
英特尔至强6处理器、Gaudi 3 AI加速器 Intel Vision 2024大会带来重磅发布 原创
我们说AI正在重塑各行各业,半导体产业也是,作为“卖铲人”,芯片企业更是火力全开。
美国当地时间4月9日,在Intel Vision 2024大会上,英特尔带来诸多产品更新,其中包括我们熟悉的至强处理器和Gaudi AI加速器。

品牌焕新,英特尔至强6
在数据中心领域,英特尔至强也迎来全新命名,即英特尔至强6。配备能效核(E-cores)的英特尔至强6处理器将于2024年第二季度推出,提供卓越的效率,配备性能核(P-cores)的英特尔至强6处理器将紧随其后推出,带来更高的AI性能。

其实全新至强6不只是品牌焕新那么简单,配备能效核的英特尔至强6处理器(代号为Sierra Forest)与第二代英特尔至强处理器相比,每瓦性能提高2.4倍,机架密度提高2.7倍。

而配备性能核的英特尔至强6处理器(代号为Granite Rapids)包含了对MXFP4数据格式的软件支持,与使用FP16的第四代英特尔至强处理器相比,可将下一个令牌(token)的延迟时间最多缩短6.5倍,能够运行700亿参数的Llama-2模型。
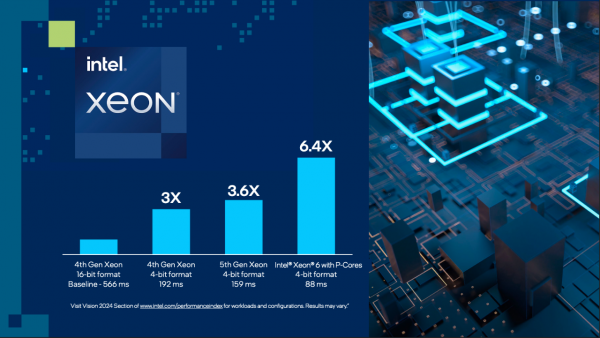
对标NVIDIA,Gaudi 3
Gaudi在英特尔是一个独特的存在。

迭代到Gaudi 3,与上一代产品相比,英特尔Gaudi 3将带来4倍的BF16 AI计算能力提升,以及1.5倍的内存带宽提升。

英特尔Gaudi 3预计可大幅缩短70亿和130亿参数Llama2模型,以及1750亿参数GPT-3模型的训练时间。此外,在Llama 7B、70B和Falcon 180B大语言模型(LLM)的推理吞吐量和能效方面也展现了出色性能。

英特尔Gaudi 3提供开放的、基于社区的软件和行业标准以太网网络,允许企业灵活地从单个节点扩展到拥有数千个节点的集群、超级集群和超大集群,支持大规模的推理、微调和训练。英特尔Gaudi 3将于2024年第二季度面向OEM厂商出货。
AI开放系统战略
在产品更新的同时,英特尔也公布了面向开放的、可扩展的AI系统的战略,其中包括硬件、软件、框架和工具。英特尔让广泛的AI开放生态系统参与者,如设备制造商、数据库提供商、系统集成商、软件和服务提供商等,能够提供满足企业特定生成式AI需求的解决方案。与此同时,亦让企业与他们已知、信任的生态系统合作伙伴展开合作并采取相应解决方案。
英特尔联合Anyscale、Articul8、DataStax、Domino、Hugging Face、KX Systems、MariaDB、MinIO、Qdrant、RedHat、Redis、SAP、VMware、Yellowbrick和Zilliz共同宣布,将创建一个开放平台助力企业推动AI创新。这一凝结全行业力量的计划旨在开发开放的、多供应商的生成式AI系统,通过RAG(检索增强生成)技术,提供一流的部署便利性、性能和价值。RAG可使企业在标准云基础设施上运行的大量现存专有数据源得到开放大语言模型(LLM)功能的增强,加速生成式AI在企业中的应用。
在该计划的初始阶段,基于安全的至强处理器和Gaudi解决方案,英特尔将面向生成式AI进程(pipelines)推出参考实现,发布技术概念框架,并继续增进英特尔Tiber开发者云平台基础设施的功能,以便为RAG及未来进程的生态系统开发和确认打下基础。英特尔鼓励生态系统进一步参与到这一开放平台的创建中来,以促进企业采用该平台,扩大解决方案的应用范围,并取得业务成果。
结语
对于英特尔而言,自身的转变不可避免。全面转向AI已经势不可挡,既有的护城河已经不复存在,新的竞争优势有待建立。已有的产品是历史包袱还是新的起步阶梯,我们拭目以待。
好文章,需要你的鼓励


Savi Security:用AI实时拦截AI诈骗电话与短信
Savi Security由Patrick和Ryan Coughlin兄弟创立,融资700万美元,并正式推出iOS和Android应用。该应用可实时筛查短信、语音邮件和来电,识别AI生成的诈骗内容。其核心功能是通话实时监控,用户可在可疑通话中邀请AI助手同步监听,分析行为特征。产品以家庭为单位收费,每月8美元,不限用户数量。FTC数据显示,2025年冒充诈骗造成损失高达35亿美元,是2020年的三倍。

香港中文大学(深圳)与字节跳动联手,造出能“自由调速“的语音大模型
香港中文大学(深圳)与字节跳动联合提出FlexiSLM,首个支持动态与可控帧率的语音大模型,在输入输出两端均实现自适应帧合并,6.25赫兹下推理速度提升一倍,语音对话质量超越同规模固定帧率模型。

Argo CD漏洞警示:GitOps基础设施应被视为零级核心资产
安全公司Synacktiv披露了Argo CD中一个未修复的高危漏洞,影响其repo-server组件的未认证gRPC端点。攻击者若能访问该端点及Redis数据库端口,可执行恶意命令、篡改部署数据,并在启用Auto Sync时自动推送恶意配置。由于Helm chart部署默认未启用网络策略保护,集群内任意受损Pod均可触发攻击。专家建议企业将Argo CD视为零级控制平面组件,实施严格的东西向流量隔离与特权访问管控。

中南大学团队打造“自我进化“的AI训练数据工厂:被丢弃的“废品“竟是最好的老师
这项研究提出DataEvolver框架,把被丢弃的"不合格训练图片"转化为改进数据收集策略的反馈,让AI文字图像生成训练数据的构建流程能自我进化,在相同数据量下显著提升文字渲染质量。
2024
04/10
09:59
分享
点赞

Argo CD漏洞警示:GitOps基础设施应被视为零级核心资产
AI投资拖累科技巨头气候承诺,碳排放持续攀升
Voltpost携手InCharge Energy,路灯电动车充电桩加速在美国扩张
Sonair发布全球首款获安全认证的3D超声波传感器
Niantic Spatial为Scaniverse新增USDZ导出功能,助力机器人仿真工作流
仿脑光传感器有望加速AI图像处理
Norm Ai融资1.2亿美元,估值达12亿美元,以AI智能体重塑法律服务
Bidbus获1500万美元融资,让经销商竞价收购你的二手车
AI法律创业公司Norm完成1.2亿美元C轮融资,跻身独角兽行列
征程赶超|WAIC 2026理论突破:以数理双向赋能为钥,开启AI范式革新新征程
征程赶超|WAIC 2026 Token经济:按下加速键,从技术计量到产业新范式
征程赶超|WAIC 2026科学智能:AI4S从“辅助计算”到“自主发现”,中国如何重塑全球科研版图?
