
英伟达“GRACE”ARM CPU在HPC领域力压X86

从种种方面来看,英伟达打造的“Grace”CG100服务器处理器都堪称其首款真正的服务器级CPU,也成为扩展“Hopper”GH100 GPU加速器(专为HPC仿真与建模工作负载而设计)内存空间的重要方案。目前,多家主要超级计算实验室都在对Grace CPU进行HPC测试,下面我们一起来看这些有趣的早期结果。
Grace CPU拥有相对较高的核心数量和相对较低的发热量,同时配备低功耗DDR5(LPDDR5)内存组(常见于笔记本电脑,但配合纠错机制来达到服务器应用级别)。目前常见的单节点内存容量通常在256 GB到512 GB之间,基本可以满足HPC工作负载的需求。
将两个Grace CPU组合成一个Grace-Grace超级芯片,即可获得一种使用NVLink芯片间互连的紧密耦合封装,能够在LPDDR5内存组之间保证内存一致性,且运行功耗仅为500瓦左右。这样的方案对HPC受众来说颇具吸引力,因为其能提供144个基于Armv9架构的Arm Neoverse“Demeter”V2核心,外加1 TB物理内存与1.1 TB/秒的峰值理论带宽。但出于某种原因,可能是LPDDR5内存为了保证更好的良品率,这样的组合只能实际提供960 GB内存容量和1 TB/秒的内存带宽。而如果愿意,英伟达完全可以创建一个四路Grace计算模块,整体包含288个核心和1.9 TB内存,同时提供2 TB/秒的聚合内存带宽。这样的四路处理器也许能卖出与上代或者上上代GPU相媲美的价格……
作为参考,我们在2022年3月刚发布时就对Grace芯片做过初步分析,并在2022年8月深入研究了Grace芯片架构(当时还没人确定英伟达到底使用怎样的Arm核心)。到2023年9月Arm发布架构详细信息之后,我们又对采用新架构的Demeter V2核心做过认真剖析。这里不再赘述,概括来讲,英伟达为Grace采用了Arm V2核心(而非自研核心),其中包含四个128位SVE2矢量引擎,基本相当于英特尔至强SP架构中使用的双AVX-512矢量引擎,因此可以用于运行经典的HPC工作负载、一部分AI推理工作负载(规模不能太大)、甚至可用于对中等规模的AI模型进行重新训练。
巴塞罗那超级计算中心同纽约州立大学石溪分校/布法罗分校最近公布的数据,也再次证实了这一判断。两个研究小组都发布了在各类HPC与AI基准测试中使用Grace-Hopper与Grace-Grace超级芯片的性能结果,也基本符合我们之前做出的猜测:从发热量和使用成本角度看,Grace CPU确实能够在HPC领域表现出一定的竞争力。
两个研究小组也都在上周于日本名古屋召开的HPC Asia 2024大会上发表了相关论文。巴塞罗那超级计算中心方面的文章题为《英伟达Grace超级芯片在HPC应用中的早期评估》(https://dl.acm.org/doi/abs/10.1145/3636480.3637284),石溪与布法罗分校研究小组的文章则题为《英伟达Grace CPU超级芯片与英伟达Grace Hopper超级芯片的科学工作负载初探》(https://dl.acm.org/doi/abs/10.1145/3636480.3637097)。两篇论文都介绍了如何在Grace-Grace与Grace-Hopper超级芯片上实际执行关键HPC应用程序。相对来说,纽约州立大学研究人员的论文更有指导意义,这主要得益于小组汇总了来自多家HPC中心和一家云服务商的性能数据,具体涵盖石溪分校、亚马逊云科技、匹兹堡超级计算中心、得克萨斯高级计算中心和普渡大学的性能数据。
巴塞罗那超级计算中心则将英伟达Grace-Grace与Grace-Hopper超级芯片(属于其MareNostrum 5系统实验集群的一部分)与上代MareNostrum 4超级计算机中的x86 CPU节点进行了性能比较,后者采用两块24核“Skylake”至强SP-8160 Platinum处理器,运行主频为2.1 GHz。以下是MareNostrum 4节点与Grace-Hopper与Grace-Grace节点的简单结构比较:
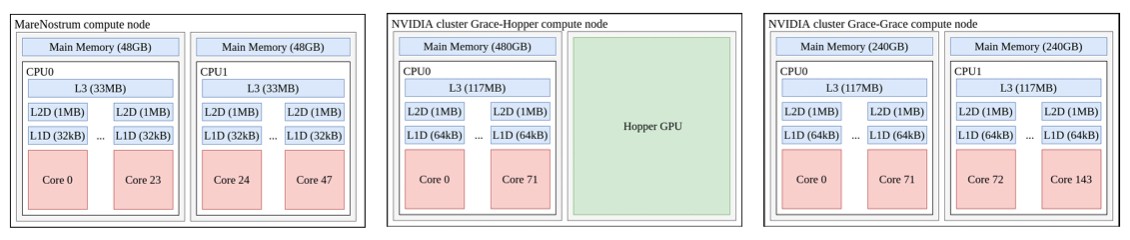
在Grace-Hopper节点上,巴塞罗那超级计算中心仅在超级芯片的CPU部分上测试了各类HPC应用程序。石溪分校团队则对比较了早期英伟达系统中的CPU-CPU与CPU-GPU组合。
以面来看巴塞罗那超级计算中心给出的汇总表格,其中比较了三套测试系统的各自架构:
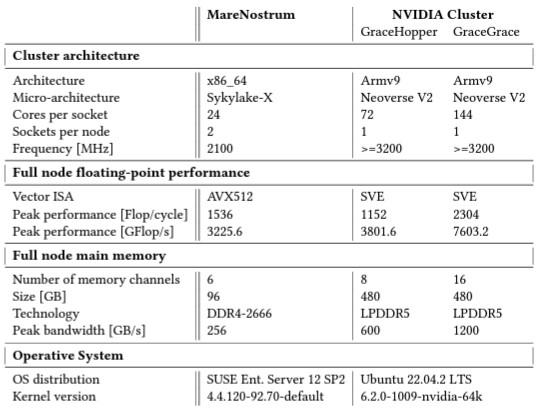
巴塞罗那超级计算中心称,Grace处理器早期版本中的CPU主频已下降至3.2 GHz,且内存带宽也低于英伟达当初公布的完整生产单元。虽然具体数字尚难以最终确定,但Grace CPU受测设备的实际运行主频约为3.2 GHz。
在应用程序运行性能上,巴塞罗那超级计算中心在三类节点上分别运行了自主开发的Alya计算力学与OpenFOAM计算流体力学代码、NEMO海洋气候模型、LAMMPS分子动力学模型以及PhysiCell多细胞模拟框架。以下是Grace-Grace节点与上代MareNostrum 4节点之间的性能比对。这里我们跳过了Grace-Hopper节点,因为其中并没有用到GPU,所以性能只相当于Grace-Grace节点的一半左右。下面来看相同数量CPU核心条件下的加速结果:
- 在Alya应用程序中,Grace-Grace的速度达到1.67倍至18.1倍。
- 在OpenFOAM上,Grace-Grace的加速效果约为4.49倍。
- 在NEMO上,加速比为2.78倍。
- 在LAMMPS上,当使用相同数量核心时(1到288个),加速比为2.1倍至2.9倍。
- 在PhysiCell上,同样使用48核心节点时的加速比为3.24倍。
很明显,Grace-Grace单元拥有3倍核心数量,因此节点层面的比较也应照此比例。
前文已经提到,石溪分校的论文还包含一系列基准测试,并整理了其他机构的性能结果。下表所示为运行HPC Challenge(HPCC)基准测试时各节点的相对性能,其中分别提取Matrix、LINPACK与FFT元素进行比较:
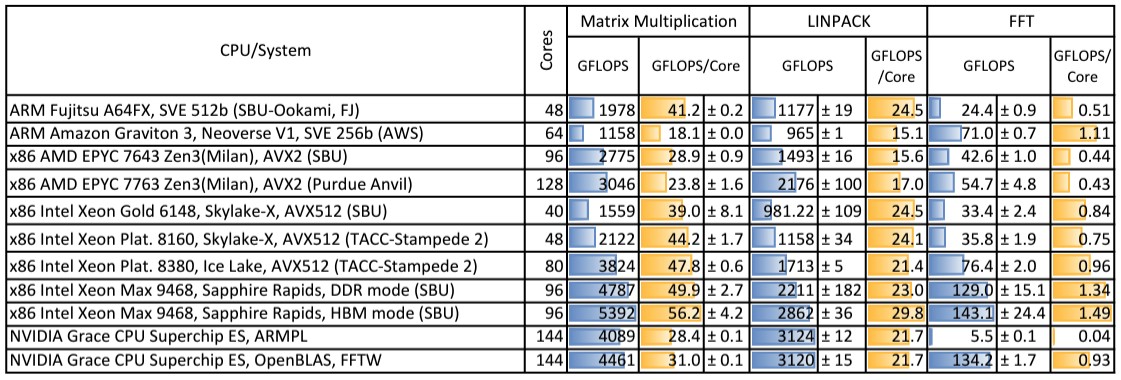
我们已经很长时间没看到这种带有误差范围的基准数据了,由于监控难度较大,多数测试并不提供误差参考。总而言之,以单一插槽为基础,Grace-Grace超级芯片的性能介于英特尔“Ice Lake”与“Skylake”至强SP之间,但高于“Milan”与“Rome”AMD EPyc处理器。
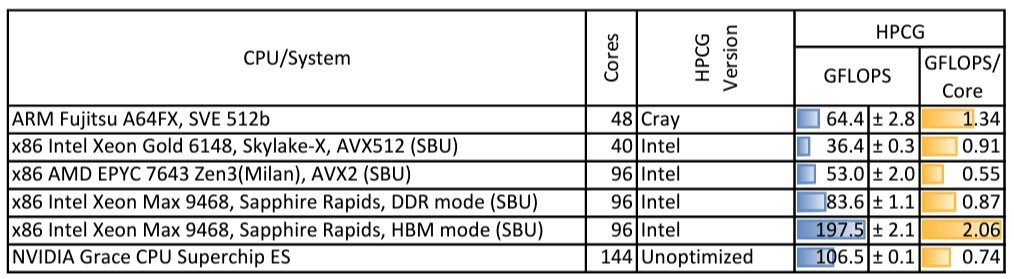
而在更严格的高性能共轭梯度(HPCG,主要强调计算与内存带宽之间的平衡,很多超级计算机在此测试中得分不高)测试中,Grace-Grace超级芯片带来了如下性能表现:
再来看Grace-Grace在OpenFOAM上的性能表现,测试使用MotoBikeQ在全部硬件上模拟1100万个细胞:
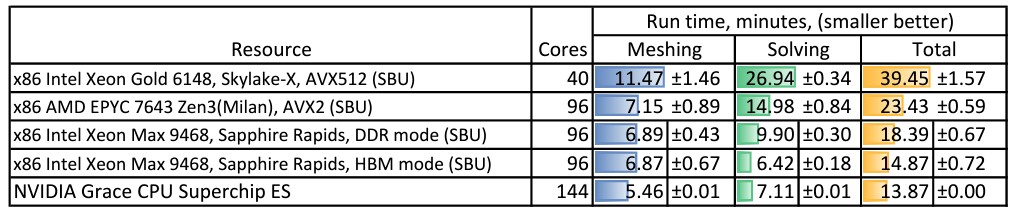
我们本以为Grace-Grace单元能在这项测试中表现更好,但很遗憾……
最后来看Gromacs分子动力学基准测试在各节点上的运行得分,包括CPU-GPU和纯CPU变体:
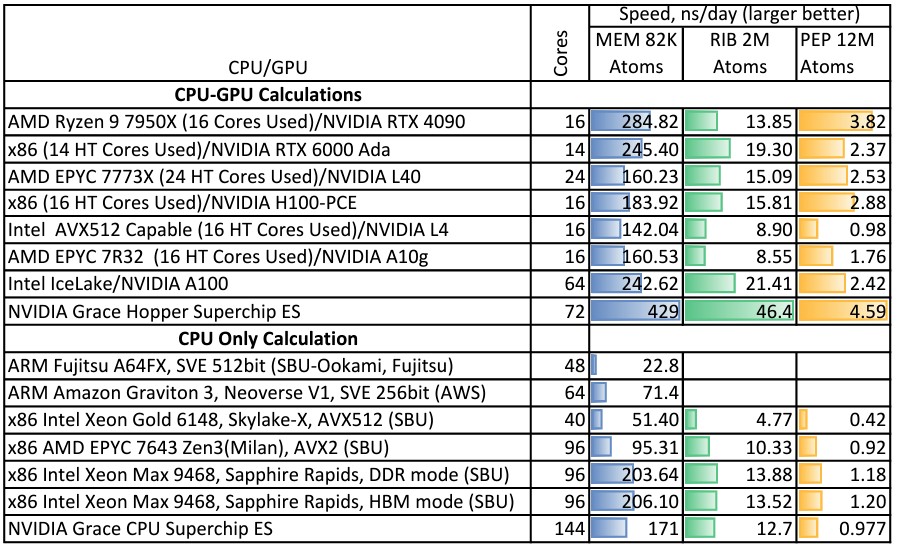
看来最终的优胜者已经出现了!Grace-Hopper组合明显表现更佳,但其他CPU配合Hopper GPU也能达到类似的效果。而在仅采用CPU的Grace-Grace单元上,Gromacs的性能则与双“Sapphire Rapids”至强Max系列CPU基本相当。值得注意的是,该芯片上的HBM内存似乎并没有给Gromacs负载带来什么性能提升。
总而言之,这就是我们目前掌握的Grace CPU在HPC工作负载上的实际表现与相关结论。石溪分校的论文中还列举了其他基准测试,欢迎感兴趣的朋友自行查看。
好文章,需要你的鼓励


雷克萨斯LFA电动超跑2027年量产,将搭载固态电池
丰田旗下豪华品牌雷克萨斯正以纯电动版本复活经典跑车LFA。新车已在古德伍德速度节亮相,预计2027年量产,将采用丰田期待已久的固态电池技术。该技术承诺更高能量密度与更快充电速度,但丰田已多次推迟相关计划。新款LFA搭载电动动力系统,内饰配备Yoke方向盘与沉浸式数字座舱,车身尺寸与阿斯顿马丁DB12相近。面对比亚迪腾势Z等1500马力级竞品,雷克萨斯能否追上电动超跑赛道,值得关注。

慧眼难辨“何时何处“——慕课里AI通才的专业盲区,庆应义塾大学新出的这套考卷让15个顶级模型集体翻车
庆应义塾大学与英伟达推出AnyGroundBench,测试15个顶级视觉语言模型在手术、工业等五大专业领域的时空定位能力,揭示当前AI在专业场景下的系统性空间定位瓶颈。

科学家研究证明:我们并非生活在模拟现实中
加拿大不列颠哥伦比亚大学奥卡纳根分校的研究人员通过数学方法,对"模拟现实"理论给出了否定答案。研究人员米尔·法扎尔在《物理全息应用期刊》上指出,基于不完备性与不可判定性数学定理,现实无法仅通过计算来完整描述,它需要非算法性的理解,而这超出了算法计算的范畴,因此无法被模拟。尽管如此,"模拟宇宙"的观念短期内仍难以从公众讨论中消失。

清华大学与蚂蚁集团联合打造“数据科学AI考官“:AgenticDataBench如何给数据智能体打出一张精准成绩单?
清华大学与蚂蚁集团联合推出AgenticDataBench,含344道真实数据科学任务和433个精细技能标签,系统评测12种主流数据智能体配置的能力边界与短板。
2024
02/09
07:57
分享
点赞

科学家研究证明:我们并非生活在模拟现实中
苹果与博通签署高达300亿美元芯片采购协议
零信任网络访问如何从根本上消除隐性信任
Crusoe扩展AI平台:推出无服务器微调与自助推理部署
Oratomic完成3亿美元融资,仅需2万个量子比特造出实用量子计算机
Anthropic将Claude Cowork智能体扩展至网页端与移动端
OpenAI发布延迟模型,美国AI监管混乱引发企业隐忧
微软押注企业AI需要工程师而非庞大销售团队
Anthropic揭开Claude AI黑箱:J-space技术带来模型内部可见性突破
英格兰银行获授权监管亚马逊、谷歌等科技巨头
酷睿Ultra战力Plus,英特尔携九大合作伙伴亮相Bilibili World 2026
iOS 26.5.2正式发布,包含逾20项安全修复,Claude协助发现漏洞
