
英特尔宣布放弃CPU-GPU引擎,转而将NNP引入GPU

去年2月,英特尔正式宣布将在“Falcon Shores”项目中打造CPU-GPU混合计算引擎,希望通过单一插槽实现对CPU和GPU容量的独立扩展。很明显,芯片巨头打算借这个项目与英伟达和AMD展开正面竞争。英特尔将其称为XPU,AMD将自己的同类方案命名为APU,而英伟达还没有严格意义上的同类竞品(具体取决于大家如何理解英伟达标榜的「超级芯片」)。
当时有报道指出,这种混合方法是将CPU和GPU的可变小芯片组合接入至强SP插槽之内,并在小芯片之间采用与至强架构相同的主内存与低延迟互连。此举能够将至强SP的复杂AI推理性能提升至超越原有AMX矩阵数学单元的水平,让HPC浮点算力优于AVX-512向量单元,依靠更低的延迟让客户放弃Max产品线、英伟达乃至AMD的独立GPU。
时任英特尔加速计算系统与图形业务总经理的Raja Koduri在公告中承诺,英特尔Falcon Shores将把每瓦性能提升超5倍,单x86插槽计算密度提高超5倍,并依靠所谓“极限带宽共享内存”把内存带宽和容量也同样提高超过5倍。这里的5倍,是与当时同为英特尔旗舰处理器的“Ice Lake”至强SP服务器插槽得出的比较结论。但今年3月随着Koduri离开英特尔,这个雄心勃勃的项目也开始低调淡出。

Falcon Shores原定于2024年推出,人们普遍预计它会直接登陆与下一代“Granite Rapids”至强SP相同的“Mountain Stream”服务器平台。乐观的朋友甚至做出更激进的推测,比如英特尔可能会给GPU添加一个仿真层,让它如同一个硕大无比的AVX-512向量数据单元以简化编程。
但如前文所述,随着Koduri于今年3月离开英特尔,芯片巨头再次食言而肥。不仅开始在至强SP插槽内提供5种不同的CPU-GPU小芯片组合,还在帮助阿贡国家实验室“Aurora” 超级计算机冲击2百亿亿次峰值算力的“Ponte Vecchio”Max系列芯片中弃用了“Rialto Bridge”GPU。当时有消息称,首批Falcon Shores设备将于2025年问世,且将是纯GPU小芯片的版本,基本算是代替Rialto Bridge成为Ponte Vecchio的独立GPU继任者。而之所以放弃Rialto Bridge,是因为英特尔打算在开发路线图上每两年推出一代新GPU——这也符合英伟达和AMD的产品更新节奏。
而在最近于汉堡举行的ISC23超级计算大会上,英特尔再次阐明了对于Falcon Shores的规划,确认该设备就是纯GPU计算引擎,而且目前发布混合XPU的时机还不成熟。
超算部门总经理Jeff McVeigh在ISC23大会的简报中解释称,“之前关于将CPU和GPU集成为XPU的宣传造势还为时过早。”坦率地讲,McVeigh可能要为Koduri甚至是Jim Keller当初做出的决定背锅了。在两年多前离职之后,Koduri已经转投AI初创公司Tenstorrent,目前担任首席技术官职务。
McVeigh强调,“具体来讲,我们发现目前所处的市场比一年之前的想象要活跃得多——所有创新都围绕着生成式AI大语言模型展开。虽然其中大部分用例都集中在商业领域,但也有很多在科学研究中得到了广泛应用。面对这样一个瞬息万变的动态市场,我们实在不愿意、也不可能非要朝着CPU-GPU固定搭配比例的方向前进,甚至没法确定x86和Arm哪种架构更好。一切都要保持灵活,充分发挥良好的软件支持能力,这跟相对稳定的成熟市场有着很大区别。只有在工作负载确定且清晰,不再发生重大变化的背景下,这种固定搭配才有意义。我们已经做过多次设计整合,这确实有助于降低芯片成本和功耗。但还是那句话,一切的前提是稳定——两种组件的供应商需要是稳定的,搭配比例和配置方式也需要是稳定的。所以认真审视目前的市场状态之后,我们认为当下还不是做整合的好时机。”
英伟达即将向市场投放大量“Grace”CPU和“Hopper”GPU超级芯片,AMD则着手向大客户劳伦斯利弗莫尔国家实验室供应大量“Antares”Instinct MI300A混合CPU-GPU计算引擎。所以要说英特尔想在混合计算引擎领域独占鳌头,这两家是肯定不会同意的。
另外,XPU整合思路可能也确实不适合英特尔目前的战略——芯片巨头需要想办法削减成本,并专注于在核心服务器CPU市场上多赚点钱。这可能也是英特尔自1990年代末到2000年初安腾业务崩溃以来,第一次需要打起精神面对艰难时光。更确切地说,这种整合可能不太适合英特尔CPU核心和GPU核心。也许英特尔CPU加英伟达GPU才是市场所期待的最佳组合?至少目前英伟达还没有自己的服务器CPU业务,所以这种潜在的合作伙伴关系仍有空间,比如通过NVLink端口将“Sapphire Rapids”CPU跟HBM3 DRAM芯片对接起来。
无论如何,这已经不是英特尔第一次考虑在至强服务器芯片中引入x86核心之外的辅助计算设计了,甚至不是第一次临阵决定撤兵。
英特尔曾在2014年6月透露正在开发混合CPU-FPGA设备,并在2016年3月的开放计算峰会上展示了混合15核Broadwell-Arria 10 GX原型设计。2018年5月,随着这款混合CPU-FPGA产品的正式推出,其CPU端升级成了20核的Skylake小芯片,FPGA端则封装Arria 10 GX。当然,英特尔多年来一直在自家至强E3处理器上同时整合CPU与GPU晶粒,但却很少讨论集成GPU所带来的浮点运算性能。可之后的很多年里,英特尔不再对混合CPU-FPGA设计做任何评论,甚至没有讨论过用同样的思路打造低端CPU-GPU的可能性。长期的沉寂直到后来计划于2024年推出的Falcon Shores加Granite Rapids至强SP时才被打破。
如今,Falcon Shores多芯片GPU定于2025年推出,并将携手“Clearwater Forest”至强SP处理器共同进入Granite Rapids架构时代。
对于科学芯片,McVeigh在ISC23大报的发展路线图中也做出了有趣的说明。首先来看路线图内容:

自2022年5月以来,英特尔一直在交付Gaudi2矩阵数学引擎,这部分成果来自2019年12月以20亿美元收购的Habana Labs。英特尔还在今年3月发布了Gaudi3这款后继产品,但尚未透露太多细节。目前来看,Gaudi 3可能会在2024年初与大家见面。
接下来,在Falcon Shores多芯片GPU在2025年投放市场之后,Gaudi与Ponte Vecchio和Falcon Shores GPU之间的硬性边界将彻底消失。毕竟在有了具备强大混合精度矩阵数学算力的NNP(神经网络处理器)和拥有可观混合精度矩阵数学的GPU之后,下一代Falcon Shores用不着依靠Gaudi4也能获得惊人的市场竞争力。同时需要注意,英特尔必须尽快想办法落地降本增效计划——包括在2023年内削减30亿美元成本,并在2024和2025年再削减50到70亿美元预算。
McVeigh表示,Falcon Shores将同时面向HPC和AI工作负载,全面升级为HBM3内存,并将“继承Gaudi产品的最佳优势,包括标准以太网交换”和“规模化I/O设计”。

这里所说的I/O应该是通过CXL over PCI-Express将CPU接入Falcon Shores GPU。但从目前公布的信息看,GPU之间的互连应该是用Habana Labs开发的增强版以太网结构实现的。我们不太清楚为什么不全面采用PCI-Express 6.0互连,这可能是考虑到大多数机架提供的PCI-Express线缆长度和端口数量都比较有限。
以太网互连能够将128个Gaudi1芯片设备对接并扩展为统一系统,其中每个Gaudi1芯片都配备10个100 Gb/秒以太网端口。大家可以在单一节点内部署4或8个Gaudi1设备,进而通过32节点或16节点扩展构建起128设备的全互连系统。Gaudi2则可通过24个100 Gb/秒的集成以太网商品进行扩展,各端口间以全对全、非阻塞拓扑将8个节点相互连通:
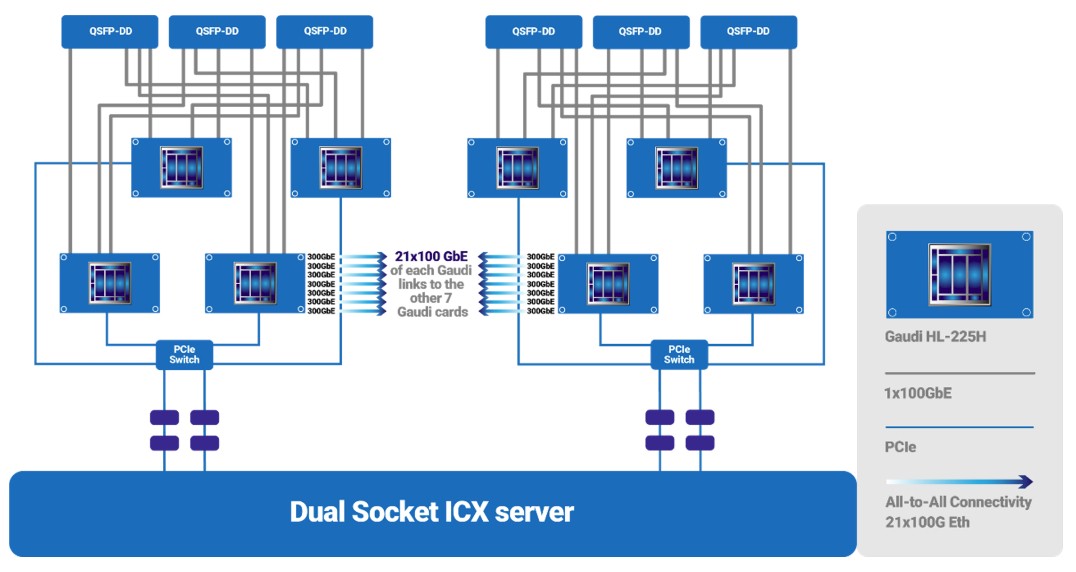
要构建这样的八路Gaudi2系统,每个设备上的24个端口中须有21个用于在矩阵引擎间建立全对全互连。每设备的余下3个端口则以交错方式聚合为总计6个QSFP-DD端口,从Gaudi2机箱延伸出去以实现16或32个Gaudi机柜间的互连扩展。这部分互连通过常规以太网交换机实现。
不难想象,其中的Gaudi以太网结构后续将升级至400 Gb/秒甚至是800 Gb/秒的端口,这些端口由Falcon Shores GPU提供,并使用高速以太网交换机将更多设备互连起来。但遗憾的是,英特尔目前已经不具备自己的以太网交换机业务,收购Barefoot Networks获得的Tofino产品线早被雪藏。因此客户只能从博通、英伟达、Marvell或者思科的产品中获取这种交换功能。
另外就目前的情况看,英特尔还有可能从Gaudi设备中提取出脉动阵列——也就是矩阵数学引擎,借此替代Ponte Vecchio设计中所使用的Xe矩阵数学引擎。总之方方面面来看,Gaudi4继续作为独立产品存在的可能性都已经极低。
看起来,23.5亿美元换来的Nervana Systems和Habana Labs也就只为英特尔带来了NNP这么一项成果。对英特尔来说,未来的NNP就是GPU这种形式。而愿意继续为Gaudi2和Gaudi3买单的客户,恐怕就只剩下那些既迫切需要矩阵运算能力、又对英特尔Falcon Shores GPU无比忠诚的企业了。
好文章,需要你的鼓励


2025年金融服务业十大热点事件回顾
大型金融服务企业凭借雄厚投资能力推动企业IT发展,AI特别是生成式AI正成为焦点。金融业面临技术革命,AI将大幅降低IT复杂度和成本,但也带来就业挑战。本文回顾银行AI应用、IT系统故障、行业领袖访谈等十大关键事件,包括AI成为银行业唯一安全职业、劳埃德银行高管AI培训、英格兰银行核心系统升级等重要发展。

斯坦福大学团队突破性发现:AI智能体终于学会了如何聪明探索!
斯坦福大学、苏黎世联邦理工学院和Idiap研究所的研究团队开发出LAMER框架,首次让AI智能体学会了在陌生环境中巧妙平衡探索与利用。该框架通过跨回合训练和自我反思机制,让智能体能从失败中学习并改进策略。在四个测试环境中,LAMER分别取得了11%、14%和19%的性能提升,并在面对更困难或全新任务时展现出卓越的适应能力,为开发能自主学习的通用AI智能体奠定了重要基础。

2025年全球电信行业十大热点事件
2025年电信行业的一个显著趋势是非地面网络(NTN)和卫星通信从小众走向主流。Starlink凭借44个合作伙伴关系领跑卫星通信市场,航空公司纷纷部署机载连接服务。5G独立组网加速部署,推动移动数据消费创纪录增长。英国全光纤覆盖率达到78%,首次超越光纤到路边技术。Nokia在芬兰设立AI网络研发中心,为6G做准备。

特斯拉和苹果,谁也没想到最后是这群学者率先攻克了用摄像头“看见“雷达的难题
以色列理工学院联合MIT、英伟达等机构研究团队开发出RadarGen技术,能够仅通过摄像头画面生成逼真的汽车雷达数据。该技术采用扩散模型架构,将稀疏雷达点云转换为鸟瞰视图表示,结合深度估计、语义分割和光流信息指导生成过程,还支持场景编辑功能。实验表明生成数据可被现有检测器有效使用,为自动驾驶训练数据获取提供了新方案。
2023
06/09
16:34
分享
点赞

2025年全球电信行业十大热点事件
ChatGPT全指南:关于这款AI驱动聊天机器人的一切
全球最大影子图书馆备份Spotify热门歌曲,涉及300TB数据
Splat应用利用AI将照片转换为儿童涂色页面
至顶AI实验室硬核评测:在戴尔 Precision Max Slim上本地部署KAG,把 AI 问答系统卷出天际
联想ThinkPad
戴尔Precision
揭秘好莱坞顶级大片背后的基础架构力量
至顶AI实验室硬核评测:本地部署Step-Audio 2 mini
至顶AI实验室硬核评测:智谱AI Open-AutoGLM开源了,系统级AI Agent免费玩
高性能 AI 边缘推理服务器MIC-743-AT
Instagram长视频内容和个性化订阅可能即将到来
