
第四代英特尔至强可扩展处理器和Habana Gaudi2在深度学习训练中展现领先的AI性能
在MLCommons近日发布的AI性能行业基准测试结果中,代号为Sapphire Rapids的第四代英特尔®至强®可扩展处理器和专用于深度学习AI训练的Habana® Gaudi®2加速器展现了卓越的训练表现。
英特尔执行副总裁兼数据中心与人工智能事业部总经理Sandra Rivera表示:“自去年6月提交了领先的MLPerf行业测试结果以来,我们团队不断取得新的进步,这让我感到非常自豪。第四代英特尔至强可扩展处理器和Gaudi2 AI加速器支持广泛的AI功能,为有深度学习训练和大规模工作负载处理需求的客户提供业界领先的性能。”
在众多数据中心应用场景中,基于至强处理器的服务器平台可用于运行一系列机器学习(ML)和数据分析的复杂管道,而深度学习(DL)正是其中的一部分。同时,这些服务器平台亦可用于运行其他应用程序,并能够适应随时间变化的多种工作负载。在这些使用场景中,至强可扩展处理器能够极大程度地降低总体拥有成本(TCO),提高全年利用率。
第四代英特尔至强可扩展处理器内置全新AI加速器——英特尔®高级矩阵扩展(AMX),旨在帮助用户通过扩展通用至强服务器平台,覆盖包括训练和微调在内的更多深度学习使用场景。AMX是一个专用的矩阵乘法引擎,内置于第四代至强可扩展处理器的每个核心。该AI引擎已经过优化,基于行业标准框架,可提供相较于上一代深度学习训练模型高达6倍的性能。
而在服务器或服务器集群主要用于深度学习训练和推理计算的场景中,Habana Gaudi2则是理想的加速器,针对这些专用场景,它旨在提供优异的深度学习性能并降低总体拥有成本。
关于至强处理器的测试结果:英特尔首先提交了涵盖一系列不同工作负载的第四代英特尔至强可扩展处理器产品线的MLPerf v2.1行业测试结果。作为唯一提交该测试结果的处理器,Sapphire Rapids再次被证实其优异的AI性能,使客户能够随时随地使用共享基础设施进行AI训练。内置英特尔AMX的第四代至强可扩展处理器在多个行业标准框架中为用户提供即时可用的性能,并集成了端到端的数据科学工具,以及来自生态伙伴广泛的智能解决方案,开发者仅需使用TensorFlow和PyTorch框架的最新版本,即可充分释放其性能。现阶段,英特尔至强可扩展处理器已经可以运行并处理全部AI工作负载。
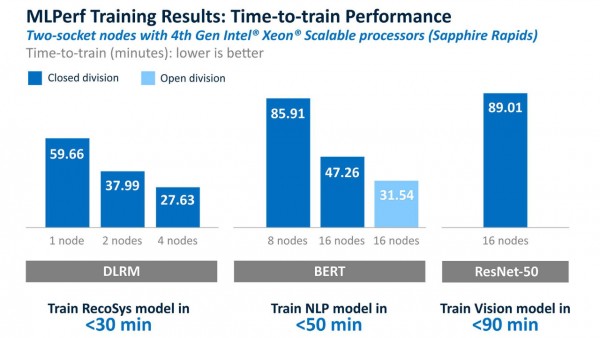
测试结果显示,第四代英特尔至强可扩展处理器正通过扩大通用CPU在AI训练方面的覆盖范围,让客户能够充分利用已经部署在商业应用中的至强处理器完成更多工作,尤其是用于中小型模型的训练或微调,即迁移学习。DLRM的结果便很好地论证了Sapphire Rapids能够在不到30分钟(26.73)的时间内仅用四个服务器节点即可完成模型训练。即使是面对大中型模型,第四代至强处理器亦可分别在50分钟(47.26)和90分钟(89.01)内成功训练BERT和ResNet-50模型。开发者可在一杯咖啡的时间内便完成小型深度学习模型的训练,在一顿午餐的时间内训练中型模型,并同时利用这些连接到数据存储系统的相同服务器,在下午进行诸如经典机器学习的其他分析。这也意味着企业能够将诸如Gaudi2的深度学习处理器预留给更大、对性能要求更高的模型。
关于Habana Gaudi2的测试结果:Habana今年五月发布了用于深度学习训练的第二代Gaudi处理器——Gaudi2,在MLPerf v2.0训练10天后汇总的成绩中表现出了领先的测试结果。Gaudi2采用7纳米制程工艺制造,拥有24个Tensor处理器核心、片内封装容量达96GB HBM2e和24个100GB RoCE以太网端口。与英伟达的A100相比,Gaudi2在这项基准测试中再次展现了领先的8卡服务器性能。
Gaudi2在TensorFlow中训练BERT和ResNet-50的时间缩短了10%。而Gaudi2的PyTorch结果则显示,与5月的Gaudi1结果相比,其BERT和ResNet-50的训练时间分别缩短了4%和6%。这两组结果均在封闭和可用类别中提交。
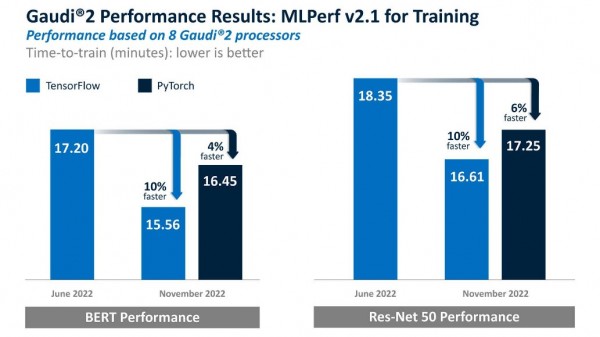
这些优异表现突显了Gaudi2专用深度学习架构的独特性、Gaudi2软件的日益成熟以及Habana® SynapseAI®软件堆栈的扩展优势。值得注意的是,该软件堆栈针对深度学习模型开发和部署进行了优化。
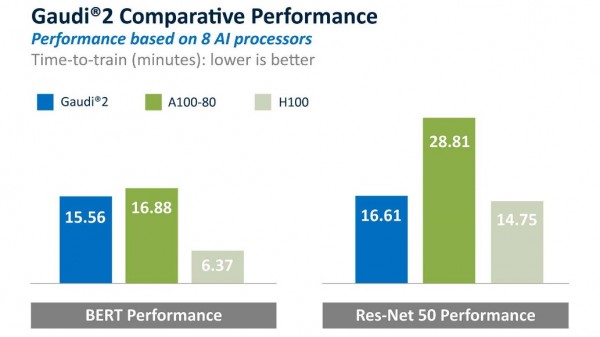
与5月的测试结果一致,Gaudi2在BERT和ResNet-50模型训练方面始终优于英伟达A100,进一步证明了该测试结果的有效性。英伟达H100的ResNet-50训练速度仅比Gaudi2高11%,而尽管H100在BERT方面比Gaudi2快59%,但英伟达报告的BERT训练时间为FP8数据类型,Gaudi2的训练时间则为经过验证的标准BF16数据类型(在Gaudi2的软件计划中启用了FP8)。因此,与A100和H100相比,Gaudi2的性价比更高。
未来,英特尔和Habana团队非常期待再次提交的英特尔AI产品组合解决方案的MLPerf测试结果。
通知和免责声明
性能因用途、配置和其它因素而异。更多信息参见www.Intel.com/PerformanceIndex。
性能测试结果是基于截至配置中所示日期进行的测试,可能并未反映所有公开可用的更新。配置详情参见信息披露部分。没有任何产品或组件是绝对安全的。
实际成本和结果可能不同。
英特尔技术可能需要支持的硬件、软件或服务激活。
来源:业界供稿
好文章,需要你的鼓励


OpenAI与微软签署初步协议修订合作条款
OpenAI和微软宣布签署一项非约束性谅解备忘录,修订双方合作关系。随着两家公司在AI市场竞争客户并寻求新的基础设施合作伙伴,其关系日趋复杂。该协议涉及OpenAI从非营利组织向营利实体的重组计划,需要微软这一最大投资者的批准。双方表示将积极制定最终合同条款,共同致力于为所有人提供最佳AI工具。

让AI推理像人一样思考,但又要快得多:中山大学团队的“智能剪刀“如何给O1模型瘦身
中山大学团队针对OpenAI O1等长思考推理模型存在的"长度不和谐"问题,提出了O1-Pruner优化方法。该方法通过长度-和谐奖励机制和强化学习训练,成功将模型推理长度缩短30-40%,同时保持甚至提升准确率,显著降低了推理时间和计算成本,为高效AI推理提供了新的解决方案。

国产R1人形机器人亮相,挑战特斯拉Optimus霸主地位
中国科技企业发布了名为R1的人形机器人,直接对标特斯拉的Optimus机器人产品。这款新型机器人代表了中国在人工智能和机器人技术领域的最新突破,展现出与国际巨头竞争的实力。R1机器人的推出标志着全球人形机器人市场竞争进一步加剧。

视觉语言模型在自动驾驶中的可靠性大考验:上海AI实验室深度揭秘AI司机的真实水平
上海AI实验室研究团队深入调查了12种先进视觉语言模型在自动驾驶场景中的真实表现,发现这些AI系统经常在缺乏真实视觉理解的情况下生成看似合理的驾驶解释。通过DriveBench测试平台的全面评估,研究揭示了现有评估方法的重大缺陷,并为开发更可靠的AI驾驶系统提供了重要指导。

