
走向十万亿亿次新时代,不需要多建核电站

在高性能计算的世界中,满足于过去的成就毫无意义。无论以往有多辉煌、多眩目,一切荣耀皆是序章。在去年睽违已久的百亿亿次算力大关终被攻破之后,在橡树岭国家实验室的Frontier超级计算机帮助人类达成这一壮举之后,我们又有了新的奋斗目标。
下一个挑战非常明确:十万亿亿次算力,相当于Frontier超算系统的1000倍。在2021年宣布重返英特尔担任CEO的几个月后,Pat Gelsinger再次登上新闻头条,他表示芯片巨头计划在2027年拿下十万亿亿次目标。
Gelsinger在2021年10月的采访中提出,“2027年达成十万亿亿次是一项巨大的内部计划,需要把我们的多种技术结合起来。五年性能提升1000倍,这绝对是一场令人叹为观止的探索。”
至于英特尔的主要竞争对手AMD,热衷于推动转变的公司掌门人苏姿丰在ISSCC 2023的舞台上也同样公布了十万亿亿次计划,只是给出了更为保守——或者说更为合理的时间表。
回顾过去两年多来超级计算机的性能发展趋势和计算领域的创新成果,包括先进封装技术、CPU与GPU、小芯片架构、AI采用速度等等,苏姿丰认为该行业达成十万亿亿次水平的时间点可能是在10年之后。
她在演讲中指出,“我们去年刚刚迈过了一道非常重要的里程碑,也就是打造出首台百亿亿级超级计算机。”而达成这个光荣目标的正是采用AMD芯片的HPE系统,“其中使用到CPU与GPU组合,包含大量技术细节。无论是从性能角度,还是从效率角度,我们都真真正正实现了百亿亿次超级计算能力。但现在我们将开启新的征程,思考接下来还能不能保持住这样的创新节奏……这是每个人都需要思考的挑战,我们要如何才能继续快步前进?”
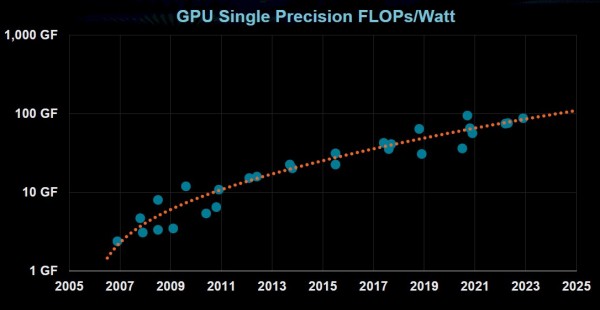
挑战的核心,在于能源效率。虽然数据中心服务器的性能每2.4年就翻一番,高性能计算甚至每1.2年翻一番,GPU则每2.2年翻一番,但服务器的能源效率却似乎没多大提升的空间。
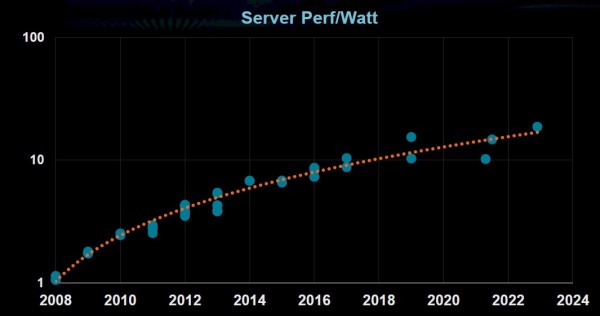
GPU能源效率的提升同样在逐渐放缓:
与此同时,超级计算效率每2.2年翻一番。如果按照这个趋势来分析,那么预计到2035年左右的十万亿亿次系统需要消耗500兆瓦电力,约合每瓦对应每秒21400亿次浮点运算。

在苏姿丰看来,“这样的情况根本就没有可行性。总功率已经跟一座核电站差不多,所以我们当前面临的根本挑战,在于如何把握接下来的十年将计算效率推向新的高度。整个行业已经为此做了很多工作,但我们必须要让效率和性能齐头并进、相辅相成。”
但攻克如此艰难的挑战并非没有可能。除了成功登顶全球最快超级计算机(比Top500榜单中接下来6大超算的总和性能更强)之外,Frontier在Green500超级计算机排名中也位列第二,显示出极强的能源效率优势。
不过一系列客观挑战,也确实让效率的进一步提升变得愈发困难。一方面是摩尔定律的维持空间愈发有限,意味着性能密度与能源效率的双重提升绝非易事。另外,IO无法像逻辑电路那样等比例缩放,随着IO距离越来越小,每比特能耗会有所增加。而且在超级计算机等大型系统当中,I/O仍是限制效率的主要因素。下面来看苏姿丰展示的I/O能效图:
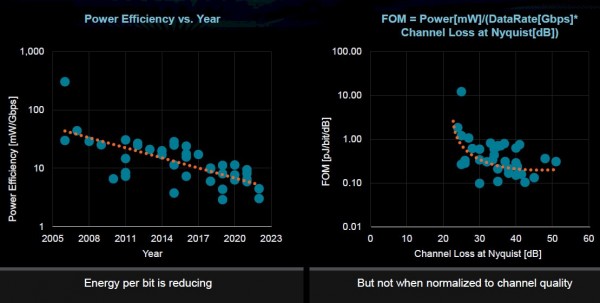
再有,更大的数据集以及计算-内存之间的传输带宽,也让内存访问变得越来越耗电。
“下一个十年,我们需要做些什么?答案是真正从整体上推动系统级效率的提升,考虑跨计算、跨通信以及跨内存等各项元素,只有这样才能打造出最高效的系统。”
苏姿丰表示,AMD目前最关注的是高级架构,目标是“为正确的工作负载使用正确的计算技术。以异构架构和加速计算为例,这就是我们目前正在努力推动的方向。”
Frontier采用的是AMD的Instinct MI250加速器,一款6纳米制程的GPU。这款芯片针对高性能计算和AI工作负载提供大量领域特定的架构增强功能,集成有大量小芯片;同时配备一块2.5D小芯片,用于拉近高带宽内存与计算间的距离。
如今,3D小芯片已经在半导体行业中广泛流行。苏姿丰还谈到在计算上堆叠内存的想法,这种方式有望减少处理器访问内存时产生的功耗。
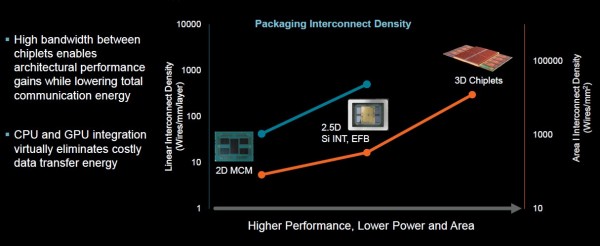
“这种设计的真正作用,是让我们能够将计算组件更紧密地结合在一起,同时降低通信成本。当我们将这些计算元件安放在电路板上时,各元件之间的距离决定了彼此通信时所耗费的电力。现在,我们可以将其以2D/2.5D排列方式进行封装,或者采取3D堆叠排列形式,从而显著提升系统的整体通信效率。”
作为苏姿丰的另一个关注重点,领域特定计算的本质就是用正确的工具执行正确的操作。从双精度浮点运算到其他数学格式,合理的搭配能够提升计算效率,并在过程中引入AI和机器学习以改善自动化水平。简单来讲,就是针对特定应用需求选择更有针对性的加速手段。
所有这一切相结合,衍生出的产物就是下一代GPU Instinct MI300,一款专门面向高性能计算和AI工作负载的芯片。
“通过5纳米制程工艺和3D堆叠,我们得以将缓存、底部晶片结构再到顶部CPU和GPU叠放起来,使用新的数学格式和不同的内存架构,借此将性能和能源效率提升5到8倍。”
这种堆叠设计对于CPU和GPU非常重要,因为二者通常拥有自己的内存缓存,因此在共享数据时必须在处理器周围移动数据。MI300的CDNA 3 APU架构包含一个统一内存架构,可消除MI250中独立内存缓存所对应的冗余内存副本,借此降低数据访问能耗。
苏姿丰还谈到内存和计算堆栈等领域有待实现的其他创新目标。
“到目前为止,我们展示的是在计算芯片上堆叠SRAM。我们已经将其投入生产,并在某些工作负载上实现了显著改善,但对其他一些工作负载帮助不大。如果能在计算芯片上堆叠DRAM乃至其他类型的内存,适用范围可能会更广。”

AMD公司还与三星合作,共同将处理机制引入内存。苏姿丰坦言,“作为处理器设计师,这样的想法似乎有点反直觉。”但在理论上,确实可以把一部分处理操作纳入内存。来自AMD和三星的研究团队发现,将部分算法核心放入内存可以将整体访问功耗降低达85%。

“这里的工作只针对单个组件,但正好借机探索应用程序如何使用此类技术。这是个需要进行大量跨学科实验的新领域。”
此外,AMD公司还与DARPA合作开发共封装光通信技术,借此提高IO效率。小芯片与压缩封装正给本地通信问题带来解决希望,但还需要更多努力才能让远距离IO的效率进一步提升。其中一种方法,就是在光学芯片中更加紧密地集成光学接收器和计算芯片。
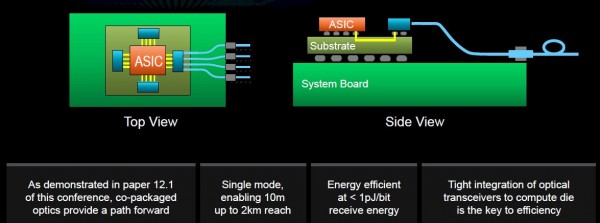
最终目标,是实现系统级封装架构,这样封装本身将成为新的主板,全面容纳从CPU到加速器、再到内存和光学元件的一切。
“这要求我们从多个层面开展不同思考。从计算的角度来看,我们的目标是优化每一个计算核心,使其达至最佳状态。无论是CPU还是GPU,抑或是领域特定加速器或者是机器学习中的训练/推理ASIC,我们都可以对各个计算核心进行分别优化,甚至由不同部门对其做各自优化。”
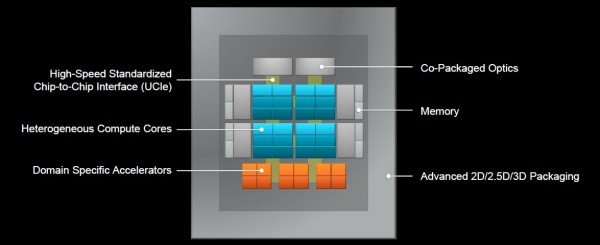
对于这样的组件混合和匹配需求,标准化芯片到芯片接口将成为决定成败的关键。
AI将在这一领域中发挥越来越大的作用,而不再只是一种用来解决高度重复问题(比如训练大规模模型)的“锦上添花”式工具。例如利用AI来替代物理模型。对于复杂的物理问题,传统的解决方案一直是使用海量数据集运行CFD模型。
然而,AI加速高性能计算“的基本思路,是使用传统高性能算力完成一部物理模拟,再利用这些数据进行训练和推理,借此缩短研究周期。如果发现找不到正确答案,则可以转而训练其他不同模型集,由此建立起效率更高的混合工作流程。”
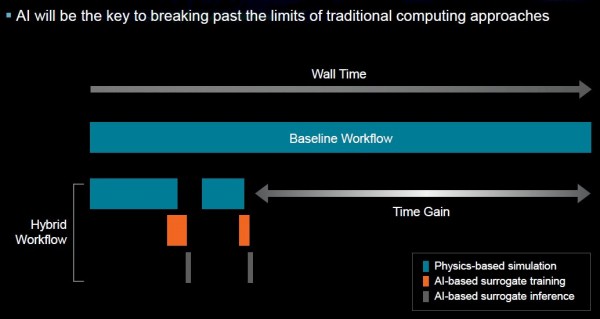
当然,目前讨论这一切还为时过早。仍需要一些工作来找寻正确的算法,并确定如何解决问题,最终将更多算法思维引入系统级优化。但苏姿丰强调,如果半导体行业想要进一步提升能源效率、让十万亿亿次计算成为现实,就必须将这些难题一一攻克。
好文章,需要你的鼓励


CoreWeave LOTA技术实现对象数据高速全球传输
CoreWeave发布AI对象存储服务,采用本地对象传输加速器(LOTA)技术,可在全球范围内高速传输对象数据,无出口费用或请求交易分层费用。该技术通过智能代理在每个GPU节点上加速数据传输,提供高达每GPU 7 GBps的吞吐量,可扩展至数十万个GPU。服务采用三层自动定价模式,为客户的AI工作负载降低超过75%的存储成本。

IDEA研究院等机构联手打造智能AI助手:让机器像人类一样思考和学习的突破性技术
IDEA研究院等机构联合开发了ToG-3智能推理系统,通过多智能体协作和双重进化机制,让AI能像人类专家团队一样动态思考和学习。该系统在复杂推理任务上表现优异,能用较小模型达到卓越性能,为AI技术的普及应用开辟了新路径,在教育、医疗、商业决策等领域具有广阔应用前景。

谷歌DeepMind与CFS合作开发核聚变等离子体AI控制系统
谷歌DeepMind与核聚变初创公司CFS合作,运用先进AI模型帮助管理和改进即将发布的Sparc反应堆。DeepMind开发了名为Torax的专用软件来模拟等离子体,结合强化学习等AI技术寻找最佳核聚变控制方式。核聚变被视为清洁能源的圣杯,可提供几乎无限的零碳排放能源。谷歌已投资CFS并承诺购买其200兆瓦电力。

AI训练新突破:上海AI实验室让大模型自己当老师,推理和判断能力同步飞跃
上海人工智能实验室提出SPARK框架,创新性地让AI模型在学习推理的同时学会自我评判,通过回收训练数据建立策略与奖励的协同进化机制。实验显示,该方法在数学推理、奖励评判和通用能力上分别提升9.7%、12.1%和1.5%,且训练成本仅为传统方法的一半,展现出强大的泛化能力和自我反思能力。
2023
03/07
15:59
分享
点赞

Littelfuse推出首款具有SPDT和长行程且兼容回流焊接的发光轻触开关
至顶科技助力AI创业者,在HICOOL峰会探索“如何用AI赚到第一桶金”
CoreWeave LOTA技术实现对象数据高速全球传输
谷歌DeepMind与CFS合作开发核聚变等离子体AI控制系统
微软为Windows 11推出全新Copilot自动化功能
苹果研究人员探索AI如何预测Bug、编写测试并修复代码
刚果称全球最大水电站可为AI数据中心供电
HPE Alletra存储业务获得战略重点关注
谷歌DeepMind与核聚变初创公司合作的真实原因
Omdia预测:超大规模云市场销售额2030年将达1630亿美元
Oracle全面押注AI,用户仍在摸索应用路径
Aramex与AWS携手推进全球物流数字化转型
