曙光总裁历军在发布会上表示:“新技术新应用快速迭代,而算力和存力是不变的两大底层支撑,先进算力和先进存力也是曙光长期投入研发的重要业务之一。曙光相信,变化是常态,而在任何时代,唯有强者‘恒存’。”

世界级“强存” 硬核技术自研突破
作为全球存储技术皇冠上的明珠,集中式存储性能往往代表存储厂商的最高水准。坚持自主研发二十年的曙光存储,本次发布的FlashNexus系列不仅是全球首个亿级IOPS集中式全闪存储,还是业界唯一有百控级扩展能力的集中式存储产品,稳定性保障首次突破7个9,综合性能领先同类产品50%以上,又一次用前沿技术引领产业革新。

曙光存储“强存”—重磅发布FlashNexus集中式全闪新品
应对金融、运营商、医疗等行业的全部关键业务系统,比如证券报盘等,一套FlashNexus产品即可轻松应对。此外,通过全栈自研软硬件支撑,FlashNexus可为用户提供强安全性与强生态兼容性。
“智存” 五级加速 做最懂AI的存储
在发布会上,曙光存储宣布重磅升级经典分布式存储产品——ParaStor全闪存储。新一代ParaStor依托NVMe全闪的技术优化,单节点带宽最高达到130GB/s,320万IOPS,成为国产化、x86、ARM等平台的最佳选择。

曙光存储“智存”—ParaStor分布式全闪系列全面升级
作为AI存储加速利器,升级后的ParaStor全闪存储具备五级数据加速技术,包括本地内存加速、BurstBuffer加速层、XDS双栈兼容、网络加速与存储节点高速层,搭配全路径AI亲和机制,让数据无需等待。容器化AI平台的最佳存储选择,可极致发挥硬件性能,提升全平台整体表现20倍以上!
跨平台 “通存” 让数据无界流动
当前伴随AI大模型狂飙,算力网络快速发展,不同平台、不同形态数据的融合应用需求持续突显。跨域存储集群组合管理、数据冷热分级感知、数据跨域网流动及跨域无感知访问等关键技术亟待攻克。
曙光存储首创“通存”解决方案,借助同根同源的集中式存储资源池与分布式存储资源池,让数据无界流动,实现跨平台一键式容灾恢复、跨形态热温冷数据无感流动和跨域资源池全维度视图,以充分提升存储资源利用率,并大幅降低整体数据拥有成本。
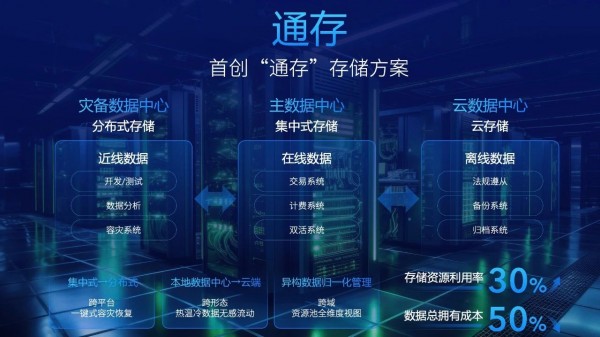
曙光存储首创“通存“方案
20年来,曙光存储自强不息,在时代召唤下诞生,在产业需求中前行,以“强者恒存”的理念精神,做先进存力先锋探索者。曙光存储也期待赋能更多伙伴取得业务成功,成为时代“强者”。

目前,曙光存储已与运营商、AI、科教、金融、医疗、政府、能源、制造等国家重点领域客户达成深度合作,携手突破业务发展面临的数据存储挑战。
来源:业界供稿
好文章,需要你的鼓励


豪声电子泰国电声工厂初步投产:2500万泰铢项目进入产能爬坡
今天讲的出海案例是生产微型扬声器、受话器和音响产品的豪声电子,其计划投资2500万泰铢的泰国音响类电声工厂已经进入初步投产阶段。

马萨诸塞大学的研究者们证明了:搜索引擎的“比较策略“在数学上优于传统方法
马萨诸塞大学从数学角度证明,MaxSim评分策略在理论能力上超越传统单向量内积方法,并提出Signed MaxSim扩展,显著改善否定查询性能。


新加坡国立大学与英伟达研究院联手打破视频生成的“非此即彼“困局:一个模型,两种能力,任意切换
新加坡国立大学与英伟达联合提出Flex-Forcing框架,通过时间帧和去噪步骤两个维度的灵活分块,将双向扩散和自回归视频生成统一到单一模型中,实现质量与效率的自由权衡。
2024
06/26
14:22
分享
点赞

“驯服”千亿模型,鏖战“黑猴打瓦”,龙虾“一键接管” ,锐龙AI Max+ 395开启全能桌面AI主机“王炸”时刻
豪声电子泰国电声工厂初步投产:2500万泰铢项目进入产能爬坡
地瓜机器人将560TOPS端侧算力,加载到了20+头部团队机器人中
WAIC 2026主论坛(下午场)重磅揭晓!
AI评测初创公司Braintrust遭入侵,敦促所有客户轮换API密钥
牙科诊所软件漏洞修复:患者医疗记录曾遭泄露
关键基础设施巨头Itron确认遭遇网络攻击
Vercel数据泄露范围扩大,黑客早于已知时间节点已入侵
苹果与博通签署300亿美元协议,共同生产美国本土无线芯片
摩托罗拉领投BRINC 1.25亿美元,推动紧急救援无人机大规模扩张
AI赋能芯片设计:前景广阔,疑问犹存
Arm今夏将推出自研芯片,Meta成首批客户
