
开放解耦的先进智算网络,是构建多元智算体系的关键
大模型时代对算力的需求永无止境,大规模智算中心建设如火如荼。随着人工智能技术在各领域应用的快速发展,以及Sora、Gemini 1.5 Pro的面世,将进一步提高算力基础设施的建设要求,激活算力技术的不断创新和迭代升级。如今,算力市场已形成庞大的生态系统,涵盖CPU、GPU、DPU、FPGA等专用芯片,各种形态的交换机、光模块/线缆等连接介质,以及各服务提供商交付的算力运营、算力调度、算法交易平台等。对企业而言,如何博各家之所长,构建出多元融合的智算体系,是赢得未来竞争、享受智算红利的关键所在。
异构算力网络成为“必选项”
随着智算热度持续提升,以 AI为核心的算力需求激增。为实现计算效力最大化,多元异构算力将成为必然趋势。异构算力体系可以充分发挥各种计算设备的优势,为用户提高智算效率、降低采购成本、提升系统安全性。但在实际场景中,大多数客户对于智算场景都是初次接触,并不像传统ICT基础设施建设那样可以轻车熟路的进行规划、采购、部署。因此,解决异构组件间的互联问题,是打通整体方案的重要前提,那么网络是否做好了承担重任的技术储备呢?
用网络打通异构算力的关键能力要求
通过数十年信息技术的发展,以太网具备拉通和兼容多种不同终端的能力已经被充分验证。面对智算的异构需求,以太网一方面需在网络侧解决端口密度、设备形态、通道标准、传输介质的扩展性和兼容性,另一方面需在计算侧筛选AI服务器网卡规格,为智算业务提供高性能算力,这种“多元可靠联接”的能力正是打通异构算力所需要的。
在高性能网络领域,无损以太网(RoCE)是一个快速普及且被大众所认可的技术,其在成本、未来演进和生态丰富度上具备天然优势。当RoCE发展到智算网络时代,连接非智能网卡、智能网卡、可编程智能网卡等不同能力的网卡时,以“场景化网络调优”的模式解决Hash极化问题,降低网络拥堵风险,成为智算网络构建无损能力的关键。
此外,智算网络如果脱离了与算力的联动,那就是孤立、被动的,为确保智算业务有序的平稳发展,网络必须与算力调度平台联动起来。而国内大多算力厂商没有配套的网络设备和平台,因此,想用网络打通异构算力,则必须具备与多家厂商的CCL(集合通信库)的兼容对接能力,将算力需求转译为网络配置,也就是所谓的“异构算网联动”。
综上所述,要打通异构算力之间的高速网络通道,必须具备“多元可靠联接、场景化网络调优、异构算网联动”三大关键能力,这也是算力产业实现创新发展的重中之重。
聚焦异构算力组网痛点,新华三提出开放解耦的智算网络
面对网算之间互相协同推进的发展态势,新华三集团在“多元可靠联接、场景化网络调优、异构算网联动”等方面加速突破,积极探索打通异构算力的开放网络。
- 多元可靠联接
新华三集团进行了丰富的智算产品布局,提供了开放性、兼容性、扩展性、稳定性极强的网络环境和端到端异构互联保障,全方位满足客户需求。
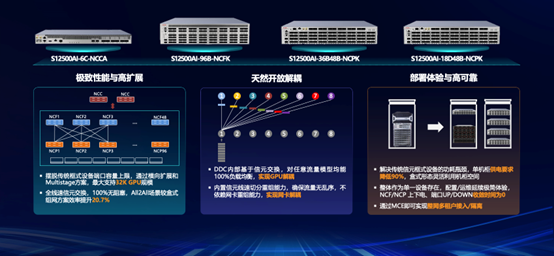
新华三长期以来都致力于推动国内高速网络技术的发展,在200G/400G/800G产品的面世时间上都处于国内乃至业界领先地位。在智算场景下,新华三的产品布局也是业内最丰富的。从产品形态上看,新华三可提供从100G到800G多种形态的框式、盒式产品,端口密度覆盖完善,能够满足不同规模智算客户的组网需求。从1K GPU到512K GPU的场景下,客户可以平滑的选用新华三的单框、盒盒、框盒、三层盒盒等不同的组网架构,实现成本与规模的最优匹配。
从绿色节能角度来看,新华三产品可同时支持LPO和液冷技术,LPO技术是指通过设备内部的信号稳定器件和设计,来替代光模块中的DSP芯片,降低DSP带来的功耗和时延,亦可规避DSP芯片的供应风险。而液冷技术可将关键芯片的大量发热通过液冷带出设备,配套的风扇仅用于其他非关键器件的散热,转速和耗电都将大幅减少。
此外,新华三拥有业界最开放的生态合作环境,各条产品线都采用了多家合作伙伴的交付件,包括GPU、网卡、光模块、交换芯片,由此也为新华三带来了天然优势——能够代替客户验证异构算力环境的兼容性。对客户而言,选择异构方案最大的阻力来源于实施效果,能否互联互通,以及互通后的性能、可靠性是否能支撑业务需求,是实际存在的风险。而新华三的能力就是利用自身的生态优势,为客户提供端到端的异构互联保障,确保客户从新华三验证过的交付件库中选择GPU、网卡、光模块、交换机,即可在实际场景中放心互联。
为此,新华三还设计了一套《智算网络异构连通专项测试》标准,专门用于验证不同智算组件之间的互通性,丰富的测试例覆盖了如下验证能力。

- 场景化网络调优
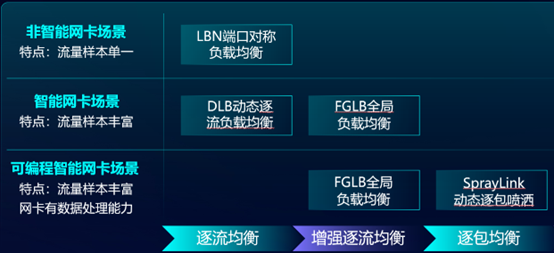
在“场景化网络调优”方面,新华三集团通过端口对称Hash技术LBN、动态负载均衡技术DLB、链路喷洒技术SprayLink、全局负载均衡技术FGLB等技术满足了客户不同智算场景的技术需求,实现了数据中心超高带宽利用率的无阻塞转发。
以“端口对称Hash技术LBN”为例,对于智算网络中的每一台设备而言,网络调优的最终目标,就是下行端口接收的流量,能够有确保的通过上行带宽资源转发出去。实现这个目标有一个最简单的方式,就是为每一个下行口指定一个同速率的上行口,其他下行口的流量不能从这个上行口去转发,形成独占的上行资源,这个技术即为LBN。
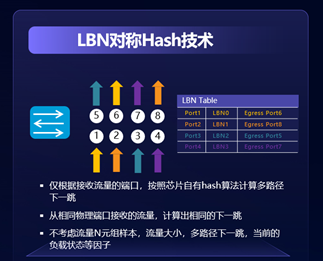
当网络和业务规模超出LBN可覆盖的能力时,需要通过“引入新变量”和“分割单一流”解决Hash极化问题。所谓“引入新变量”,即为在Hash过程中引入出端口负载情况(队列长度),提升队列更短的出端口优先级,就可以将流更多的分摊到空闲端口上;所谓“分割单一流”,即为在出端口Hash时,针对子流做Hash,引入当前出端口的负载,便可以将不同时间段到达的子流Hash到当前最空闲的端口发送。
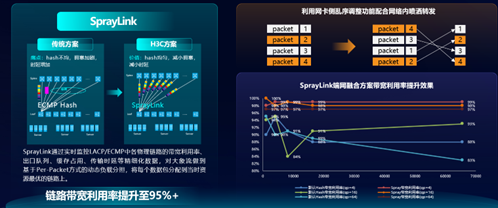
当一条大流连续到达交换机的时候,“链路喷洒技术SprayLink”的价值便得到了彰显。 SprayLink通过实时监控LACP/ECMP中各物理链路的带宽利用率、出口队列、缓存占用、传输时延等精细化数据,对大流做到基于Per-Packet(逐包)方式的动态负载均衡,将每个数据包分配到当时资源最优的链路上。通过实测,采用SprayLink可以使多条链路的总带宽利用率达到95%以上,比传统Hash方法提升明显。但是SprayLink存在流量到达接收端的乱序问题,需要接收端的网卡支持乱序重排技术才能匹配。
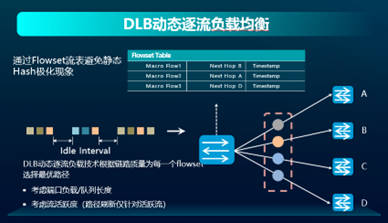
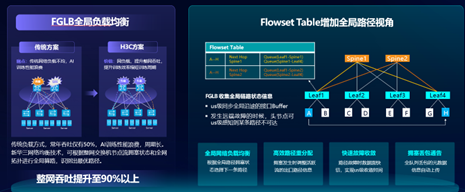
上述几种负载均衡技术,看似已完整的覆盖了所有场景,但其只能根据设备本地的负载情况进行选择,对于发出的数据在剩余路径上的传输质量,则没有判断依据。而新华三的全局负载均衡技术FGLB,能够让每台设备都能够拥有全局视角,了解自己出接口的下一跳,乃至下一跳到再下一跳的链路负载情况,来辅助决策本地的负载结果。
新华三认为,目前最优的负载均衡技术是DDC(Disaggregated Distributed Chassis分布式解耦机框)。它能将传统框式交换机的主控、网板、线卡分解为分布式的模块化部件,以提高网络的灵活性、可扩展性和性能。DDC基于信元交换,任何协议的流量在进入DDC架构时都可被切成等分大小的信元,在内部多条链路上负载,完全解决了Hash极化问题,可以说是100%的负载分担。在流量发出时,信元又将会被重组为原始数据。信元交换无视数据协议,不会产生乱序,对GPU和网卡都是天然解耦的。此外,DDC架构扩展性强,传统框式设备无论如何设计,其容纳的端口都是有限的。而将其拆解之后,通过横向扩展可以支持数千个200G/400G端口,这是框式设备无法实现的,也可以大幅降低部署难度和功耗。新华三DDC产品拥有独立的高性能控制平面,可以实现网元失效后us级别的收敛,以及网元上线的快速即插即用,可靠性和灵活度领先业界。
众所周知,实现全场景网络调优是企业提升链路效能的关键,新华三依托其领先的负载均衡技术,通过丰富的现网实践,总结出了以下场景化匹配应用建议。
- 异构算网联动
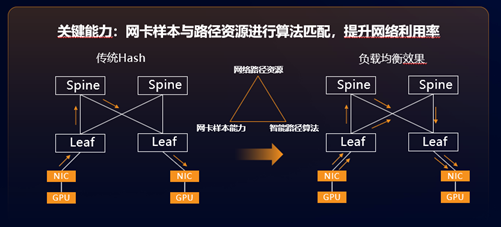
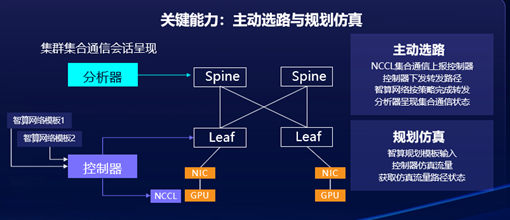
在“异构算网联动”方面,新华三在“调整网卡QP能力与网络联动”、“算网主动选路与路径仿真技术”两大方面进行了实践探索。
关于“调整网卡QP能力与网络联动”,新华三通过识别不同网卡的样本能力(QP规格),结合当前网络可用路径数量和带宽的资源,以及自研的算法,提供了一种端到端的负载优化机制。当训练任务开始时,两张网卡之间建立数据连接,在AI服务器内部的agent就会将报文特征等信息传递到控制器,同时控制器根据当前网络的资源,设置网卡的QP规格,为一对Peer建立多对QP,解决路径中设备Hash不均问题。
关于“算网主动选路与路径仿真技术”,新华三通过算网的协同机制,实现了一种主动选路的功能。当一个CCL发起新的互通请求时,新华三的网络分析器会收集当前所有链路流量负载情况,并根据自研的智能选路算法,选出对于该互通连接最高效的路径,将配置下发到交换机,实现按策略的转发,避免传统路由协议选路条件粗放的问题。同时新华三还提供路径仿真能力,对于主动选路效果,可以在分析器内部通过NFV的形式进行真实流量模拟,来验证策略下发效果,验证后再下发到真实设备上。
面向未来,在算力爆发的时代,新华三集团将始终秉承开放共赢的理念,通过多元可靠联接、场景化网络调优、异构算网联动三大核心能力,解决客户在异构算力组网过程中遇到的各种问题,与生态合作伙伴、行业客户一起,打造繁荣、开放的智算生态体系。
好文章,需要你的鼓励


Flytrex无人机携手达美乐,可一次性送达两个大号披萨
无人机食品配送服务商Flytrex与全球知名披萨连锁品牌Little Caesars宣布合作,推出全新Sky2无人机,最大载重达4公斤,可一次配送两个大披萨及饮料,满足全家用餐需求。Sky2支持最远6.4公里的配送范围,平均从起飞到送达仅需4.5分钟。首个试点门店已在德克萨斯州怀利市上线,并实现与Little Caesars订单系统的直接集成。

AI助手越权了?南加州大学等机构揭示大模型代理的“权限失控“问题
FORTIS是专门测量AI代理"越权行为"的基准测试,研究发现十款顶尖模型普遍选择远超任务需要的高权限技能,端到端成功率最高仅14.3%。

欧洲最大3D打印公寓楼提前数月竣工
法国社会住房项目ViliaSprint?已正式完工,成为欧洲最大的3D打印多户住宅建筑,共12套公寓,建筑面积800平方米。项目由PERI 3D Construction使用COBOD BOD2打印机完成,整体工期较传统建造缩短3个月,实际打印仅用34天(原计划50天),现场操作人员从6人减至3人,建筑废料率从10%降至5%。建筑采用可打印混凝土,集成光伏板及热泵系统,能源自给率约达60%。

荷兰Nebius团队:给AI“起草员“瘦身,大模型推理速度最高提升5倍的秘密
荷兰Nebius团队提出SlimSpec,通过低秩分解压缩草稿模型LM-Head的内部表示而非裁剪词汇,在保留完整词汇表的同时将LM-Head计算时间压缩至原来的五分之一,端到端推理速度超越现有方法最高达9%。
2024
07/01
11:14
分享
点赞

欧洲最大3D打印公寓楼提前数月竣工
彼亚乔携手迪士尼推出Grogu主题自主跟随货运机器人
Okta将AI智能体安全管理扩展至Amazon Bedrock并向第三方身份提供商开放
苹果13英寸iPad Pro Magic键盘键盘亚马逊历史低价,直降25%
WhatsApp iOS版Liquid Glass界面设计正式向更多用户推送
OpenAI为ChatGPT Pro推出个人财务管理新功能
赛格威全新Xaber 300电动越野摩托车正式开售,最高时速达96公里
OpenAI再度重组高管架构,全力押注AI智能体战场
出门在外也能用!OpenAI 将 Codex 接入 ChatGPT 移动端
Google Gemini应用图标迎来细微配色调整
Synetic在2026嵌入式视觉峰会上发布LYNX计算机视觉SDK
生数科技发布世界动作模型Motubrain,为机器人智能带来"无限可能"
