
英特尔向AMD与英伟达GPU发起挑战
英特尔专为高性能计算(HPC)打造的Xe GPU似乎确有一战之力,但能否成功压制住AMD和英伟达还在未知之天。
如今的英特尔公司明显决定走上Alphabet董事长兼斯坦福大学前任校长John L. Hennessy提出的“特定领域架构”战略之路。为此,英特尔已经在CPU、GPU、各类ASIC以及FPGA等领域全面开花。虽然这种到处试水的作法有点“大力出奇迹”的意味,但也确实在塑造异构计算领域带来了不小的吸引力。但很明显,这种方式要求极高的资本密度、耗费大量工程资源,同时也会给软件开发者带来巨大的负担。在今天的文章中,我们就具体聊聊其中一种架构——作为英特尔家族全新补充成员的高性能GPU。
英特尔最近公布了即将推出的数据中心GPU Xe HPC的详细信息,这款产品代号为Ponte Vecchio(PVC)。英特尔大胆暗示,PVC GPU的峰值性能约为当前最快GPU英伟达A100的两倍。2022年,阿贡国家实验室的百亿亿次超级计算机Aurora就将采用PVC与Sapphire Rapids(多区块下一代至强处理器)构建。从这个角度看,这项技术本身应该已经相当成熟。
Ponte Vecchio Xe HPC GPU
英特尔希望用这款GPU产品在高性能计算(64位浮点运算)与AI(8位/16位整数与16位浮点运算)方面对抗AMD与英伟达。Xe HPC采用一种多区块、多进程节点封装方案,采用新的GPU核心、HBM2e存储器、新的Xe Link互连以及使用超过1000亿个晶体管实现的PCIe Gen 5。考虑到实际尺寸,高频工作时的功耗就成了新的问题。但从Xe的设计中可以看出,英特尔很明显是有条有理:封装较小晶片不仅有助于降低开发与制造成本、同时也能缩短产品的上市时间。

Ponte Vecchio采用多区块、多进程节点封装。
Ponte Vecchio预计将于明年年初开始向阿贡国家实验室的Aurora供货,届时将由数万块GPU为这台由美国能源部资助的全球首台百亿亿次级超级计算机提供算力,实际性能至少可达成1.1百亿亿次浮点运算。
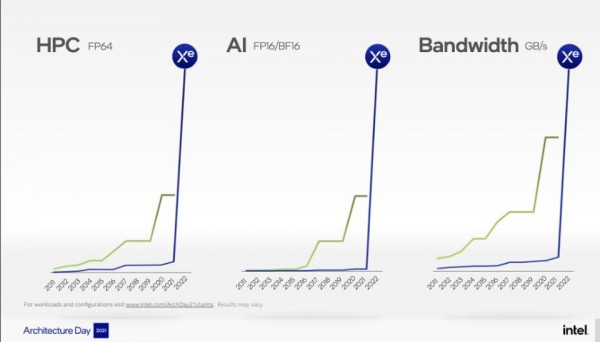
Ponte Vecchio承诺在英特尔的HPC与AI领域发挥重要作用。
初步性能声明无疑令人印象深刻,其表现可达英伟达A100的约两倍,矢量引擎每秒可提供45万亿次FP32触发操作,矩阵处理单元则可实现1468 INT8 TOPS。这款怪物级芯片的功耗约为600瓦,发热量肯定低不了。下图为英特尔公司在今年8月的架构日活动上公布的演示文稿。虽然没有做出横向对比,但这里呈现的肯定是最佳性能,也似乎再次强化了“两倍于A100”的结论。

Xe平台包含片上互连链路与开关,可高效扩展至8 GPU。
另一个有趣的点,在于英特尔会如何对Xe HPC与Habana Labs Gaudi进行区别定位。一种可能的猜测是将Ponte Vecchio推向HPC超级计算,而Gaudi则重点关注云服务商的可扩展训练平台。这很大程度上取决于英特尔打算为两款产品投入多少资源以吸引相应的软件团队。
软件: OneAPI
除了直观的规格与码数之争,英特尔应该还会利用Aurora围绕Ponte Vecchio GPU构建开发者社区,包括将OneAPI全面引入AI与HPC领域。英特尔公司从来没有放弃过为高性能计算和AI提供单一抽象这个雄心勃勃、但又困难重重的目标。在最近的简报中,英特尔公司重申了这方面意图,并带来了不少令人信服的证据。可以看到,OneAPI正在获得市场的认可与接纳。我们虽然担心Habana还是无法支持该软件,但就目前的情况看,这种兼容性也确实不算高优先级任务。

英特尔表示,目前已经有80多款HPC与AI应用程序能够支持早期Ponte Vecchio芯片上的OneAPI。成绩不错,但别忘了英伟达CUDA可是有数百家支持者。
总结
英特尔在GPU方面的成就给我留下了深刻印象。但Ponte Vecchio还需要克服两道难关才能真正取代AMD与英伟达:其一是保持合理的功耗,其二则是实现软件的易用性与高优化度。第二点尤其重要,英特尔必须简化代码并优化模型、降低使用难度,才能让声明的性能水平真正成为用户手中的可用资源。
在我看来,在Pat Gelsinger的英明领导下,Ponte Vecchio无疑有机会成为英特尔进军新时代的先锋与典范。最终表现如何,让我们拭目以待。
来源:业界供稿
好文章,需要你的鼓励


Databricks完成10亿美元K轮融资,估值突破1000亿美元
数据分析平台公司Databricks完成10亿美元K轮融资,公司估值超过1000亿美元,累计融资总额超过200亿美元。公司第二季度收入运营率达到40亿美元,同比增长50%,AI产品收入运营率超过10亿美元。超过650家客户年消费超过100万美元,净收入留存率超过140%。资金将用于扩展Agent Bricks和Lakebase业务及全球扩张。

Meta与特拉维夫大学联手打造VideoJAM:让AI生成的视频动起来不再是奢望
Meta与特拉维夫大学联合研发的VideoJAM技术,通过让AI同时学习外观和运动信息,显著解决了当前视频生成模型中动作不连贯、违反物理定律的核心问题。该技术仅需添加两个线性层就能大幅提升运动质量,在多项测试中超越包括Sora在内的商业模型,为AI视频生成的实用化应用奠定了重要基础。

Predoc获得3000万美元融资,扩展AI健康信息管理平台
医疗信息管理平台Predoc宣布获得3000万美元新融资,用于扩大运营规模并在肿瘤科、研究网络和虚拟医疗提供商中推广应用。该公司成立于2022年,利用人工智能技术提供端到端平台服务,自动化病历检索并整合为可操作的临床洞察。平台可实现病历检索速度提升75%,临床审查时间减少70%,旨在增强而非替代临床判断。

上海AI实验室重磅发布:让AI看图“说人话“的神奇训练法,解决多模态AI与人类价值观对齐难题
上海AI实验室发布OmniAlign-V研究,首次系统性解决多模态大语言模型人性化对话问题。该研究创建了包含20万高质量样本的训练数据集和MM-AlignBench评测基准,通过创新的数据生成和质量管控方法,让AI在保持技术能力的同时显著提升人性化交互水平,为AI价值观对齐提供了可行技术路径。

