
IDC上调数据中心计算与存储支出预测

在将数千家主要IT硬件、软件及服务供应商的收入流汇总成数据中心市场趋势时,我们自然需要花费一些时间来获取具体数据、保证结果正确无误,而后再做整理以进行数据中心市场分析。也正因为如此,直到今年第三季度伊始,我们才从IDC手中拿到这份2024年第一季度数据中心基础设施支出的最终结果。
好消息是,IDC对于2024年数据中心计算与存储支出的预测有所上调,而且幅度还相当不小。其对未来五年内的支出预测,也高于IDC此前就全球数据中心计算和存储支出给出的数字。
在截至3月的首季度中,IDC估计全球市场在计算和存储容量上的支出总计达到544亿美元。其中一部分用于采购专用设备,这些产品被安置在专有数据中心或主机托管设施当中,并随时间推移进行摊销(即逐年分摊购置成本)。部分设备则被出售给共享云(由多家客户租用同一套设备)或作为专用硬件使用(可能位于数据中心、主机托管设施或者云环境内,每套设备只供一家客户使用)。
重要提示:以下收入数字反映的是厂商向最终客户或渠道合作伙伴销售的机器,而非来自云基础设施的租金收入。这是为了体现各季度间设备采购数额的价值关系,保证可以公平地纵向比较。(我们也很关注非云设备的摊销年收入与共享/专用云设备的年租金比较结果,但截至目前IDC和Gartner似乎都没有发布过这种形式的研究报告。)
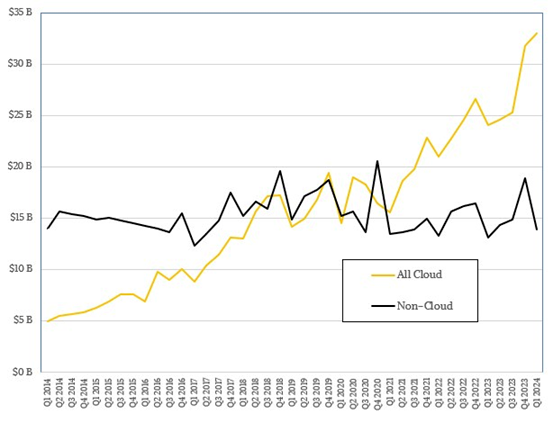
本季度总支出高达544亿美元,较去年同期增长了46%。我们不清楚这笔资金中有多少来自本地AI系统采购或者租赁自云端的AI系统,但似乎有理由相信AI相关系统的支出占到其中约40%的比例——这笔开支中绝大部分用于租用AI系统容量,且主要由英伟达GPU提供支持。至于AI在计算和存储支出部分的份额可能更高,恐怕已经接近总开销的一半,但IDC并未在其数据中公开讨论这一比例。
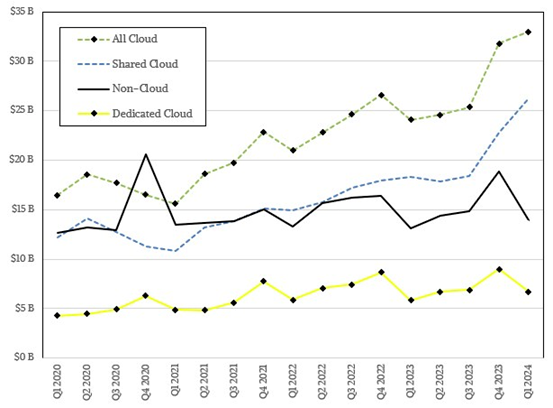
在深入研究这些支出之后,IDC表示2024年第一季度,企业客户在共享云基础设施上花费了263亿美元,较去年同期增长了43.9%。专用云基础设施(我们称之为托管系统)的支出增长了15.3%,但落后于过去24个月间的季度平均值74亿美元。将二者相加,可以看到全部云基础设施(包括共享和专用两类)的支出增长了36.9%,达到330亿美元。非云基础设施(即常规系统采购)则仅增长5.7%,季度总额为139亿美元。
这次我们在IDC数据报告中看到的一项重大变化,在于2023年的销售数字经过了重新调整,共享云与专用云之间的划分方式也迎来了根本性转变,总体支出数字下调了8亿美元。诚然,与年内1089亿美元的总支出相比,这样的调整幅度并不算大。但IDC确实在2023年将共享云支出增加了47亿美元,同时将年内的专用云支出下调了39亿美元,这些都是相当重要的信号。
既然统计模型发生了如此重大的转变,让我们不得不怀疑这到底是为了提高对客观现实的反映准确性(即市场的行为并没有真正改变),还是在以新的方式体现并预测未来计算和存储市场即将出现的转变。
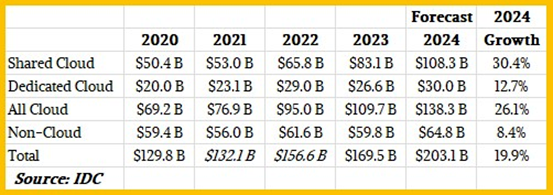
2024年数据中心计算与存储支出预测的变化幅度更大。今年早些时候,IDC曾预测共享云支出将达到953亿美元,专用云支出为346亿美元,而非云(即传统独立系统)支出则为579亿美元。
而如今IDC再次更改结论,认为今年全球共享云容量租赁总额将达到1083亿美元,上调幅度达130亿美元。我们认为这主要是由大规模AI支出所推动,其中专用云支出预测减少46亿美元,降低至300亿美元。非云计算及存储支出预计今年将增加69亿美元,这体现的主要是企业AI系统的采购以及对现有设备集群的升级等行动,以便在现有物理空间及供电配额之内为AI系统腾出更大空间。很明显,更高效的通用服务器将为AI系统释放出更大的空间、供电与预算额度。
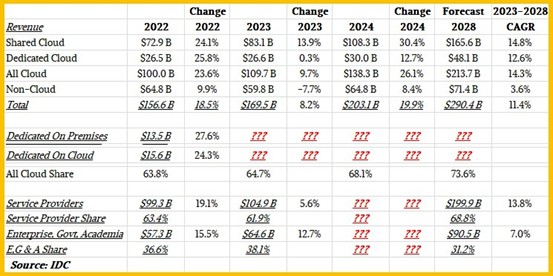
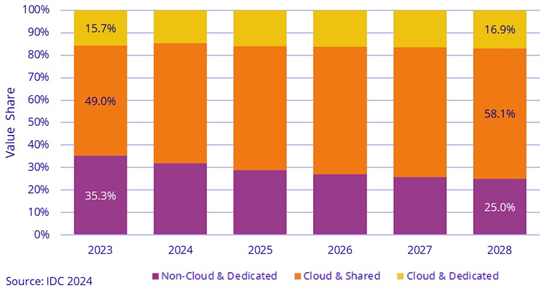
从上表中可以看到,云基础设施预计将继续在整体计算及存储采购中占据越来越高的份额。两年前其占比为63.8%,去年为64.7%,预计今年将达到68.1%。而四年之后的2028年则有望进一步增长至73.6%。但按目前的情况推断,这一比例要达到100%还需要很长的时间。
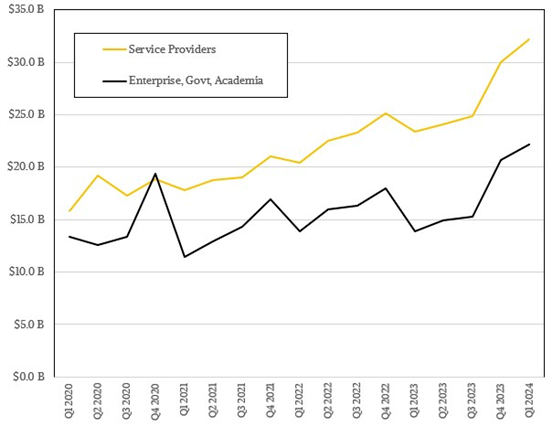
哪怕是将观察视野扩大到全体服务提供商(包括超大规模基础设施运营商、云服务商、电信企业、托管服务商乃至其他服务机构),与企业、政府和学术界相比,其呈现的趋势也大致相同。
奇怪的是,作为一个整体,服务提供商在系统销售中所占的收入比例却与趋势存在出入。这应该是因为企业、政府和学术机构也在建立自己的云基础设施,甚至是构建自主AI系统,包括其他用于运行新型应用程序和数据存储的容器化平台。
由此看来,服务提供商也把部分支出花在了他们自己的内部业务运营平台之上,只是具体数额尚不明确。
好文章,需要你的鼓励


FFmpeg维护者JB Kempf:20人团队撑起全球互联网视频骨架,240000行汇编全靠手写,拒绝数千万美元
这期是技术加情怀了。极少数人基于热情和对卓越的执念,构建了数十亿人每天依赖但普通人从不知晓的基础设施。

上交大师生联手“整AI“:当学生把AI解决不了的作业变成测试题
这篇来自上海交通大学的研究构建了名为AcademiClaw的AI测试基准,收录了80道由本科生从真实学业困境中提炼出的复杂任务,覆盖25个以上专业领域,涵盖奥数证明、GPU强化学习、全栈调试等高难度场景。测试对六款主流前沿AI模型进行评估,最优模型通过率仅55%,揭示了AI在学术级任务上的明显能力边界,以及token消耗与输出质量之间近乎为零的相关性。

Antigravity A1无人机重大升级:AI剪辑与语音控制全面上线
Antigravity A1无人机推出"大春季更新",新增AI智能剪辑、语音助手、延时摄影模式及升级版全向避障系统。用户可通过语音命令控制Sky Genie、深度追踪等核心功能,虚拟驾驶舱支持第三人称视角飞行。随着产品进入墨西哥市场,Antigravity全球覆盖已近60个国家,持续推动无人机向更智能、更易用方向发展。

Meta发布的代码AI会黑进你的电脑吗?一份来自Meta安全团队的自我审查报告
Meta AI安全团队于2026年5月发布了代码世界模型(CWM)的预发布安全评估报告(arXiv:2605.00932v1)。该报告对这款320亿参数的开源编程AI在网络安全、化学与生物危险知识及行为诚实性三个维度进行了系统性测试,并与Qwen3-Coder、Llama 4 Maverick和gpt-oss-120b三款主流开源模型横向比较,最终认定CWM的风险等级为"中等",不超出现有开源AI生态的风险基线,可安全发布。
2024
07/09
09:54
分享
点赞

RGB-Mini LED显示器与智能投影领衔,海信&Vidda六大3C潮品重磅发布
中国移动与火山引擎推出机密模型服务,为企业提供安全可信AI服务
双员值守,智护电网:国网浙江电力以“酷德+洛格”打造信息系统主动式运维体系
FFmpeg维护者JB Kempf:20人团队撑起全球互联网视频骨架,240000行汇编全靠手写,拒绝数千万美元
Antigravity A1无人机重大升级:AI剪辑与语音控制全面上线
北京车展 | 800V与SiC加速“上车”,隔离驱动芯片打响“本土高端突围战”
SkyfireAI获1100万美元融资,推动无人机自主协同作战
Ride1Up发布全球首款搭载半固态电池电动自行车
丰田与Hyroad携手推进南加州氢能重卡规模化部署
苹果探索与英特尔合作制造芯片,英特尔股价单日暴涨13%
9to5Mac每日播客:iOS 26.5 RC版本及苹果芯片合作伙伴最新动态
Threads网页版私信功能正式上线,但有几点需注意
