
英伟达BLACKWELL系统如何“吃下”万亿级参数AI模型

相信很多朋友跟我们一样,都对数据中心计算引擎抱有浓厚兴趣。但真正发挥作用的其实是整体平台——如何将计算、存储、网络和系统软件有机结合起来,构建起一套用于应用构建的可用平台。
要想正确理解英伟达Blackwell平台,我们先要从历史背景入手。下面请大家喝杯咖啡、振作精神,共同开启这段探索之旅。
2016年4月,英伟达推出了自主开发的DGX-1系统,由此正式从组件供应商转变为平台制造商。DGX-1系统是基于英伟达“Pascal”P100 GPU加速器与NVLink端口的混合cube mesh,将8个GPU耦合至一套实质上的NUMA共享内存集群中。英伟达公司联合创始人兼CEO黄仁勋在GTC 2024大会的开幕主题演讲中再次强调,首套DGX-1系统是由公司高层亲笔签名,并由黄仁勋本人交付给Sam Altman的。如今的Sam Altman当然无人不知、无人不晓,可当时的他刚刚于四个月前建立AI初创公司OpenAI。

到了“Volta”V100这一代GPU,搭载新引擎的DGX-1于2017年5月推出,在设计上与前代基本一致。而且相较于CUDAQ核心在FP32和FP64运算上41.5%的性能提升,特别是在凭借张量核心这一全新设计在半精度FP16数学运算上高达5.7倍的性能提升,新一代DGX-1的官方指导价(没错,那时候英伟达GPU还在按指导价销售)仅上涨了15.5%。也就是说按同等价格计算,该系统在半精度运算上的性能增长了79.6%。这代DGX-1系统还提供用于AI推理的INT8运算支持。
之后,AI领域可谓风云突变,英伟达的平台架构也随之变得愈发“疯狂”。
2018年5月,英伟达开始在其V100 SXM3当中引入完整的32 GB HBM2,全面超越V100 SXM2的16 GB容量。此外,英伟达研究部门也一举解决了内存原子交换难题,由此发展出的商业化产品就是我们如今熟悉的NVSwitch。到这里,DGX-2平台时代正式来临。

12个NVSwitch ASIC可驱动300 GB/秒内存端口,总双向带宽可达4.8 TB/秒,用于交叉耦合共16个V100 GPU;此外还有一组6个PCI-Express 4.0交换机,用于连接两块英特尔至强SP Platinum处理器和接入该GPU计算复合体的8个100 Gb/秒InfiniBand网络接口。DGX-2系统拥有1.5 TB主内存和30 TB闪存,单个节点的价格更是达到惊人的39.9万美元。
但世事就是如此。得益于内存和NVSwitch的进一步扩展,DGX-2系统的性能提高了一倍有余,这正是AI初创公司们所迫切需要的。而与此同时,英伟达决定将设备的性价比降低28%,借此扩大自己的利润空间。于是技术虽然进步了,但从性价比层面看,新的AI节点并没有较上一代有所优化。

到了“Ampere”一代GPU的出现,我们迎来了DGX A100系统。该系统于2020年5月新冠疫情期间推出,Ampere GPU上的NVLink 3.0端口实现了传输带宽倍增,现在达到600 GB/秒,因此六个DGX A100系统中的NVSwitch ASIC必须进行聚合,从而组合出相同的600 GB/秒速率。这也意味着将NVLink内存集群的大小由16个减少至8个。
DGX A100拥有八个A100 GPU,两块AMD“Rome”Epyc 7002处理器、1 TB主内存、15 TB闪存以及9个Mellanox ConnectX-6接口(1个用于管理,8个用于GPU),并继续通过PCI-Express 4.0交换机复合体实现CPU和NIC与GPU复合体之间的连接。这时候,英伟达还刚刚完成了对InfiniBand和以太网互连制造商Mellanox Technologies价值69亿美元的收购,因此开始使用InfiniBand互连来构建在当时看来体量庞大的集群,尝试把成百上千的A100系统对接起来。最初的SuperPOD A100包含140个DGX A100系统,其中由1120个A100 GPU和170个HDR InfiniBand交换机将这么多DGX A100节点粘合起来,实现了总计280 TB/秒的聚合双向带宽,且FP16 AI工作负载总和算力也达到近700千万亿次。
随着2022年3月“Hopper”H100这一代GPU加速器的推出,浮点运算精度继续减半至FP8,GPU本体更加强大,开始搭配更大的内存。与此同时,“Grace”CG100 Arm服务器CPU被纳入堆栈,一同带来的还有容量达480 GB、传输带宽为512 GB/秒的LPDDR5内存,保证能以超过600 GB/秒的连续带宽经NVLink实现对Hopper GPU复合体的访问。
下图所示,为英伟达DGX H100系统中使用的HGX GPU复合体:

Hopper GPU上使用的NVLink 4.0端口能提供900 GB/秒的传输带宽,且NVSwitch ASIC必须通过升级才能在包含8个H100 GPU的复合体中提供符合需求的带宽。这项性能指标最终通过四个双芯片NVSwitch 3 ASIC得以完成,对应以上渲染图中位于最前方的部分。
凭借着NVSwitch 3 ASIC,英伟达将SHARP网络内计算算法和电路从InfiniBand交换机移植到了NVSwitch 3 ASIC,使其能够在网络中(而非DGX节点GPU或ConnextX-7 SmartNIC上)执行某些聚合和归约操作。如此一来,包括全部归约、全对全、一对多在内的多种操作自然也归该网络处理。
目前仍有众多客户使用的DGX H100 SuperPOD示意图:

该设备在FP8精度下的额定性能为1百亿亿次,SHARP网络内处理能力则为192千万亿次。SuperPOD复合体中共有256个GPU以及20 TB的HBM3内存。对于正在开展部署实验的朋友们来说,有一种方法可以将外部NVSwitch 3交换机组成互连来建立共享内存GPU复合体,借此在SuperPOD中的全部256个GPU之间建立一致连接。在我们的测试中,与DGX A100 SuperPOD相比,采用NVSwitch互连的DGX H100 SuperPOD的千万亿次性能密度可达前者的6.4倍;更重要的是,在57600 GB/秒的速率下,其对分带宽可达A100集群的9倍。
虽然包括英伟达在内,还没有人在实际部署这套基于NVswitch的完整DGX H100 SuperPOD,但这无疑为Blackwell的登场奠定了基础。
于是,我们最终迎来了时代的又一位骄子、AI领域的“唯一真神”Blackwell:

Blackwell平台以HGX B100和HGX B200 GPU计算复合体为基础,这些计算复合体将被部署在DGX B100与DGX B200系统之内,并搭载风冷版本的Blackwell低速GPU版本。
而完整版Blackwell GB100 GPU则仅用于搭建GB200 Grace-Blackwell SuperPOD,其将单块Grace CPU与两个Blackwell GPU匹配,并配合NVSwitch连接建立起GB200 NVL72系统。顾名思义,该系统通过NVSwitch 4互连将72个Blackwell GPU连接起来。这套改进后的互连系统能够扩展至576个GPU,其理论“横向扩展”极限可达两年前讨论的NVSwitch连接DGX H100 SuperPOD的2.25倍。
也就是说,配备72上Blackwell GPU的机架本身构成一种新型性能单元,它将取代使用H100或H200,甚至是B100或B200 GPU的八CPU节点。但各位不必担心,大家完全可以从OEM和ODM厂商处买到这类DGX服务器及其克隆方案,而OEM和ODM又是从英伟达处买来的HGX GPU复合体。
下表所示,为HGX B100和HGX B200及其B100和B200 GPU的性能参数,具体数字取自英伟达公司发布的Blackwell架构技术简介:
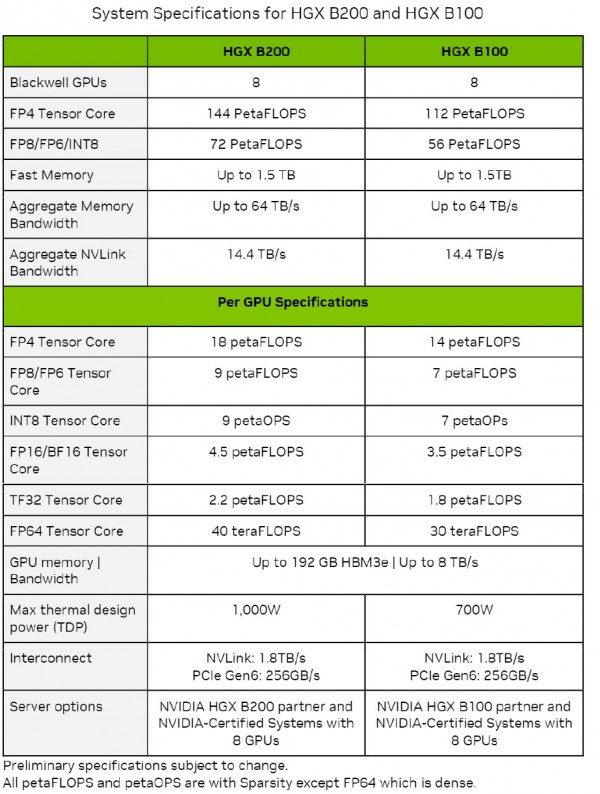
表中不同精度及数据格式下的吞吐量数字,均为开启稀疏性后的结果;但其中FP64吞吐量除外(FP64吞吐量为关闭稀疏性下的结果)。
我们很快注意到,所有数据都是由张量核心运行得出,而非由CUDA核心运行得出。这并不一定代表Blackwell架构中就没有CUDA核心,可奇怪的是,表中确实没有任何体现——而且如果真的取消了CUDA,那就更有趣了。(我们猜测很可能是取消了。)
另一个值得关注的重点,就是内存容量和内存带宽部分都用了“高达”的表述,也就是“不超过”的意思。所以如果今年晚些时候B100和B200正式上市后,其HBM3E内存容量低于192 GB、带宽低于8 TB/秒,也请大家不要太过惊讶。如果英伟达能够获得良品率和供应量都很充足的HBM3E内存,那当然是再好不过。但很明显英伟达希望把带宽和容量最高的HBM3E留给GB200系统,该系统将Grace CPU与两块Blackwell B200 GPU结合起来,每个GPU的全力运行效率为1200瓦,因此在Blackwell的双芯片GPU复合体中能提供20千万亿次的FP4精度持续性能。
HGX B100 GPU复合体中使用的B100与GHX H100 GPU复合体中的H100拥有相同的运行功率,因此专为前代Hopper H100 SXM5 GPU设计的系统也可直接插入Blackwell B100 SXM6模块,该模块在FP4精度下拥有14千万亿次算力、FP8精度为7千万亿次。同样在FP8精度下,与Hopper芯片相比,每块Blackwell芯片的吞吐量提高至1.8倍;在双芯片配置下,FP8性能提高至3.6倍。从这样的结果来看,我们有理由猜测Blackwell芯片上的张量核心很可能是Hopper芯片的2倍。
HGX B200 GPU复合体中使用的B200的运行温度提高了42.9%,在双芯片配置下每插槽可提供18千万亿次的FP4精度算力。而无论B200的运行速度如何,每个Blackwell芯片在FP8精度且开启稀疏性的条件下均具有9千万亿次算力,相当于H100芯片的2.25倍;考虑到双芯片设计,对应每插槽性能提高至4.5倍。
这是块巨大的GPU
HGX B100和HGX B200系统还迎来了全新组件,也就是NVLink 5端口和NVLink Switch 4 ASIC,负责与GPU端口进行通信。二者都能以100 Gb/秒的速率在单通道上传输信号,并采用PAM-4编码(每信号携带2 bit),因此每通道的有效带宽可达到200 Gb/秒。再通过多通道间的大规模聚合,即可借助B100和B200 GPU复合体上的端口向NVLink Switch 4(也可以简称为NVSwitch 4)ASIC提供1.8 TB/秒的双向传输带宽。该NVSwitch 4 ASIC拥有7.2 TB/秒的总和带宽,因此可以驱动四个1.8 TB/秒的NVLink端口(每个端口拥有72条以200 Gb/秒速率运行的通道,相当令人难以置信)。

该ASIC上的SerDes共驱动72个以200 Gb/秒速度运行的端口,这些端口与新款InfiniBand Quantum-X800(原Quantum-3)中使用的Serdes相同,后者拥有115.2 Tb/秒的总和带宽并可驱动以800 Gb/秒速度运行的总计144个端口。
下面来看NVLink Switch 4芯片的放大图:

这款芯片拥有500亿个晶体管,采用与Blackwell GPU相同的台积电4NP制程工艺。
新款NVLink Switch拥有3.5造成千万亿次的SHARP v4网络内算力,用于在交换器内部执行聚合操作,从而提高GPU集群的效率。对于某些以并行计算形式完成的聚合操作,特别是需要计算平均权重并在计算中间阶段传递这些权重的任务,最好能在位于所连接节点的本地中心上的网络内执行。
有趣的是,NVLink Switch 4 ASIC能够跨128个GPU提供机密计算域,而且最多可以跨越576个GPU扩展NVLink的相干内存结构——后者规模相当于NVLink Switch 3 ASIC中256 GPU理论内存结构的2.25倍。英伟达超大规模与HPC业务总经理Ian Buck提醒我们,NVLink Switch 3中256个GPU的理论上限只适用于研究,对实际生产无甚影响;同样的,NVLink Switch 4中576个GPU的理论上限同样只适用于研究,实际生产不可能触及。
但这一次,在我们即将介绍的GB200 NVL72系统当中,72个以紧密耦合方式共享内存的GPU将共同作为新的计算单元,类似于当初搭载HGX GPU复合体及NVSwitch互连的DGX系统产品线上的8或16个GPU配置。曾经的节点现在变成了完整的机架,所以我们可能真的要考虑触顶的可能性了。
下面来看机架中的各组件:

GPU与CPU数量比为2:1,表明AI主机并不需要太过强大的Grace CPU,甚至不需要像用于推荐引擎的系统那样匹配LPDDR5内存。Graec只提供一个600 GB/秒NVLink 4.0端口,且端口一分为二分别以300 GB/秒的速度对接两块Blackwell B200 GPU。这远远超出了PCI-Express的能力,实际上我们要到明年年初才能迎来256 GB/秒的PCI-Express 6.0 x16插槽。英伟达今年在NVLink 5.0端口上实现的1.8 TB/秒带宽将一路闲置至2032年左右,届时PCI-Express 9.0 x16插槽才会以2 TB/秒的带宽助其实际落地。
下面来看Grace-Blackwell超级芯片的放大图:

DGX GB200 NVL72机架系统如下图所示:

图左为机架正面,右侧为机架背面,可以看到接有大量线缆。
该机架属于全新计算单元,原因非常简单:在这些NVLink交换器提供的带宽支持下,机架内各组件间仍可通过铜线直连,而无需经由重新定时器、光纤收发器和光纤线缆。而一旦跨越多个机架就必须采用光学通信器件,这肯定会增加额外的成本与发热量。这也是系统架构设计中一直需要努力避免的问题。
英伟达联合创始人兼CEO黄仁勋在对Blackwell机架规模设计进行拆解时解释道,“之所以能够在机架内实现互连,答案主要体现在背面,也就是DGX NVLink主干和与之对接的130 TB/秒总带宽——这已经超过了互联网的总带宽,相当于我们可以在一秒之内将所有网络内容发送给每个人。这里我们共布设有5000根NVLink线缆,总长达两英里。这种直连设计堪称奇迹,因为如果转而使用光学器件,那就必须借助收发器和重新定时器,单是这二者本身就要耗费20千瓦功率(单收发器功率为2千瓦)来驱动NVLink主干。而借助NVLink Switch,我们以零功耗方式成功达成了目标,顺利节约下20千瓦的计算用电量。考虑到整台机架的功率也只有120千瓦,这2千瓦的差异无疑相当显著。”
Buck还提到,铜缆与光纤网络链路的混合成本,相当于纯NVLink交换器架构成本的6倍。也正因为如此,我们猜测72 GPU以上的架构仍只停留在研究阶段,还远无法实际生产。估计此类规模的机架无法单纯依赖NVLink 交换器,而需要借助InfiniBand或者以太网互连,当然前提是客户拥有充足的供电、冷却和光学通信器件资源。
纸面数据不错,实际表现如何?
Blackwell高端平台中采用的这种机架级方法,其实在英伟达与亚马逊云科技共同构建的“Ceiba”超级计算机中就已有所体现。这台Ceiba机器基于DGX GH200 NVL32,顾名思义就是基于NVLink Switch 3互连的机架级设计,将32个Grace-Hopper CPU-GPU超级芯片互连起来以形成统一的共享计算复合体。其中有9个NVSwitch系统负责将这些计算引擎彼此互连,并提供128 千万亿次算力、20 TB总内存(其中4.5 TB为HBM3E,提供157 TB/秒的聚合内存带宽),且全部由聚合带宽为57.6 TB/秒的NVLink链路承载。
而此次公布的Blackwell GB200 NVL72,将把Ceiba系统提升到又一个前所未有的新层次。
前文图表列出了GB200 NVL72与DGX H100之间的倍数关系,但这一切只是纸面结论,实际性能还须落在实处。
根据黄仁勋在主题演讲中的表述,真正值得比较的是二者在OpenAI 1.8万亿参数GPT-4混合专家大模型的训练表现。在基于Hopper H100 GPU的SuperPOD集群上,在节点外部使用InfiniBand互连、在节点内部使用NVLink 3,则整个训练任务需要8000个GPU在90天内耗费15兆瓦电量才能完成。而如果在同样的90天周期内通过GB200 NVL72运行同一训练任务,则只需要2000个GPU和4兆瓦电量。如果使用6000个Blackwell B200 GPU的话,则训练任务只需要30天和12兆瓦电量。
Buck具体解释称,两套架构的差异不止体现在算力上,而是I/O与算力的综合体现。对于这些混合专家模块,新架构能够对更多个层进行并行处理,同时在各层之间实现内部通信。这种数据并行性(将数据集拆分成块,并将计算任务分别委派给各GPU)正是HPC与早期AI计算的标志性负载。此外还有张量并行性(跨多个张量核心拆分给定计算矩阵)与管线并行性(将神经网络处理层分派至各GPU,通过并行处理以加快速度)。现如今,我们又迎来了模型并行性,即同时在一组混合专家模型上执行训练和推理,看哪个最擅长给定高质量响应。
但更让人头痛的是,由于模型并行性负载太过复杂,我们可能还需要单独的AI模型来跟踪这一切……Buck表示,为了在GB200 NVL72集群上找到正确的GPT-4并行训练配置,英伟达前后进行了2600多次实验,希望确定硬件构建和模型拆分切片的正确方法,保证其尽可能保持高效运行。下面来看部分实验的可视化图形:
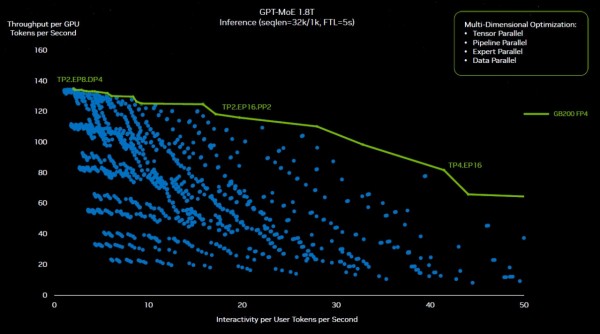
黄仁勋在主题演讲中解释道,“所有这些蓝点代表着对软件的重新划分,而优化目标就是弄清楚是否该使用张量并行、专家并行、管线并行或者数据并行,从而将这套巨大的模型分布在所有不同GPU上以提供持续稳定的理想性能。如果没有英伟达GPU的可编程特性作为依托,这样的探索根本就不可能实现。凭借CUDA,也凭借我们极大丰富的生态系统,英伟达能够探索这一空间并最终找到图中绿色的最优配置线。”
下图所示的绿色脊线,代表Hopper与Blackwell在1.8万亿参数MPT-4混合专家模型(MOE)上的运行状态。作为参考,图中还列出一条紫色的Blackwell理论性能线,代表如果直接照搬Hopper系统中的NVLink Switch 3与400 Gb/秒InfiniBand混合方案,且不转为新的Transformer Engine与FP4运算形式,其在FP8精度下的推理性能。由此得到的纯粹是芯片直接升级的结果,完全无法体现系统的整体更新:
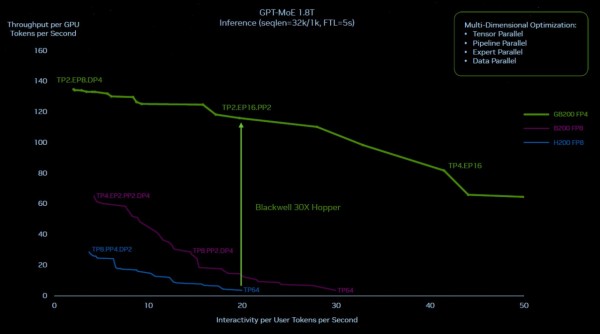
可以看到,单纯将Hopper替换为Blackwell并不是最好的答案。根据英伟达方面的解释,只有在配合一系列正确举措之后,推理性能提升至30倍、推理功耗降低至1/25的结果才有可能实现。
而达成这个目标需要多种因素的相互作用。如果在仅由16个Hopper级GPU(即两个通过InfiniBand互连的HGX系统板)构成的集群上运行这套GPT-4混合专家模型,那么由于需要跨并行层级执行聚合操作,该机器约有60%的运行时间被耗费在通信上,只有40%用于实际计算。而速度更快、带宽更高的NVLink Switch互连能保证将更多时间投入到计算任务当中。
配合跨72上GPU的NVLink Switch互连,各个GPU间能够以惊人的速度保持相互通信,甚至在必要时可以同时相互通信并快速完成对接。不仅如此,GB200节点中的每个节点都包含2个GPU,而非GH200节点中的每节点1个GPU。新系统中每个GPU配备的HBM3E内存容量也约为原先的2倍,带宽也几乎实现了倍增。在液冷版GB200 NVL72配置当中,两个Blackwell插槽已经能在FP4精度下提供40千万亿次算力;而单一Hopper插槽在FP8精度下仅能提供4千万亿次算力。
可以明显看到,网络与计算有着同等重要的性能意义。
顺带一提,每8个这种GB200 NVL72机架现可构成一个SuperPOD,大家可以通过800 Gb/秒InfiniBand或以太网将其互连起来;或者,也可以尝试将半排机架中的全部576个GPU整体连接起来以建立规模更大的共享内存系统。虽然后者的网络成本可能会几乎逼平计算成本,但考虑到576个GPU所提供的恐怖内存与计算域,这套方案也许将物有所值……毕竟几年之后,可能一整行机架就代表一个新型节点。从目前的趋势分析,具体时间可能就在两年后。而进一步展望未来,也许整座数据中心都将成为新的单一节点。
好文章,需要你的鼓励


豪声电子泰国电声工厂初步投产:2500万泰铢项目进入产能爬坡
今天讲的出海案例是生产微型扬声器、受话器和音响产品的豪声电子,其计划投资2500万泰铢的泰国音响类电声工厂已经进入初步投产阶段。

马萨诸塞大学的研究者们证明了:搜索引擎的“比较策略“在数学上优于传统方法
马萨诸塞大学从数学角度证明,MaxSim评分策略在理论能力上超越传统单向量内积方法,并提出Signed MaxSim扩展,显著改善否定查询性能。


新加坡国立大学与英伟达研究院联手打破视频生成的“非此即彼“困局:一个模型,两种能力,任意切换
新加坡国立大学与英伟达联合提出Flex-Forcing框架,通过时间帧和去噪步骤两个维度的灵活分块,将双向扩散和自回归视频生成统一到单一模型中,实现质量与效率的自由权衡。
2024
03/21
17:14
分享
点赞

“驯服”千亿模型,鏖战“黑猴打瓦”,龙虾“一键接管” ,锐龙AI Max+ 395开启全能桌面AI主机“王炸”时刻
豪声电子泰国电声工厂初步投产:2500万泰铢项目进入产能爬坡
地瓜机器人将560TOPS端侧算力,加载到了20+头部团队机器人中
WAIC 2026主论坛(下午场)重磅揭晓!
AI评测初创公司Braintrust遭入侵,敦促所有客户轮换API密钥
牙科诊所软件漏洞修复:患者医疗记录曾遭泄露
关键基础设施巨头Itron确认遭遇网络攻击
Vercel数据泄露范围扩大,黑客早于已知时间节点已入侵
苹果与博通签署300亿美元协议,共同生产美国本土无线芯片
摩托罗拉领投BRINC 1.25亿美元,推动紧急救援无人机大规模扩张
AI赋能芯片设计:前景广阔,疑问犹存
Arm今夏将推出自研芯片,Meta成首批客户
