
英特尔披露至强6处理器针对Meta Llama 3模型的推理性能
近日,Meta重磅推出其80亿和700亿参数的Meta Llama 3开源大模型。该模型引入了改进推理等新功能和更多的模型尺寸,并采用全新标记器(Tokenizer),旨在提升编码语言效率并提高模型性能。
在模型发布的第一时间,英特尔即验证了Llama 3能够在包括英特尔®至强®处理器在内的丰富AI产品组合上运行,并披露了即将发布的英特尔至强6性能核处理器(代号为Granite Rapids)针对Meta Llama 3模型的推理性能。
英特尔至强处理器可以满足要求严苛的端到端AI工作负载的需求。以第五代至强处理器为例,每个核心均内置了AMX加速引擎,能够提供出色的AI推理和训练性能。截至目前,该处理器已被众多主流云服务商所采用。不仅如此,至强处理器在进行通用计算时,能够提供更低时延,并能同时处理多种工作负载。
事实上,英特尔一直在持续优化至强平台的大模型推理性能。例如,相较于Llama 2模型的软件,PyTorch及英特尔® PyTorch扩展包(Intel® Extension for PyTorch)的延迟降低了5倍。这一优化是通过Paged Attention算法和张量并行实现的,这是因为其能够最大化可用算力及内存带宽。下图展示了80亿参数的Meta Lama 3模型在AWS m7i.metal-48x实例上的推理性能,该实例基于第四代英特尔至强可扩展处理器。
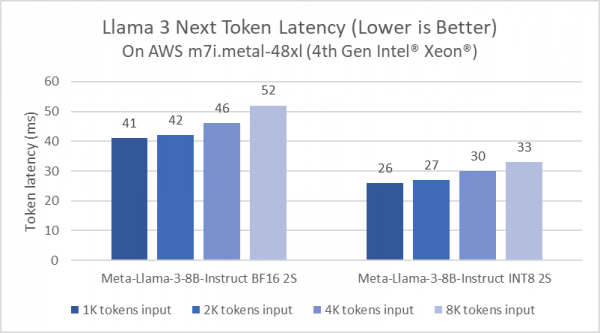
图1:AWS实例上Llama 3的下一个Token延迟
不仅如此,英特尔还首次披露了即将发布的产品——英特尔®至强® 6性能核处理器(代号为Granite Rapids)针对Meta Llama 3的性能测试。结果显示,与第四代至强处理器相比,英特尔至强6处理器在80亿参数的Llama 3推理模型的延迟降低了2倍,并且能够以低于100毫秒的token延迟,在单个双路服务器上运行诸如700亿参数的Llama 3这种更大参数的推理模型。
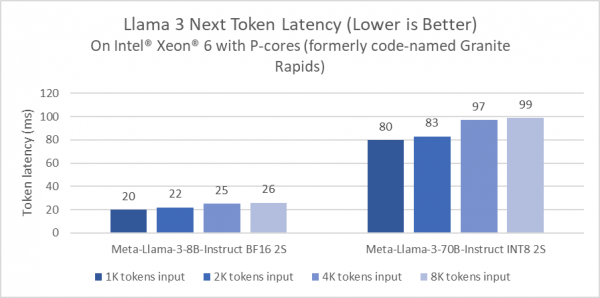
图2:基于英特尔®至强® 6性能核处理器(代号Granite Rapids)的Llama 3下一个Token延迟
考虑到Llama 3具备更高效的编码语言标记器(Tokenizer),测试采用了随机选择的prompt对Llama 3和Llama 2进行快速比较。在prompt相同的情况下,Llama 3所标记的token数量相较Llama 2减少18%。因此,即使80亿参数的Llama 3模型比70亿参数的Llama 2模型参数更高,在AWS m7i.metal-48xl实例上运行BF16推理时,整体prompt的推理时延几乎相同(该评估中,Llama 3比Llama 2快1.04倍)。
开发者可在此查阅在英特尔至强平台上运行Llama 3的说明。
产品和性能信息
英特尔至强处理器:
在英特尔®至强® 6处理器(此前代号Granite Rapids)上进行测试,使用2个英特尔®至强® Platinum,120核,超线程开启,睿频开启,NUMA 6,集成加速器可用[已使用]:DLB[8],DSA[8],IAA[8],QAT[8],总内存1536GB(24x64GB DDR5 8800 MT/s[8800 MT/s]),BIOS BHSDCRB1.IPC.0031.D44.2403292312,微码0x810001d0,1x以太网控制器I210千兆网络连接1x SSK存储953.9G,Red Hat Enterprise Linux 9.2(Plow),6.2.0-gn r.bkc.6.2.4.15.28.x86_64,基于英特尔2024年4月17日的测试。
在第四代英特尔®至强®可扩展处理器(此前代号Sapphire Rapids)上进行测试,使用AWS m7i.metal-48xl实例,2个英特尔®至强® Platinum 8488C,48核,超线程开启,睿频开启,NUMA 2,集成加速器可用[已使用]:DLB[8],DSA[8],IAA[8],QAT[8],总内存768GB(16x32GB DDR5 4800 MT/s[4400 MT/s]);(16x16GB DDR5 4800 MT/s[4400 MT/s]),BIOS亚马逊EC2,微码0x2b0000590,1x以太网控制器弹性网络适配器(ENA)亚马逊弹性块存储(EBS)256G,Ubuntu 22.04.4 LTS,6.5.0-1016-ws,基于英特尔2024年4月17日的测试。
来源:业界供稿
好文章,需要你的鼓励


Google力推手机AI功能引发关注
继苹果和其他厂商之后,Google正在加大力度推广其在智能手机上的人工智能功能。该公司试图通过展示AI在移动设备上的实用性和创新性来吸引消费者关注,希望说服用户相信手机AI功能的价值。Google面临的挑战是如何让消费者真正体验到AI带来的便利,并将这些技术优势转化为市场竞争力。

麻省理工学院发现LLM“幻觉“新根源:注意力机制竟然会自相矛盾
麻省理工学院研究团队发现大语言模型"幻觉"现象的新根源:注意力机制存在固有缺陷。研究通过理论分析和实验证明,即使在理想条件下,注意力机制在处理多步推理任务时也会出现系统性错误。这一发现挑战了仅通过扩大模型规模就能解决所有问题的观点,为未来AI架构发展指明新方向,提醒用户在复杂推理任务中谨慎使用AI工具。

Meta发布AI翻译功能,支持脸书和Instagram内容实时转换
Meta为Facebook和Instagram推出全新AI翻译工具,可实时将用户生成内容转换为其他语言。该功能在2024年Meta Connect大会上宣布,旨在打破语言壁垒,让视频和短视频内容触达更广泛的国际受众。目前支持英语和西班牙语互译,后续将增加更多语言。创作者还可使用AI唇形同步功能,创造无缝的口型匹配效果,并可通过创作者控制面板随时关闭该功能。

中科院团队构建史上最大多模态AI对齐数据集:让机器真正读懂人类偏好的秘密武器
中科院自动化所等机构联合发布MM-RLHF研究,构建了史上最大的多模态AI对齐数据集,包含12万个精细人工标注样本。研究提出批评式奖励模型和动态奖励缩放算法,显著提升多模态AI的安全性和对话能力,为构建真正符合人类价值观的AI系统提供了突破性解决方案。
2024
04/22
09:40
分享
点赞

“4个9”韧性的背后,西云数据以技术与运营加速企业数字化创新
Google力推手机AI功能引发关注
Meta发布AI翻译功能,支持脸书和Instagram内容实时转换
HPE发布Nvidia Blackwell驱动的AI服务器,抢占AI市场需求
ISACA推出AI安全管理高级认证项目
谷歌推出智能体SOC系统提升安全事件响应速度
Lumen升级400GB数据中心连接基础设施助力AI发展
AI和流媒体推动,2030年面临"网络危机"
Pine64停产Pro手机转向RISC-V业务
日立Vantara将VSP One块存储扩展至Azure云平台
Finchetto光学数据包交换机:光无法存储的技术挑战与突破
Python开发者调查显示增长强劲,但基金会资金面临困境
