
对手?朋友?英特尔代工业务会加速半导体产业洗牌吗? 原创
半导体市场已经变天,特别是数据中心芯片市场格局变化已成定局
看下近期各个半导体企业的财报:
NVIDIA发布2024财年第四季度及全年财务报告,季度收入创下221亿美元的纪录,较第三季度增长22%,较去年同期增长265%;数据中心季度收入创下184亿美元的纪录,较第三季度增长27%,较去年同期增长409%;全年收入创下609亿美元的纪录,增长126%。
英特尔发布2023年第四季度财报。财报显示,英特尔第四季度营收154.1亿美元,同比增长10%;英特尔四季度数据中心营收为40亿美元,同比下滑10%。
AMD公布2023年第四季度营业额达62亿美元,2023年全年,AMD营业额为227亿美元;2023年,AMD数据中心事业部营业额为65亿美元,与2022年相比增长7%。
这样的数据对比,对于英特尔来说是巨大的压力。为了扭转颓势,英特尔代工(Intel Foundry)似乎成了英特尔的一种尝试。
英特尔代工衍生于几年前英特尔首席执行官帕特·基辛格的IDM 2.0策略,虽然英特尔在极力改变现有的市场现状,但是变革来临,谁也无法置身事外。
英特尔的业务单元表现差强人意,为了激活自身的活力,业务单元独立化是英特尔采取的策略之一,比如PSG(FPGA业务,Altera)独立化运营,而代工业务也是如此。
业界不怀疑英特尔的能力,特别是在代工方面,因为业界也需要除了台积电之外,多一个选择。显然英特尔代工成了这种期待的结果。
最新的消息是微软计划采用Intel 18A制程节点生产其设计的一款芯片。同时,Synopsys、Cadence、Siemens和Ansys等IP和EDA供应商也确认支持英特尔制程和封装技术。
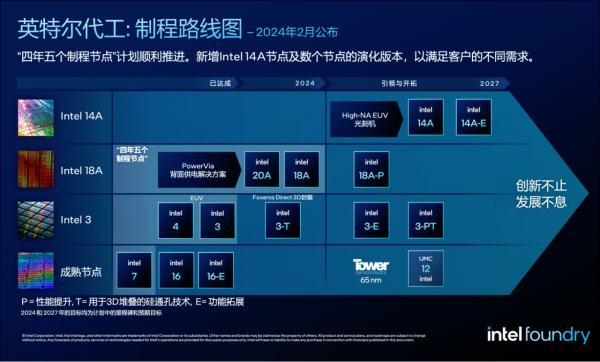
英特尔预计将于2025年通过Intel 18A制程节点重获制程领先性。采用Intel 18A工艺的Clearwater Forest至强处理器已流片。该处理器还采用Intel 3作为其基础芯片的制程工艺,并采用EMIB、Foveros Direct先进封装技术。
在笔者看来,当前的芯片市场是结构化变革,也就是芯片需求是持续增加的,但是品类不像早前那样单一,比如CPU、GPU、FPGA等。
如今不管是AI还是汽车,芯片的需求是巨大的,但是这种需求是不同于以往的产品需求,需要芯片厂商转变产品思路,比如从CPU到GPU。
所以对于英特尔而言,原有的优势已经不复存在,需要在新的客户需求和产业变化下重新建立自己的护城河,这是巨大的挑战。毕竟对于英特尔这样体量的企业而言,这种的转型需要从技术、组织、产品等多个维度进行变化。
其实,我觉得代工是一个很好的突破点,在代工下,很多竞争对手成了朋友,比如英特尔与NVIDA、Arm建立了代工关系,这在此前是不可想的。
当下,产业和企业的边界在消失,竞合关系也在变化,英特尔通过代工业务增加了产业链的协同能力,而不是此前的一体化闭环体系。
截止目前,英特尔已经拥有了Mobileye、PSG、Intel Foundry等独立业务单元,这些领域是具有潜力的,这是英特尔自身变革的尝试,至于后续发展如何,我不敢断言,但是迈出了这一步总比固步自封要好很多。
好文章,需要你的鼓励



粒子物理学的“门卫“进化了:芝加哥大学等机构用强化学习让大型强子对撞机自动调节探测阈值
芝加哥大学等机构将强化学习引入大型强子对撞机触发系统,用GFPO方法实现阈值自适应调整,显著提升信号效率并保持背景率稳定,首次在真实CMS碰撞数据上完成验证。

AI评测初创公司Braintrust遭入侵,敦促所有客户轮换API密钥
AI评估初创公司Braintrust确认其AWS云账户遭未经授权访问,导致客户API密钥泄露风险。公司已通知所有客户立即更换存储在其平台上的API密钥,并表示已封锁受损账户、审计相关系统访问权限,同时对内部密钥进行了轮换。目前,Braintrust正对事件原因展开调查。安全专家指出,此次泄露可能对依赖该平台的AI公司产生连锁影响。该公司今年2月完成8000万美元B轮融资,估值达8亿美元。

英伟达造出了一个“既会说话又会听歌“的超级AI,而且完全不忘记原本的聪明劲儿
英伟达发布Audex多模态大模型,在音频理解与生成达到最优水平的同时,保持文字推理能力几乎零退步,提供完整技术路径。
2024
02/22
15:32
分享
点赞

WAIC 2026主论坛(下午场)重磅揭晓!
AI评测初创公司Braintrust遭入侵,敦促所有客户轮换API密钥
牙科诊所软件漏洞修复:患者医疗记录曾遭泄露
关键基础设施巨头Itron确认遭遇网络攻击
Vercel数据泄露范围扩大,黑客早于已知时间节点已入侵
苹果与博通签署300亿美元协议,共同生产美国本土无线芯片
摩托罗拉领投BRINC 1.25亿美元,推动紧急救援无人机大规模扩张
AI赋能芯片设计:前景广阔,疑问犹存
Arm今夏将推出自研芯片,Meta成首批客户
Cellebrite携手SkySafe,打造无人机数字取证一体化平台
人类意识研究者:对AI可能有意识的说法持怀疑态度
帮助AI模型走向现实世界的企业预测决策技术
