
TAO系列13-执行部署的TensorRT加速引擎
很多开发人员在转换完TensorRT加速引擎之后,最后准备调用起来执行推理任务的时候,就遇到一些障碍。这个环节是需要开发人员自行撰写相关代码,去执行读入数据(前处理)、执行推理、显示结果(后处理)等工作,如下图最右边的部分。
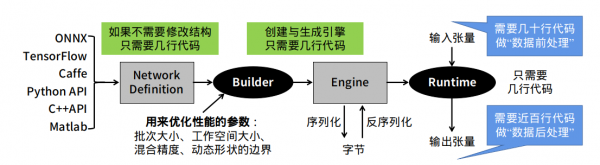
这部分的麻烦之处,在于每个神经网络的结构不相同,并没有“通用”的代码可以适用于大部分的网络结构,需要针对指定神经网络去撰写对应的代码,最重要是需要清除这个模型的输入(input bold)与输出(outpold)的名称与张量结构。
本文以前面在TAO训练工具使用的ssd神经网络为范例,提供基础的“前后处理”范例代码给读者参考,这是从英伟达中国区开发者社区所举办过多届“Sky黑客松”比赛中,所提供的开源内容中提取的重点,主要如下:
- 数据前处理:
|
|
def _preprocess_trt(img, shape=(300, 300)): """TRT SSD推理前的数据前处理""" img = cv2.resize(img, shape) img = img.transpose((2, 0, 1)).astype(np.float32) return img |
这里”shape=(300, 300)”为张量的尺度,根据模型训练时的长宽两个变量,至于transpose里的(2,0,1)是固定的,不需调整。
- 数据后处理:
|
|
def _postprocess_trt(img, output, conf_th, output_layout): """TRT SSD推理后的结果的数据处理步骤.""" img_h, img_w, _ = img.shape boxes, confs, clss = [], [], [] for prefix in range(0, len(output), output_layout): index = int(output[prefix+0]) conf = float(output[prefix+2]) if conf < conf_th: continue x1 = int(output[prefix+3] * img_w) y1 = int(output[prefix+4] * img_h) x2 = int(output[prefix+5] * img_w) y2 = int(output[prefix+6] * img_h) cls = int(output[prefix+1]) boxes.append((x1, y1, x2, y2)) confs.append(conf) clss.append(cls) return boxes, confs, clss # 返回标框坐标、置信度、类别 |
这里最重要的x1, y1, x2, y2坐标值,必须根据SSD神经网络所定义的规范去进行修改,其他部分可以通用于大部分神经网络。
- 定义TrtSSD类封装运行TRT SSD所需的东西:
|
|
class TrtSSD(object): # 加载自定义组建,如果TRT版本小于7.0需要额外生成flattenconcat自定义组件库 def _load_plugins(self): if trt.__version__[0] < '7': ctypes.CDLL("ssd/libflattenconcat.so") trt.init_libnvinfer_plugins(self.trt_logger, '') #加载通过Transfer Learning Toolkit生成的推理引擎 def _load_engine(self): TRTbin = 'ssd/TRT_%s.bin' % self.model #请根据实际状况自行修改 with open(TRTbin, 'rb') as f, trt.Runtime(self.trt_logger) as runtime: return runtime.deserialize_cuda_engine(f.read()) #通过加载的引擎,生成可执行的上下文 def _create_context(self): for binding in self.engine: size = trt.volume(self.engine.get_binding_shape(binding)) * \ self.engine.max_batch_size ##注意:这里的host_mem需要时用pagelocked memory,以免内存被释放 host_mem = cuda.pagelocked_empty(size, np.float32) cuda_mem = cuda.mem_alloc(host_mem.nbytes) self.bindings.append(int(cuda_mem)) if self.engine.binding_is_input(binding): self.host_inputs.append(host_mem) self.cuda_inputs.append(cuda_mem) else: self.host_outputs.append(host_mem) self.cuda_outputs.append(cuda_mem) return self.engine.create_execution_context() # 初始化引擎 def __init__(self, model, input_shape, output_layout=7): self.model = model self.input_shape = input_shape self.output_layout = output_layout self.trt_logger = trt.Logger(trt.Logger.INFO) self._load_plugins() self.engine = self._load_engine()
self.host_inputs = [] self.cuda_inputs = [] self.host_outputs = [] self.cuda_outputs = [] self.bindings = [] self.stream = cuda.Stream() self.context = self._create_context() # 释放引擎,释放GPU显存,释放CUDA流 def __del__(self): del self.stream del self.cuda_outputs del self.cuda_inputs # 利用生成的可执行上下文执行推理 def detect(self, img, conf_th=0.3): img_resized = _preprocess_trt(img, self.input_shape) np.copyto(self.host_inputs[0], img_resized.ravel()) # 将处理好的图片从CPU内存中复制到GPU显存 cuda.memcpy_htod_async( self.cuda_inputs[0], self.host_inputs[0], self.stream) # 开始执行推理任务 self.context.execute_async( batch_size=1, bindings=self.bindings, stream_handle=self.stream.handle) # 将推理结果输出从GPU显存复制到CPU内存 cuda.memcpy_dtoh_async( self.host_outputs[1], self.cuda_outputs[1], self.stream) cuda.memcpy_dtoh_async( self.host_outputs[0], self.cuda_outputs[0], self.stream) self.stream.synchronize()
output = self.host_outputs[0] return _postprocess_trt(img, output, conf_th, self.output_layout) |
上面三个部分对不同神经网络都是不同的内容,如果要参考YOLO神经网络的对应内容,推荐参考https://github.com/jkjung-avt/tensorrt_demos 开源项目,里面有完整的YOLOv3与YOLOv4的详细内容。
本文的开源代码可以在“https://pan.baidu.com/s/1fGLBnzqtnRNpfD3PbileOA 密码: 99et”处,下载完整的内容与配套的工具。【完】
来源:业界供稿
好文章,需要你的鼓励


苹果在印度恢复银行卡支付功能,距暂停已逾四年
苹果已开始在印度分阶段恢复Apple账户的信用卡支付功能,用户可绑定Visa和Mastercard信用卡及借记卡,用于购买iCloud+、Apple Music订阅及App Store应用。此前,由于印度储备银行于2021年推出新的周期性支付监管框架,苹果于2022年5月暂停了该支付方式。此次恢复标志着苹果在适应各国本地化监管要求方面的持续努力,同时也引发外界对苹果是否将在印度推出Apple Pay的新猜测。

腾讯混元团队打破AI“记忆瓶颈“:让大模型像人一样拥有超长记忆的新突破
腾讯混元等机构提出HiLS-Attention,通过端到端可学习的分层稀疏注意力机制,让大模型在超长上下文推理中比全量注意力快14倍,同时检索准确率更高。

Bookshop.org确认今年将推出Kobo电子书阅读器支持
Bookshop.org创始人Andy Hunter证实,与Kobo的合作集成将于今年落地。此前该计划历经多次推迟,网页措辞一度从"2026年"改为"未来某时"。Hunter表示,双方已就商业条款达成一致,工程团队正将资源重新投入Kobo支持开发,但尚无具体上线日期。该集成将支持数字版权管理要求,让用户通过Bookshop.org购买电子书,同时支持独立书店。

DeepSeek-AI与北京大学联手破局:AI聊天机器人“慢速打字“的终极解决方案
DSpark是DeepSeek与北京大学提出的投机解码框架,通过半自回归生成和置信度调度验证两项创新,将DeepSeek-V4用户生成速度提升60%至85%。
2022
05/31
11:24
分享
点赞

苹果在印度恢复银行卡支付功能,距暂停已逾四年
Bookshop.org确认今年将推出Kobo电子书阅读器支持
WeWard新增"步行模式":走够步数才能解锁应用
X将通过私信通知用户其互动帖子被社区笔记纠错
"慢社交"应用Roost:让消息像真鸟一样飞行
Truecaller与印度电信监管机构就反垃圾电话规则展开公开交锋
Block与46州达成4500万美元和解,涉Cash App欺诈纠纷
欧盟威胁对Meta开出罚款,剑指Facebook和Instagram上瘾性设计
Disney+考虑推出免费流媒体内容层级
HyperTexting:将开放网络变成类社交媒体信息流的新应用
TV Time关闭之际,创始人打造新追剧应用Bingers
Telegram短链域名t.me因制裁合规问题短暂下线后已恢复
