
测试结果喜人 英特尔多样化硬件针对阿里云通义千问2模型进行优化
作为阿里自研大模型,千亿级参数规模的通义千问2.0在10个权威测评中全面超越GPT-3.5和Llama2,加速追赶GPT-4。
而通义千问2.0的良好表现离不开底层算力基础设施的支持,在这方面英特尔与阿里展开了积极合作。
为了最大限度地提升诸如阿里云通义千问2的大模型效率,全面的软件优化非常重要,其中包括从高性能融合算子到平衡精度和速度的先进量化技术。此外,英特尔还采用KV Caching、PagedAttention机制和张量并行来提高推理效率。英特尔的硬件可利用软件框架和工具包进行加速,并获得出色的大模型推理性能,其中包括PyTorch和英特尔 PyTorch扩展包、OpenVINO工具包、DeepSpeed、Hugging Face库和vLLM。
测试结果:英特尔® Gaudi AI加速器
英特尔Gaudi AI加速器专为生成式AI以及大模型的高性能加速而设计。使用最新版本的英特尔Gaudi Optimum,可以轻松部署新型号的大模型。在英特尔Gaudi 2上对70亿参数和720亿参数的通义千问2模型的推理和微调吞吐量进行了基准测试,以下为详细性能指标和测试结果。
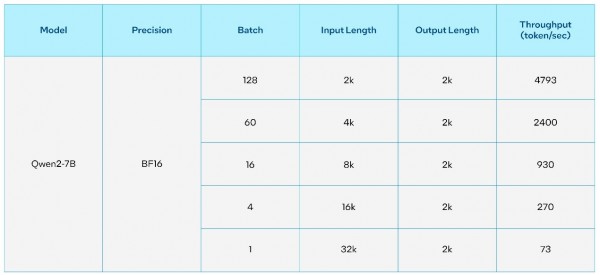
表1. 70亿参数的通义千问2在单颗英特尔Gaudi 2加速器上的推理
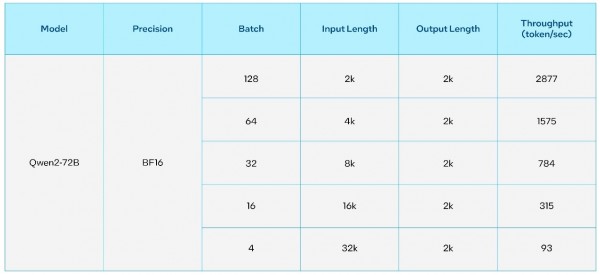
表2. 720亿参数的通义千问2在8颗英特尔Gaudi 2加速器上的推理
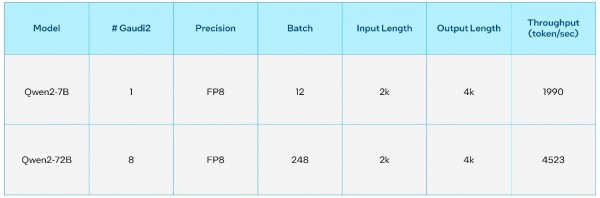
表3. 通义千问2 FP8在英特尔Gaudi 2加速器上的推理
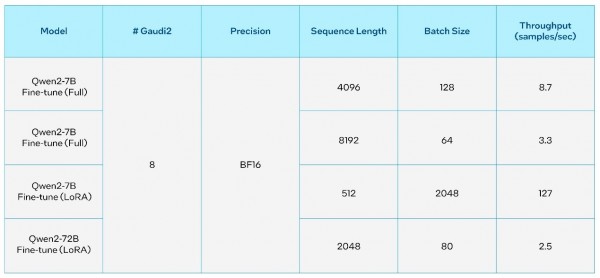
表4. 通义千问2在英特尔Gaudi 2加速器上的微调
测试结果:英特尔®至强®处理器
英特尔®至强®处理器作为通用计算的基石,为全球范围内的用户提供强大的算力。英特尔至强处理器具有广泛可用性,适用于各个规模的数据中心,这使其成为那些希望能够快速部署AI解决方案,又无需配备专项基础设施企业的理想选择。英特尔至强处理器的每个核心均内置了英特尔®高级矩阵扩展(英特尔AMX),可处理多样化的AI工作负载并加速AI推理。下图展现了英特尔至强处理器所提供的延迟性能可满足多种用例。
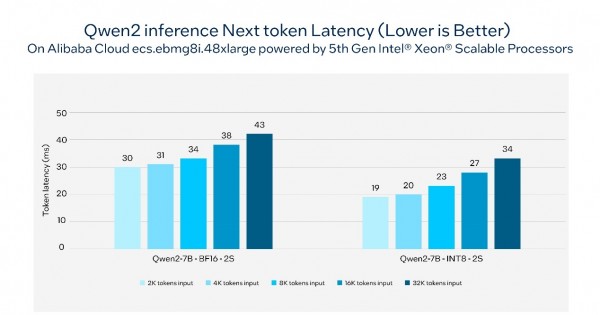
图1. 在基于第五代英特尔®至强®可扩展处理器的阿里云ecs.ebmg8i.48xlarge实例上,通义千问2的下一个推理token延迟
AI PC
由最新英特尔®酷睿™ Ultra处理器和英特尔锐炫™显卡驱动的AI PC让AI的力量触及客户端和边缘,使开发者在本地也能部署大模型。AI PC配备了专门的AI硬件,如神经处理单元和内置的英特尔锐炫™显卡,或配备了英特尔® Xe Matrix Extensions加速的英特尔锐炫™ A系列显卡,以处理高需求的边缘AI任务。这种本地处理能力可实现个性化的AI体验,增强隐私性,并提供快速响应时间,这对于交互式应用程序至关重要。
以下展示了15亿参数的通义千问2,在基于英特尔®酷睿™ Ultra的AI PC上运行时所展现的强大性能。
Demo 1. 在内置英特尔锐炫™显卡的英特尔®酷睿™ Ultra 7 165H上,通义千问2的推理
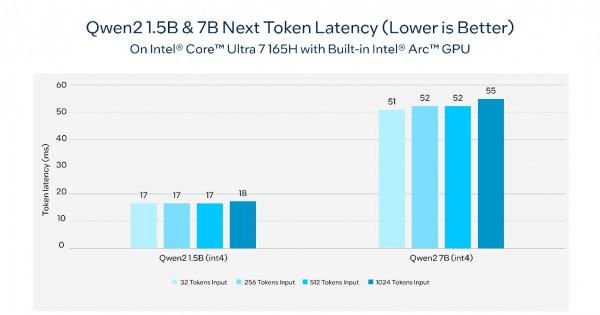
表2. 在内置英特尔锐炫™显卡的英特尔®酷睿™ Ultra 7 165H AI PC上,通义千问2的下一个token延迟
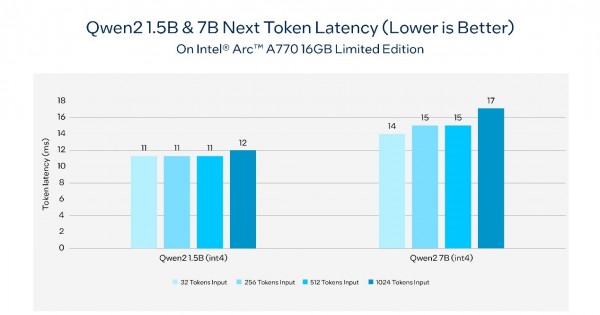
表3. 在由英特尔锐炫™ A770 16GB限量版驱动的AI PC上,通义千问2的下一个token延迟
从上述测试结果表现看,双方的合作成果还是很显著的,这加速了大模型的落地。
英特尔与阿里云在数据中心、客户端以及边缘平台上的AI软件优化,有助于构建一个创新的生态环境,且截至目前,已取得了包括ModelScope、阿里云PAI、OpenVINO等在内的诸多创新成果。得益于此,阿里云AI模型可在多样化的计算环境中进行优化。
来源:至顶网计算频道
好文章,需要你的鼓励


浙江大学推出动态场景重建的新方法——FreeTimeGS,知名KOL:这就是未来Midjourney要实现的效果
浙江大学与吉利汽车研究院提出了一个叫做FreeTimeGS的新方法,通过一种全新的思路给予高斯基元"自由",让它们能够在任意时间和位置出现,从而更好地重建具有复杂动作的动态场景。

当AI遇上癌症诊断:上海交大团队如何让机器“看懂“细胞的秘密
上海交通大学研究团队开发出革命性AI癌症诊断系统,通过深度学习技术分析50万张细胞图像,实现94.2%的诊断准确率,诊断时间从30分钟缩短至2分钟。该系统不仅能识别多种癌症类型,还具备解释性功能,已在多家医院试点应用。研究成果发表于《Nature Communications》,展示了AI在精准医疗领域的巨大潜力。

巴克莱为 100,000 名员工推出 Microsoft Copilot,AI 采用持续加速
巴克莱银行与 Microsoft 签订协议,将 Copilot 集成到内部生产力工具中,为全球 10 万员工打造一站式 AI 平台,提升工作效率。

机器人学会3D“变身术“:南华理工大学让机器人像人类一样理解物体运动
南华理工大学等机构提出3DFlowAction方法,让机器人通过预测物体3D运动轨迹来学习操作技能。该研究创建了包含11万个实例的ManiFlow-110k数据集,构建了能预测三维光流的世界模型,实现了跨机器人平台的技能迁移。在四个复杂操作任务上成功率达70%,无需特定硬件训练即可在不同机器人上部署,为通用机器人操作技术发展开辟新路径。
2024
06/11
18:18
分享
点赞

浙江大学推出动态场景重建的新方法——FreeTimeGS,知名KOL:这就是未来Midjourney要实现的效果
爱簿智能推出E300 AI计算模组:50TOPS国产算力,赋能边缘AI全场景高效部署
从愿景到现实 聚焦生成式AI全球实践 2025亚马逊云科技中国峰会将于6月19日在上海开幕
访谈:Pega 的 “Blueprint” 破解老旧 IT 的诅咒
巴克莱为 100,000 名员工推出 Microsoft Copilot,AI 采用持续加速
‘严重’网络中断全球损失达1600亿美元
Microsoft 为 Xbox 掌机精简 Windows 11 繁琐部分
Guardz 获得 5600 万美元融资,为小型企业带来企业级网络安全保护
WWDC 2025:全部发布内容,包括 Liquid Glass、Apple Intelligence 更新及更多
macOS Tahoe 即将推出的新功能
Mary Meeker 的科技报告展示了 AI 采纳的步伐与广度
Superblocks CEO:如何通过研究 AI 系统提示寻找独角兽创意
