
分析:Gaudi 3让英特尔可以面向Pytorch群体售卖AI加速器了
我们之前已经说过了,在这里我们再说一遍:如果你能制作一个运行PyTorch框架和Llama大语言模型(两者都是开源的,都来自Meta Platforms,都被企业广泛采用)的矩阵数学引擎,那么你就可以售卖这个矩阵数学引擎了。
近日英特尔在美国菲尼克斯举行的Vision 2024活动上推出了第三代Gaudi AI加速器,英特尔在钱德勒附近拥有大型代工厂,唯一的问题是英特尔可以生产多少个Gaudi 3加速器,价格是多少,什么时候可以发货?
第一个问题只有英特尔知道,英特尔正在与台积电合作蚀刻和封装Gaudi 3加速器。Habana Labs在2019年12月被英特尔以20亿美金收购,并于2019年7月推出了Gaudi 1加速器,当时在小得离谱的AI市场中Nvidia的“Volta”V100是它的竞争对手。希望英特尔能够比Gaudi 1或者Gaudi 2更积极地制造和销售Gaudi 3芯片,即使在加速器原始性能方面它很快会远远落后于Nvidia。英特尔有机会积极争取,吸引PyTorch人群,在Hugging Face上提供Llama大型语言模型和看似无数的其他AI模型。

这足以为AI加速器业务奠定基础——前提是客户相信Gaudi 3与即将在2024年底或2025年初左右发布的“Falcon Shores”的混合CPU/NNP设计之间会有足够的架构相似性。Falcon Shores将采用HBM3内存的变体,其发布日期具体取决于你怎么解读英特尔为Gaudi系列制定的模糊路线图。我们所知道的是,Falcon Shores将把Gaudi系列和Max系列GPU合并,打造出一个既有Gaudi以太网互连和矩阵数学张量核心、又有Ponte Vecchio GPU的Xe矢量引擎的GPU。
至于Gaudi 3加速器的成本,答案很简单。英特尔的价格将与它相对应的Nvidia Hopper H100 GPU加速器的性能以及具有96 GB HBM3内存容量和3.9TB/秒带宽的Hopper H100 GPU的市场价格成正比。随着具有141 GB HBM3e内存容量和4.8TB/秒带宽的Hopper H200即将在几个月内开始发货,Gaudi 3也将转向和H200进行比较。当未来Blackwell B100和B200 GPU加速器从今年晚些时候到2025年的时候开始发货,英特尔就不得不对Gaudi 3的价格进行相应调整了。
第三代更有魅力吗?
显然,如果Gaudi 3加速器能在2022年春季与Hopper GPU一起推出,并且数量可观的话,那对英特尔来说会更好。两年过去了,市场对Nvidia GPU的需求如此强劲,没有比现在是售卖这款已经有两年历史的技术的更好时机了。现在推出总比不推出好,在这一点上,让Falcon Shores投入使用宜早不宜迟。
英特尔可以在短期内售卖自己生产的所有Gaudi 3和Falcon Shores,现在是忙碌的时候。Gaudi 3和Falcon Shores的时机本来可以更好,但任何升级上的延迟都意味着数十亿美金的系统销售被延迟,而且因为Nvidia的强劲增长以及AMD也开始凭借Antares Instinct MI300系列GPU获得关注而输掉这场比赛。
Gaudi 3加速器相对Gaudi 2来说是一大进步。但Falcon Shores带来了重大的架构变化,但很大程度上与使用PyTorch和基于该框架的更高端模型的客户是相隔离的。如果Meta Platforms选择这款Gaudi加速器作为AI引擎,这对Habana Labs和英特尔来说都将是一件好事,但显然这并没有发生,Meta正在开发自己的MTIA加速器系列用于AI训练和推理,并且临时购买了数十万个Nvidia GPU。
让我们先了解一下Gaudi 1和Gaudi 2架构,然后看看Gaudi 3加速器、使用它的系统设计、以及英特尔将推向市场的各种Gaudi 3封装,比较当前Nvidia和AMD GPU、Gaudi 3系列的性价比。
专为数学而生
与其他包含矩阵数学单元和张量核心(一种特殊的矩阵数学单元)的AI加速器一样,最初的Gaudi 1加速器理论上可用于加速其他类型的工作负载,包括高性能计算模拟和建模,甚至是数据分析,只需为其创建软件堆栈即可。但在这种情况下,与其他混合精度AI加速器的情况一样,混合(重要的是低精度)浮点和整数数学最适合于AI训练和推理了。
Habana Labs整合的Gaudi 1加速器和软件堆栈迫使英特尔收购了这家公司,尽管英特尔此已经在2016年8月以3.5亿美金收购了AI加速器制造商Nervana Systems。(英特尔直到2019年11月才将Nervana NNP产品化,然后一个月之后收购了Habana Labs。想想看。)
这是Gaudi 1的结构图:
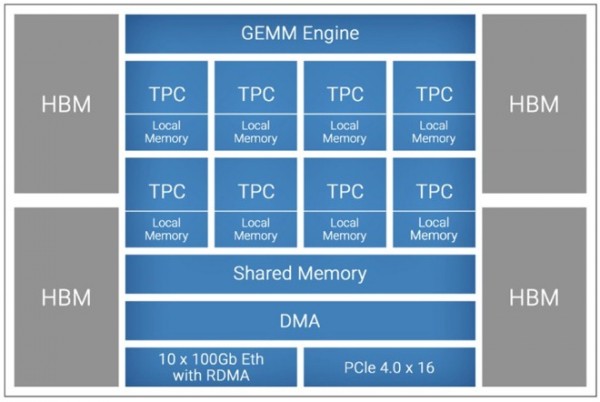
这个架构中包括了一个通用GEMM Engine矩阵数学引擎,以及8个带有自己本地内存的TPC。GEMM引擎以16位精度对全连接层、卷积和批量GEMM处理进行数学运算,而TPC是一种特殊的SIMD处理器,用于处理其他机器学习操作。TPC可以处理FP32、BF16、INT32、INT16、INT8、UINT32、UINT16和UINT8格式的数据。
TPC(可能还有GEMM单元)共享的SRAM内存容量为24 MB,带宽为1TB/秒;据我们所知,TPC上本地内存的大小和带宽从未对外公布。
Gaudi 2采用台积电的16纳米工艺蚀刻,并使用2.5D CoWoS封装来链接4个HBM2内存堆栈,每个堆栈8 GB,总共32 GB内存,聚合带宽为1TB/秒。该芯片还有10个100 Gb/秒以太网RoCE端口,用于在服务器节点内以及集群中的服务器节点之间互连Gaudi处理器,最多有128个完全连接的节点,此外还有一个PCI-Express 4.0 x16控制器来连接主机CPU。
英特尔是在2022年5月推出Gaudi 2的,2023年6月开始在Intel Developer Cloud上批量出货,英特尔内部的Habana团队全力以赴,很大程度上要归功于他们转向使用了台积电的7纳米工艺蚀刻。

共享SRAM内存从24 MB增加到48 MB。TPC的数量增加了3倍,达到24个,GEMM单元(现在称为矩阵数学引擎)的数量也增加了1倍。以太网端口数量增加了2.4倍,达到24个端口,这从根本上提高了Gaudi集群的可扩展性,并添加了媒体解码器来为AI视觉应用进行预处理。TPC支持FP32、TF32、BF16、FP16和FP8(E4M3和E5M2变体)数据格式。根据文档显示,MME单元进行矩阵数学运算并累加为FP32格式(尚不清楚GEMM是否与MME相同。但如果是,它会对16位整数进行矩阵数学计算并累加到32位浮点数)。Gaudi 2具有相同的PCI-Express 4.0 x16 链路输出到主机,但具有6个HBM2E内存控制器和6个HBM2E内存堆栈,每个堆栈为16 GB,6个堆栈总容量为96 GB,带宽为2.4 TB/秒。
这让我们想到了Gaudi 3以及转向台积电的5纳米蚀刻。
Gaudi 3加速器如下所示:

这是规格:

Gaudi 3更为强大。Habana Labs首席运营官Eitan Medina表示,TPC设计已经是第五代了,他在英特尔内部也担任同样的职务。Gaudi 3设备上有64个TPC,比Gaudi 2增加了50%。还有8个MME,是Gaudi 2的4倍。

根据Medina的说法,这是一个简化的图,但正如你现在期望的那样,有2个相同的Gaudi 3小芯片,彼此旋转180度,实现了24个200 Gb/秒以太网端口中的一般,一半的媒体引擎,并且每个图块可能有一个PCI-Express 5.0 x8端口,可以组合起来形成简化结构图中所示的单个虚拟PCI-Express 5.0 x16端口。
每个Gaudi 3块上有48 MB的SRAM共享内存,以及2个由16个TPC组成的块,以及2个由2个MME组成的块。这个Gaudi 3复合体中有96 MB的SRAM,以及12.8TB/秒的聚合带宽。有8个HBM2E内存堆栈,总容量为128 GB,带宽为3.7TB/秒。
据我们所知,Gaudi 3设备中的TPC和Gaudi 2一样支持FP32、TF32、BF16、FP16和FP8数据格式,但不像Nvidia新推出的Blackwell GPU那样支持FP4精度。Nvidia现有的Hopper GPU也不具备这种能力。
在节点内和跨集群扩展Gaudi 3
AI加速器的好坏取决于它可以构建的集群,正如从一开始那样,Gaudi团队正在将以太网与RDMA以及RoCE协议扩展中的其他无损功能集成在一起,以不使用InfiniBand的情况下做到这一点。
以下是FP8精度集群的速度,FP8有时会被用于AI训练,并且被越来越多地用于AI推理:

8路的Gaudi 3节点在FP8精度下的额定速度为14.7 petaflops,8路的Hopper H100节点在FP8精度下的额定速度为15.8 petaflops,无需打开2:1稀疏性支持。鉴于并非所有应用都会支持2:1的稀疏性,所以说这个距离就相当遥远了。(对于密集矩阵,稀疏支持不会起任何作用。)Nvidia的原始H100也只有80GB的HBM3,但带宽为3.35TB/秒。英特尔通过坚持使用更便宜的HBM2E获得了更多的容量和带宽,这一点很有趣。Nvidia的H200拥有141 GB的HBM3E和4.8TB/秒的带宽,内存容量增加了10.2%,带宽增加了29.7%。(但是价格是多少?也许比Grace CPU的成本更高?)
节点内部的Gaudi 3加速器使用了和Gaudi 2设计相同的OSFP链路连接到外部世界,但在这种情况下,速度加倍就意味着英特尔必须在Gaudi 3的以太网端口和来自系统板背面的6个800 Gb/秒OSFP端口之间添加重定时器。每个Gaudi 3上有24个端口中,有21个用于构建高带宽全对全网络,将这些Gaudi 3设备紧密连接在一起。就像这样:
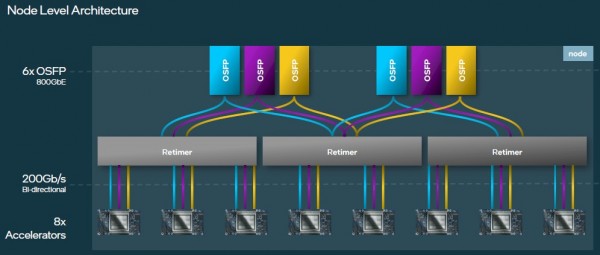
当你扩展的时候,你可以构建一个包含了16个8路Gaudi 3节点和3个叶子交换机的子集群,据Medina称,这种子集群通常基于博通的51.2Tb/秒“Tomahawk 5”StrataXGS交换机ASIC——其中,以800 GB/秒运行的64个端口,有一半的端口向下指向服务器,另一半端口向上指向主干网络。你需要3个叶开关来完成此任务:
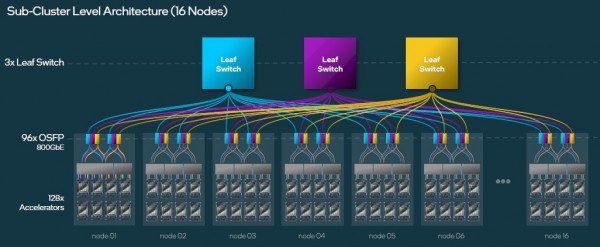
为了在512个服务器节点上获得4096个Gaudi 3加速器,你需要构建32个子集群,并将96个叶交换机与3组16个主干交换机交叉链接,这将让你有三种不同的路径通过双层网络将任何Gaudi 3连接到任何其他交换机。就像这样:
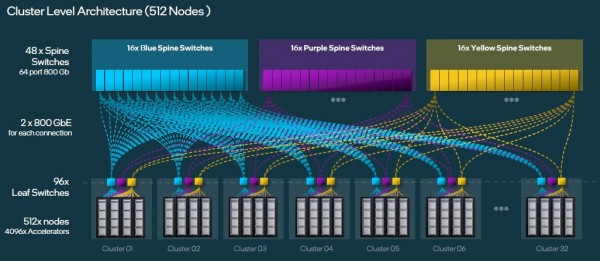
该图表应该将它们标记为子集群,而不是集群。但你能明白的。
现在让我们简单谈谈性能,然后再更深入地讨论。Medina展示的性能结果显示,Gaudi 3在训练Llama2 7B和13B以及GPT-3 175B模型方面要比Nvidia H100快1.4倍至1.7倍,在Llama 2 7B和70B以及Falcon 180B上进行推理的性能比H100高出90%至4倍。
追随功能的外形尺寸
最后是外形尺寸。这是Gaudi 3加速器的OAM版本,理论上应该是微软和Meta的首选,他们创建了OAM的外形并于2019年3月将其开源。看一下:

这是通用基板,将其中的8个创建一个主板,其中所有这些Gaudi 3设备都是互连的,还有6个运行速度为800Gb/秒的OSFP端口:

这个UBB系统大致类似于Nvidia的HGX系统板,后者已经用于Nvidia的A100、H100以及即将推出的B100加速器中。
英特尔还将提供Gaudi 3的PCI-Express 5.0 x16变体,具有被动冷却功能,因此可以直接插入任何支持双宽外形插槽的服务器中:

风冷式Gaudi 3设备已经提供样品有几周时间了,安装有冷板的液冷式设备将于2024年第二季度提供样品。风冷式Gaudi 3将在第三季度批量生产,液冷的将在第四季度量产。戴尔、HPE、联想和超微都将制造基于这些Gaudi 3加速器的OEM系统,Gaudi 3也将通过Intel Developer Cloud提供。Gaudi 2仅出现在超微制造的设备中。因此看来,OEM厂商对Gaudi 3的重视程度要高于Gaudi 2,这与OEM厂商在Hopper GPU推出期间的低分配率有很大关系。
好文章,需要你的鼓励


Meta斥资143亿美元投资Scale AI强化模型训练
Meta以143亿美元投资Scale AI,获得49%股份,这是该公司在AI竞赛中最重要的战略举措。该交易解决了Meta在AI发展中面临的核心挑战:获取高质量训练数据。Scale AI创始人王亚历山大将加入Meta领导新的超级智能研究实验室。此次投资使Meta获得了Scale AI在全球的数据标注服务,包括图像、文本和视频处理能力,同时限制了竞争对手的数据获取渠道。

清华大学团队研发AI城市规划师:让虚拟居民在真实城市中自由“生活“
清华大学团队开发了CAMS智能框架,这是首个将城市知识大模型与智能体技术结合的人类移动模拟系统。该系统仅需用户基本信息就能在真实城市中生成逼真的日常轨迹,通过三个核心模块实现了个体行为模式提取、城市空间知识生成和轨迹优化。实验表明CAMS在多项指标上显著优于现有方法,为城市规划、交通管理等领域提供了强大工具。

欧洲卫星运营商将通信服务推向更高轨道
欧洲太空通信产业发展迅猛。乌克兰Kyivstar获得监管批准测试Starlink直连手机服务,完成了与星链卫星网络的SIM卡集成测试,计划2025年第四季度推出支持短信和OTT消息的D2C服务。同时,CTO宣布即将发射首个再生5G毫米波载荷,其J-1任务旨在演示轨道超高速低延迟5G传输。该公司正构建超低轨道星座,使用5G毫米波频谱提供高速低延迟连接。

MIT团队发现“废料“照片训练出最好AI:垃圾数据竟能炼成神奇模型
MIT研究团队发现了一个颠覆性的AI训练方法:那些通常被丢弃的模糊、失真的"垃圾"图片,竟然能够训练出比传统方法更优秀的AI模型。他们开发的Ambient Diffusion Omni框架通过智能识别何时使用何种质量的数据,不仅在ImageNet等权威测试中创造新纪录,还为解决AI发展的数据瓶颈问题开辟了全新道路。
2024
04/12
11:51
分享
点赞

Meta斥资143亿美元投资Scale AI强化模型训练
英国高等教育机构与Oracle达成Java许可协议,节省4500万英镑费用
英国独立网络合作协会警告:电信评估中Openreach地位存疑
异构智算 纵横未来|异构智算产业生态联盟走进多模态跨尺度生物医学成像设施
云量子计算:万亿美元机遇背后的隐藏风险
第五届数字安全大会收官,十二大创新赛道领航者揭幕
苹果内部讨论收购AI搜索引擎Perplexity
数据中心保护涂层:环境效率提升的隐藏驱动力
防范天网威胁:构建可信赖的AI关系
无人驾驶出租车的远程监控与安全辅助技术
AI搜索引擎导致网站流量暴跌,搜索推荐量下降30%
Cohesity深度集成MongoDB增强数据库备份恢复能力
