
NVIDIA Nemotron 3 系列开放模型: 击穿AI“工程墙”开启“Agentic AI”的“Linux时刻” 原创
2025年,全球AI产业来到了微妙的“分水岭”。
这一年,推理模型(Reasoning Models)的崛起,验证了OpenAI曾隐晦指出的方向——测试时算力(Test-Time Compute)是继预训练参数量、训练数据量之后的“第三种 Scaling Law”。
即通过让模型在输出结果前进行“长思考(Long Thinking)”,利用思维链(CoT)和强化学习(RL)进行自我博弈,AI可以在参数量不变的情况下,获得更高的智能密度。
然而,当工程界“长思考”范式从实验室搬进企业级多智能体(Agentic AI)系统时,却结结实实地撞上了三面厚重的“工程墙”。
01 Agentic AI撞上三面“工程墙”
第一面是“记忆边际的成本墙”。如今的智能体已不再停留在Chatbot形态,更多的是逐渐作为企业的数字员工存在,需要长期处理横跨数月的项目日志、数百万行的代码库,甚至复杂的法律卷宗。
然而,在传统的Transformer架构下,KV Cache(键值缓存)的显存占用,随着序列长度呈二次方(线性优化后依然庞大)增长。这对于超大规模的Token中寻找更优解的Agent而言,单纯的Attention机制意味着更高的显存开销和推理延迟。
第二面是“专家的‘贫富差距’墙”。为在扩大模型参数规模的同时控制计算成本,MoE(混合专家模型)逐渐成为主流选择。然而,在分布式推理场景中,现有的MoE架构普遍面临“专家负载不均(Expert Collapse)”的问题。
理论上,MoE依赖路由器(Router)把不同token分散到不同专家(Expert),以提升吞吐、降低成本。但在实际训练和推理中,由于路由偏置的自强化,让被频繁选中的专家更快收敛、表现更好,于是更容易在下一轮被路由命中,形成正反馈。
但是,在真实业务中的token并不均匀(例如代码、公式、特定领域文本),路由器自然会把这些高频模式集中送往少数专家。
具体来说,在分布式推理中,专家通常绑定在特定GPU或节点上,一旦热门专家达到容量上限,其它token就只能排队等待,无法被“动态转移”。久而久之,MoE 不再是“多专家并行”,而是隐性退化为几个专家在独立承担大部分计算。同时,专家之间的数据路由也带来了巨大的通信开销(Communication Overhead),这在追求低延迟的Agent交互中是较为严重的消耗。
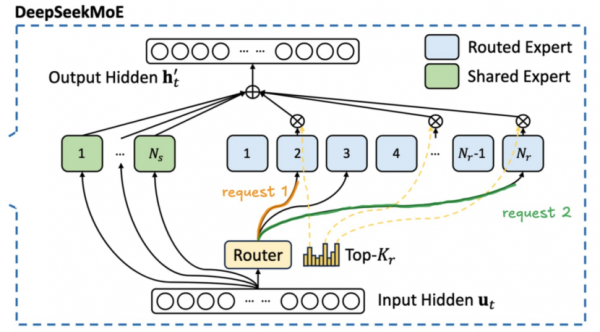
(两个请求token激活了模型的不同部分,需要加载更多权重,导致内存带宽饱和)
截取自:论文《MoE Inference Economics from First Principles》
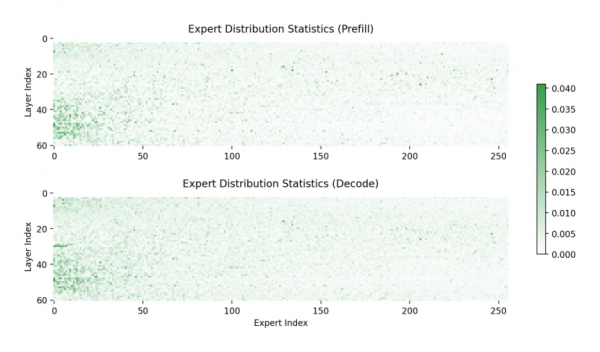
(基于特定数据集的经验观察,专家使用情况的分布不均匀)
截取自:SGLang报告
第三面是“企业信任的黑盒墙”。闭源模型的性能优势,并不足以抵消其在核心业务场景中的不透明性风险。当其被引入金融、医疗、研发等核心场景时,问题便不再只是“好不好用”,而是“敢不敢用”。训练数据的不透明、对敏感信息记忆风险的不确定,以及安全边界难以审计,使得“黑盒”模型在企业级部署中,正从技术更优解,演变为信任成本更高的选项。
这三面“工程墙”,并非理论的缺陷,在既有范式下,通过堆叠参数、拉长上下文,虽然能带来性能提升,但在长期运行、系统延迟和可审计性等企业级要求面前,其工程代价正在显著放大,逐渐暴露出可扩展性的瓶颈。
这也意味着,如今的问题,已不再只是模型是否足够“聪明”,而是底层架构是否具备支撑企业级智能体持续运转的工程弹性。
也正是在这一背景下,NVIDIA在12月15日,发布了NVIDIA Nemotron 3系列(以下简称“Nemotron 3”)开放模型、数据和库,通过Hybrid Mamba-Transformer MoE和Latent MoE等创新架构设计,在系统层面同时回应记忆、负载与信任三重挑战,为“Agentic AI”时代的智能体系统提供了新的工程范式。
NVIDIA 创始人兼首席执行官黄仁勋表示:“开放创新是AI进步的基础。通过 Nemotron,我们将先进 AI转化成开放平台,为开发者提供构建大规模代理式系统所需的透明度与效率。”
02 NVIDIA Nemotron 3击穿Transformer“不可能三角”
Nemotron 3系列开放模型的核心突破,在于其对主流计算范式的解构与重组。
在长文本推理中,业界长期受困于Transformer 的“不可能三角”——长上下文、低显存占用、高推理精度。
坦白来说,Transformer的核心是——自注意力机制(Self-Attention),虽然在捕捉全局依赖和复杂逻辑上无出其右,但其计算复杂度和内存占用是其“短板”。而基于状态空间模型 SSM——Mamba则具有线性的复杂度,擅长以较低的内存开销,处理超长序列。就像高效的流水线工人,可以不知疲倦地处理数百万Token的输入流。
而反观NVIDIA的策略,则是“取长补短”,即Nemotron 3创造性地采用Hybrid Mamba-Transformer MoE架构。
Mamba层可以理解为“长跑运动员”。模型的“主干”大量采用了Mamba层。在处理长文档、历史记录等海量上下文时,Mamba负责信息的压缩与传递,确保KV Cache和 SSM Cache 的增长保持在极低水平。这使得Nemotron 3 能够原生支持 1M(100万)Context Window,且显存占用极低。
Transformer层可以看作“精算师”。在Mamba层之间,交错插入Transformer Attention 层。这些层被战略性地部署在关键位置,负责处理需要高强度逻辑推演、代码生成、复杂数学证明等“高光环节”。
这一设计带来的效率提升无疑是颠覆级的。相较于纯Transformer架构,Nemotron 3 Nano在保持30B参数规模(3B 激活参数)的同时,其缓存使用效率显著提升。这意味着在同等硬件(如单张 L40S)上,企业可以运行更深、更长上下文的Agent。
截取自NVIDIA官网
如果说混合架构仍属于“战术层面的创新”,那么Nemotron 3在模型规模与架构层面的整体设计,则更是面向Agentic AI的系统性重构。
Nemotron 3提供Nano、Super与Ultra三种规模,面向多智能体系统在真实生产环境中的吞吐、稳定性与可扩展性需求而设计。
Nemotron 3 Nano具备 300 亿参数的小型模型,每次运行最多激活30亿参数,适用于针对性、高效的任务。
Nemotron 3 Super具备约1000 亿参数的高精度推理模型,每个token最多激活 100 亿参数,适用于多智能体应用。
Nemotron 3 Ultra具备约 5,000 亿参数的大型推理引擎,每个token最多激活 500 亿参数,适用于复杂的 AI 应用
其中,Nemotron 3 Nano的推理吞吐量已较Nemotron 2 Nano 提升约4 倍。
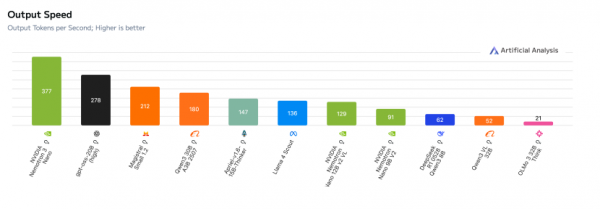
截取自NVIDIA官网
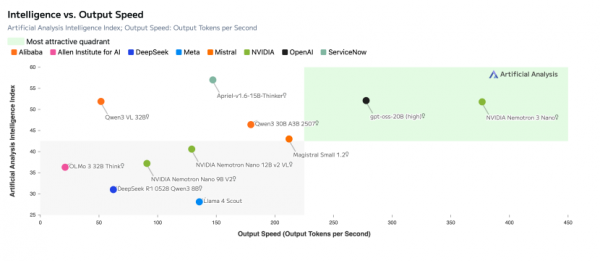
截取自NVIDIA官网
然而,真正体现其战略的是,在Nemotron 3中引入的突破性的异构潜在混合专家 (MoE) 架构,则是不折不扣的“战略武器”。
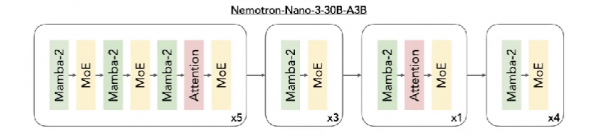
Nemotron 3 混合架构(截取自NVIDIA官网)
传统的MoE架构在Token层面进行路由(Token Routing)。每个Token在经过每层时,都需要在成百上千个专家中进行选择。在分布式系统中,这意味着海量的数据需要在不同的 GPU显存之间频繁搬运,导致通信带宽成为瓶颈(Memory Bandwidth Bound)。
Latent MoE 引入了“潜在表示论”,其工作流程堪称对数据的“空间折叠”:
首先,在投影(Projection)阶段,输入的Token向量被映射到维度更低的潜在空间;随后,在这一压缩后的低维空间中,路由器(Router)完成专家的选择与计算,实现隐式路由;最后,计算结果再通过投影层还原回原始维度,回到主干网络。
这一方法允许模型在相同计算成本(FLOPs)下,调用4倍数量的专家。相当于在原本拥堵的城市地面交通之外,新增了一条地下高速通道,显著缓解了大规模集群中 All-to-All通信带来的压力。
在推理解码端,Nemotron 3 引入了多Token预测(MTP) 技术,允许模型在一次前向传播中预测未来的多个Token,显著提升推测性解码的接受率。
更为关键的是底层精度的突破。Nemotron 3 Super和Nemotron 3 Ultra直接采用 NVFP4(4位浮点格式)进行预训练。NVIDIA为此设计了更新的NVFP4算法,并在25T Token的内部数据集上进行了稳定性测试,确保在4-bit精度下训练依然稳定收敛。
这种原生低精度训练,使得其在Blackwell架构上,训练和推理的吞吐量将获得硬件级的原生加速,且没有“训练后量化(PTQ)”的精度损失。
03 “黑盒”变“白盒” NVIDIA开启Agent“功能性”范式迁徙
如果说架构决定了模型的上限,那么数据则决定了模型的实际可用性。NVIDIA在 Nemotron 3的创新上展示了其对功能性正确性(Functional Correctness)的极致追求,并推出了一整套“Nemotron Agentic Safety Dataset”的数据资产。
坦白讲,OpenAI证明了RL在推理中的核心作用,而NVIDIA 则通过开源NeMo Gym将这一过程标准化。
NeMo Gym是专为构建和扩展强化学习环境的开源库,不仅支持传统的 RLHF,更引入了NeMo RL库,支持在多种环境中对模型进行后训练。
NVIDIA此次特别发布了10个Gym环境(Gym Environments),用于训练模型生成正确的工具调用、编写功能性代码或生成满足可验证标准的多步骤计划。结合 NeMo Evaluator,开发团队可以自动化地验证模型的安全性与性能。
工具链与训练环境只是前提,真正决定模型能力上限与安全边界的,仍然是数据本身。
然而,在当前的开源生态中,长期存在“只开权重、不开数据”的结构性缺口。也正因如此,NVIDIA此次选择了近乎“颠覆性”的开放方式。
具体而言,其一是3T Token预训练数据。NVIDIA发布了全新3万亿Token规模的预训练数据集,重点覆盖代码、数学与推理等高价值领域,并通过合成增强与系统化标注管道进行质量强化,为推理模型提供更高密度的基础语料。
其二是18M 训练后样本(Post-training Samples)。规模约1300万样本的训练后语料库,用于监督微调(SFT)与强化学习阶段,且直接支持Nemotron 3 Nano 的对齐与能力收敛。
其三是Nemotron智能体安全数据集。包含近11000条真实AI智能体工作流,用于缓解多智能体系统在真实运行中可能出现的新型安全风险。
此外,NVIDIA还同步开源了Data Designer工具,帮助开发者构建、处理并管理自有数据集。通过该工具链,开发者不仅能够复现实验结果,还可以在 GitHub 代码库中直接访问完整的训练方案(Recipes)、分词器配置与长上下文设置,使 Nemotron 3 从“可用模型”,转变为高度透明、可审计、可复现的“白盒平台”。
截取自NVIDIA官网
04 激发“飞轮效应” NVIDIA生态疆域不断拓展
如果说Nemotron 3 Nano证明了NVIDIA在模型效率与工程可用性上的极限能力,那么真正让这一模型体系产生“外溢效应”的,则是其被快速吸纳进真实产业生态的能力。
从开发者工具链、推理引擎支持,到企业级平台、云基础设施与主权AI,NVIDIA围绕Nemotron 3构建起了覆盖初创公司、企业与主权AI体系的Agentic AI网络。
Agentic AI的创新应用并不仅产生在大型企业内部,更在初创公司与研究型团队之中产生。在这一层面,General Catalyst与Mayfield 旗下的多家投资组合公司,已开始基于 Nemotron 3 探索面向人机协作的AI Agent应用形态。
Mayfield管理合伙人Navin Chaddha 指出,NVIDIA的开放模型堆栈与初创加速计划,使初创团队能够在模型、工具与基础设施层面以更低成本完成试验、形成差异化,并加速规模化落地。
在企业级场景中,Nemotron3 的价值进一步显现。其早期用户已覆盖咨询、软件、制造、安全与云计算等多个关键行业,包括埃森哲、Cadence、CrowdStrike、德勤、安永、Oracle、ServiceNow、西门子、新思科技与Zoom等。
在具体落地案例中,相关企业已将Nemotron 3 嵌入自身的核心业务系统之中:
ServiceNow将Nemotron 3 与其智能工作流平台结合,发布了重新训练的推理模型 “April”,用于企业级自动化决策。
CrowdStrike基于Nemotron 构建了安全运营智能体“Charlotte AI”,以释放其安全数据的推理价值。
Perplexity通过智能体路由机制,将工作负载定向至Nemotron 3 Ultra 等高性价比模型,以优化Token经济结构。
在主权AI层面,英国UK-LLM 使用Nemotron数据集进行威尔士语训练,展示了其在多语言与本地化AI体系建设中的潜力。
为了进一步降低使用门槛,NVIDIA还将Nemotron 3快速推向主流云与推理生态。
在推理服务侧,Hugging Face、Baseten、Fireworks、Together AI、OpenRouter等平台已率先上线 Nemotron 3 Nano,使开发者能够以API方式直接调用模型能力。
在企业级平台层面,Couchbase、DataRobot、H2O.ai、JFrog、UiPath 等也已完成集成,将Nemotron 3纳入既有数据、MLOps与自动化工作流之中。
在云基础设施层,NVIDIA同样选择了“先铺路、再放量”的策略。Nemotron 3 Nano已通过Amazon Bedrock以无服务器方式对外提供,并计划陆续登陆Google Cloud、Microsoft Foundry、CoreWeave 等云平台,使模型能够在不同算力与合规环境下灵活部署。
与此同时,NVIDIA还同步启动了 “Nemotron 模型推理挑战赛”,鼓励开发者社区基于其开放模型与数据集,进一步探索推理能力与多智能体系统的边界。
NVIDIA方面透露,Nemotron 3 Super和 Ultra预计将于2026年上半年推出。
05 写在最后
Nemotron 3的推出,或许意味着开源大模型进入了下一个“Linux 时刻”。
如果在2023 年,开源模型还在努力模仿 GPT-3.5 的“对话能力”;那么现在,以Nemotron 3为代表的新一代开源模型,已经开始在架构层面针对Agentic AI 的核心痛点——无限记忆、极速推理、工具调用——进行原生的“基因改造”。
混合Mamba-Transformer架构的落地,证明了Transforme并非AI的终局;Latent MoE 的引入,展示了算力效率挖掘的深邃潜力。更重要的是,NVIDIA这一次不仅给出了“鱼”(模型权重),更给出了“渔网”和“海图”(全栈数据与训练方案)。这种“白盒化”,为全球AI行业提供了一套关于如何构建企业级智能体的标准范式。
对于开发者而言,Nemotron 3不再是需要费力调优的半成品,而对于NVIDIA自身而言,这不仅是对 Blackwell 硬件的护航,更是其在应用层与算力层之间,定义的“中间件”标准。
当“长思考”不再受限于显存墙,当“黑盒”逐渐透明,2026年的AI赛道,或许将不再热衷于刷榜,而将爆发于能够产生复利的业务场景深处。
来源:至顶网计算频道
好文章,需要你的鼓励


谷歌推出AI购物智能体,帮你“一站式“购物体验升级
谷歌在I/O开发者大会上发布"通用购物车"功能,基于通用商务协议(UCP)整合YouTube、Gmail、Gemini等平台的购物数据,支持Target、Shopify、Wayfair等主流零售商。AI代理可自动检测商品兼容性、推荐优惠信用卡、比价提醒,并在用户授权下自动完成日常采购。该功能旨在打通"加入购物车"到"完成结账"的全流程,实现个性化、无摩擦的购物体验。

浙大、港科大等联合机构告诉你:AI学“看“3D场景,到底该怎样聪明地“选角度“?
这项联合研究提出了COVER方法和CM-EVS数据集,用贪心算法从3D场景中智能筛选全景视角,每场景仅需25帧即可完整覆盖室内场景,并附完整溯源日志。


伦敦大学学院等多机构联合揭示:AI“调音旋钮“让大模型推理训练不再崩溃
HolderPO通过引入可调参数p的霍尔德均值替代固定的算术平均,解决了大模型推理训练中信号放大与稳定性之间的根本矛盾,配合动态退火策略在数学推理和代理任务上均创造了新的最优记录。
2025
12/16
18:09
分享
点赞

Apple Music发布公开信:致力于在AI时代维护音乐公平生态
NHS十年计划的成功关键:数字健康必须达到临床标准
xAI与Anthropic计算资源合作协议,揭示AI算力独立商业化新趋势
利用Ubicept Photon Fusion提升CMOS夜间成像性能
Humanoid与制造业巨头博世达成战略合作,推进人形机器人量产
企业网络基础设施是否已为AI工作负载做好准备?
AI遭Z世代抵制:CIO面临的人才培养危机
Flytrex在达拉斯开设无人机制造工厂,加速扩张外卖配送网络
Brain Corp与加州大学圣地亚哥分校合作推进物理AI基础智能层研究
哈丁视角:工厂竞争的现实法则——执行力才是制胜关键
Doozy Robotics宣布全球扩张,以AI人形机器人构建工厂自动化劳动力
华为AI DC全栈方案发布:以数据觉醒,驱动产业智能跃迁
