
英伟达展示设计蓝图,硅光连接GPU系统初步成形

近年来,硅光技术已经成为行业讨论中的热点话题,很多朋友也急切盼望着它能尽快普及、服务市场。十年前关于实用性硅光互连的讨论曾陷入困境,好在如今信号传输技术重新迈开发展的脚步,在我们最需要它的时候渐渐发展成形。
当初纯电路互连具有压倒性的成本优势,相当于占据了“价格/性能”等式中的分子部分,而硅光技术的亮点则主要体现在性能这个分母上。随着时间推移,传输带宽越来越大,电信号波长则变得越来越短,于是噪声问题日益严重。转折性的一天终于到来,我们开始将电磁信号载体由电子转换为光子,信号传输介质也由铜导线转为光纤导线。
下图中的曲线来自英伟达首席科学家Bill Dally在今年3月光纤通信会议上发表的演讲,很好地反映了这种趋势:
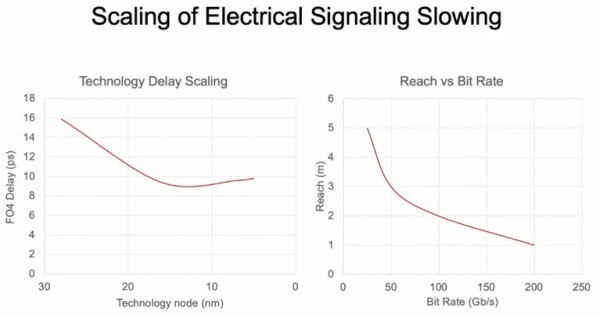
这些曲线本身代表着客观规律,但我们也可以通过一点材料学魔法再稍做改变。
几周之前,英伟达刚刚与Ayar Labs签署了合作研发协议。为此,我们有幸采访了这家硅光初创公司CEO Charlie Wuischpard,讨论英伟达和Ayar接下来的工作计划。英伟达还参与了Ayar Labs今年年初进行的C轮融资,期间他们筹集到1.3亿美元,用于开发带外激光器与硅光互连方案。HPE也在今年2月与Ayar Labs签署一项协议,共同研究如何将硅光技术引入自家的Slingshot互连系统,而且HPE同样参与了今年4月Ayar 的C轮融资。就连英特尔也提供了不少早期支持,只是芯片巨头希望将激光器嵌入到芯片内部,而不是像Ayar Labs那样从芯片外部泵入激光信号。顺带一提,目前英特尔的运营形势相当不妙,几乎可以说是不容有失,所以用硅光技术来对冲风险应该是个好选择。
在今年4月融资期间,我们曾与Wuischpard详细探讨过硅光技术在现代系统中的适用区和不适用区。根据最近得到的消息,英伟达似乎也在为此专门规划设计蓝图。
之后就是Dally在2022年光纤通信会议上发布的上述演示了,其中非常详尽地阐述了使用密集波分复用(DWDM)技术的共封装光学器件,以及如何利用硅光传输实现机架间及GPU计算引擎间的交叉连接。
演示文稿中还展示了一台没有正式定名的概念设备,类似于Dally团队早在2010年就设计出的“Echelon”百亿亿次概念系统。这台设备采用特殊的数学引擎、而非GPU,各引擎间采用高基数电气交换机和克雷“Aries”设备机架间的光学互连设计。当初的Echelon设备一直未能商业化,英伟达于是转而选择Dally在英伟达研究院中设计出的NVSwitch内存互连,并很快将其投入生产,希望制造出基于胖多端口InfiniBand互连通道的大型NUMA GPU处理器。
在最初基于NVSwitch的DGX系统中,英伟达可以通过“Volta”V100 GPU加速器在单一图像中使用16个GPU;而到“Ampere”A100 GPU加速器时,为了让每个GPU实现带宽翻倍,他们只能将NVSwitch的基数削减一半,所以单一图像中只能使用8个GPU。但伴随着今年早些时候公布的NVSwitches叶/脊网络以及将于今年晚些时候出货的“Hopper”H100 GPU加速器,英伟达已经可以将256个GPU融入统一内存结构,由此实现巨大的性能改进。
但归根结底,作为DGX H100 SuperPOD的核心,NVSwitch结构在本质上仍然是一种对NUMA直接放大的方法,而且必然受到线缆布局的限制。而且即使是到了Hopper这一代,NVSwitch的规模也不可能支持超大规模厂商将数万个GPU捆绑在巨型AI工作负载当中。
Wuischpard在采访中笑道,“我暂时还不能透露太多细节。简单来讲,这是一个物理层面的解决方案,在此之上还有软件,还要对GPU、内存和CPU进行编排。这里我们不谈具体细节,总之你可以把它理解成我们对于未来支持需求的物理性探索。这将会是一项长期、多阶段的探索,我们的目标就是用参数证明自己,逐步跨过一个个发展里程碑。”
虽然了解不到更多细节,但我们不妨回归Dally在光纤通信会议上的演讲,看看英伟达如何谋划未来基于硅光互连的GPU加速系统。
在进入正题之前,我们先来看看GPU或交换机之间的带宽和功率限制,二者接入的印刷电路板,以及承载它们的机柜。正是这些现实因素,为硅光互连的出现奠定了基础:
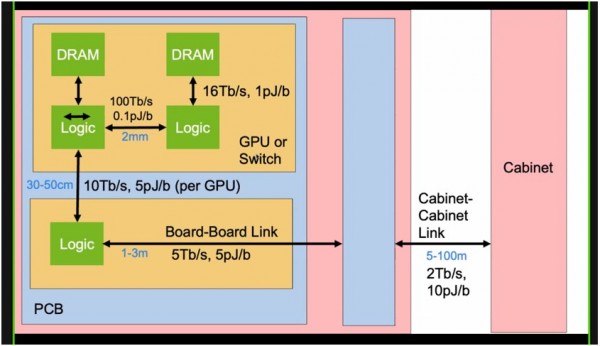
这里的规律非常简单。链路越短,传输带宽就越大,数据转移消耗的能量也越小。下表列出的中介层、印刷电路板、共封装光学器件、线缆及有源光缆各自对应的功率、成本和密度,这些都是现代系统中不同层次所使用的线缆:

使用DWDM共封装光学器件的目的,是在保持相似的成本、与有源线缆相当的传输范围以及与印刷电路板类似的信号密度的同时,获得比线缆更低的功耗。
Dally还公布了下面这份DWDM信号传输草图:

以下框图,展示了GPU与NVSwitch如何使用光引擎将电信号转换为光信号,借此为GPU创建NVSwitch网络:

每个光学引擎包含24根光纤,初步信号传输速率为200 Gb/秒,总带宽为4.8 Tb/秒。每个GPU对应两个光学引擎,用以提供基于NVSwitch结构的双工传输带宽。因此,包含6个光学引擎的NVSwitch初始速率为28.8 Tb/秒,去除编码占用的带宽后为25.6 Tb/秒。
下图所示,为英伟达硅光概念设备中各组件间的能耗计算方式:

GPU与交换机之间的数据移入与移出操作,每比特消耗3.5皮焦耳能量,与Dally在上表中设定的目标完全一致。但我们怀疑功耗成本还要再低一些,才能让计算引擎接受这种将光学器件纳入封装的设计思路。英伟达正在为此积极努力,相信后续还会有更多亮眼表现。
目前DGX-A100系统上嵌入的NVSwitch结构,使用的电信号传输范围约为300厘米,数据传输功耗则为每比特8皮焦耳。下阶段的发展目标是用硅光传输将功耗降低一半,并将设备间的传输距离提高到100米。
在达成以上目标后,架构中的GPU跟交换机就可以彼此拆分。虽然英伟达的概念机并没有提及这一点,但CPU也可以匹配光学引擎,实现同样的拆分效果。
下图为带有共封装光学器件的GPU与交换机外观:

下图则为GPU与采用CPO链路的NVSwitch的连接方式:

虽然外部激光源会占用不少空间,但这也意味着设备间的连接距离可以放大,让机架密度显著降低。这样冷却系统更易于部署,激光器也能实现更换。于是,整套系统的运行温度将有所下降,激光器工作效果提升。以DGX系统为例,目前的设备密度其实已经太高,导致机器运行温度过热。为了匹配大部分数据中心的功率密度和冷却部署能力,机架内的实际安装空间恐怕只能用掉一半。
细心的朋友可能还注意到,上图中的GPU和交换机是垂直放置的,这样同样有助于冷却。而且它们也没有安装在带插槽的巨型印刷电路板上,这样可以降低系统整体成本,省下来的钱也许可以抵消额外的光互连开支。
好文章,需要你的鼓励


Replit携手RevenueCat,助力“氛围编程“开发者实现应用变现
Replit与RevenueCat达成合作,将订阅变现工具直接集成至Replit平台。用户只需通过自然语言提示(如"添加订阅"),即可完成应用内购和订阅配置,无需离开平台。RevenueCat管理超8万款应用的订阅业务,每月处理约10亿美元交易。此次合作旨在让"氛围编程"用户在构建应用的同时即可实现商业变现,月收入未达2500美元前免费使用,超出后收取1%费用。

北京大学携手北邮,教AI“感知光线“——让生成视频真正懂得光影的秘密
LiVER是由北京大学、北京邮电大学等机构联合提出的视频生成框架,核心创新是将物理渲染技术与AI视频生成结合,通过Blender引擎计算漫反射、粗糙GGX和光泽GGX三种光照图像构成"场景代理",引导视频扩散模型生成光影物理准确的视频。框架包含渲染器智能体、轻量化编码器适配器和三阶段训练策略,支持对光照、场景布局和摄像机轨迹的独立精确控制。配套构建的LiVERSet数据集含约11000段标注视频,实验显示该方法在视频质量和控制精度上均优于现有方法。

所有人都在谈AI护栏,但真正在构建它的人在哪里?
所有人都说AI需要护栏,但真正在构建它的人寥寥无几。SkipLabs创始人Julien Verlaguet深耕这一问题已逾一年,他发现市面上多数"护栏"不过是提示词包装。为此,他打造了专为后端服务设计的AI编程智能体Skipper,基于健全的TypeScript类型系统与响应式运行时,实现增量式代码生成与测试,内部基准测试通过率超90%。他认为,编程语言的"人类可读性时代"正走向终结,面向智能体的精确工具链才是未来。

米拉-魁北克AI研究所教会小模型“聪明干活“:用更少数据超越GPT-4o的网页智能体训练秘诀
这项由蒙特利尔学习算法研究所(Mila)与麦吉尔大学联合发布的研究(arXiv:2604.07776,2026年4月)提出了AGENT-AS-ANNOTATORS框架,通过模仿人类数据标注的三种角色分工,系统化生成高质量网页智能体训练轨迹。以Gemini 3 Pro为教师模型,仅用2322条精选轨迹对90亿参数的Qwen3.5-9B模型进行监督微调,在WebArena基准上达到41.5%成功率,超越GPT-4o和Claude 3.5 Sonnet,并在从未见过的企业平台WorkArena L1上提升18.2个百分点,验证了"数据质量远比数量重要"这一核心结论。
2022
08/18
13:44
分享
点赞

Replit携手RevenueCat,助力"氛围编程"开发者实现应用变现
所有人都在谈AI护栏,但真正在构建它的人在哪里?
Chrome版Gemini新增"技能"功能,支持保存并复用常用AI提示词
OpenAI推出药物研发专属AI模型GPT-Rosalind
NanoClaw携手Vercel,为AI智能体敏感操作打造一键审批机制
SaySo:专为重建新闻信任而生的短视频应用
Loop完成9500万美元C轮融资,用AI预测并化解供应链风险
使用MacBook Neo一个月后,我发现了它的性能极限
服务器机房的门锁形同虚设,安全认证险些露馅
Isabelle/HOL:驱动Nitro隔离引擎背后的形式化证明工具
鹏鼎控股泰国建厂:全球PCB龙头如何用42.97亿元押注AI服务器
Agent赋能保险理赔:从“人工苦海”到“智能闭环”
