
ARM NEOVERSE路线图发布:CPU设计出炉,大型GPU缺席

注意,剧透警告!
Arm Neoverse数据中心计算路线图刚刚迎来一系列新鲜元素,遗憾的是数据中心级独立GPU加速器仍然缺席。另一大备受期待但仍无动静的则是矩阵数学加速器,意味着在英特尔(以及Habana Labs)、SambaNova Systems、Tenstoreent、Groq以及Cerebras Systems等厂商积极行动的同时,Arm阵营对此依旧按兵不动。
这,不得不说是种耻辱。
考虑到英伟达目前凭借GPU技术优势对市场和利润空间的疯狂收割(事实上,英伟达差点成为Arm公司的实际持有者;如果当初其400亿美元收购Arm的交易获得全球监管机构的批准,那么很可能会在自家GPU上采用Arm的授权技术),整个世界无疑正在期盼Arm能够拿出一款更便宜的替代品,用以抵消英伟达现款“Hopper”H100/H200以及即将推出的“Blackwell”B100/B200独立GPU产品那恐怖的售价。事实上不光是英伟达,就连AMD的现款“Antares”Instinct MI300和将要投放市场的Instinct MI400独立GPU,也让客户们直呼越来越用不起。
说到这里,大家心里肯定都有疑问:本文为什么单单不提英特尔的独立数据中心GPU?这是因为除了在阿贡国家实验室“Aurora”超级计算机中使用的GPU之外,英特尔的“Ponte Vecchio”Max系列GPU还并不能算独立GPU市场上真正的头部选手。面对火爆的市场需求,英特尔家的GPU确实也能达到造出多少就卖掉多少的效果——但很遗憾,英特尔并没有足够的GPU产能,而且他们在短时间内也无法将Max系列GPU与Gaudi矩阵加速器相融合以打造出更具竞争力的产品。
而且这是一条一步慢、步步慢的残酷赛道。谷歌已经打造出自己的GPU,亚马逊云服务手中则掌握着Trainium和Inferentia,微软坐拥Maia,Meta Platforms正在开发MTIA系列。就数据中心基础设施收入来看,已经有近半数市场空间选择另起炉灶。在这样的背景下,尝试建立新的GPU或者矩阵架构有着很大风险,所以Arm才迟迟没有下场。但换个角度来讲,也正是由于存在巨大风险,Arm才成为唯一应该下场并有取胜可能性的技术力量。
如果非要说谁有勇气开发一款能与英伟达设备全面兼容的GPU,那我们也许能从当初IBM与Amdahl、富士通和日立之间的大型机市场对抗中找找答案——尽管经历多起反垄断诉讼,但IBM最终还是赢得了这场战争。英特尔和AMD也差不多,双方在数据中心x86架构上爆发过史诗级的对抗,直接搞得AMD几乎九死一生。
可惜的是,如今的Arm似乎并没有这样的野心和抱负,其他厂商也没有。似乎正是当初的大型机和x86之争让大家看清了现实。
加上Arm本身是一家上市企业,由于股票发行量较小加上市场的非理性追捧,导致其市值甚至超过了母公司软银。Arm坚持将自家CPU推向AI训练体系的各个环节,并强调Neoverse CPU设计方案也拥有强大的推理能力。下面这张图来自Arm 2024 Neoverse路线图简报会,其中的内容已经清楚表明了一切:
 知己知彼、别惹麻烦、见好就收。
知己知彼、别惹麻烦、见好就收。
公平地讲,图中全部三款CPU及其原研加速器均基于Arm架构,而且下方列出的三款DPU中也至少有两款采用Arm架构。(我们还不确定Azure Boost是个什么情况,但如果里面搭载有CPU,那也几乎必然是基于某种Arm核心。)如果在2011年那会看,也就是Arm刚刚向x86的数据中心大本营发起冲击的时候,这张图简直堪称痴人说梦。但事实证明Arm的数据中心CPU野心是严肃的,其产品在超大规模基础设施运营商和云服务商数据中心内的崛起就是最好的证明。
但我们还期望Arm能做得更多,比如说承接起数据中心内那复杂且独特的AI工作负载。甚至有一种声音,认为英伟达是早早就意识到生成式AI的巨浪即将到来,因此当初才愿意为Arm掏出400亿美元,目的就是靠收购将这位潜在的竞争对手边缘化,避免这家IP授权公司打造出杀手级的GPU产品。
就连Arm自己发布的蛛网图,也涵盖数据中心内多种常见工作负载的性能指标:
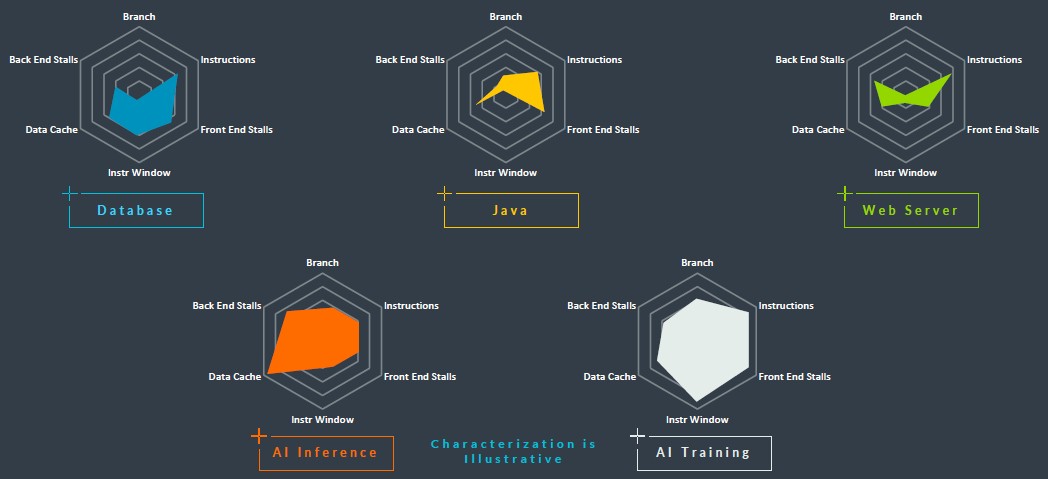
然而时间已经来到2024年,我们从Arm路线图中看到的仍主要是对原有方案的扩展,包括各类Neoverse核心类型的延续,以及计算子系统(CSS)授权封装许可(这些封装许可将适用于高性能V-级核心,以及已经于去年夏季伴随「珀尔修斯」N2核心发布的「Genesis」封装IP)。
微软的128核Cobalt 100处理器已确定基于Gensis CSS N3设计,我们强烈怀疑传闻中的谷歌“Maple”Arm服务器CPU也将基于CSS计算子系统打造——比如说基于该许可协议的“波塞冬”V3核心或者“赫尔墨斯”N3核心。具体如何选择,很大程度上取决于谷歌想要实现怎样的目标。我们认为超大规模基础设施运营商和云服务商一定会在其数据中心内混合部署N核与V核,并在边缘场景下部署E核。从过往产品来看,英伟达的“Grace”CG100和亚马逊的Graviton 4就是基于“得墨忒耳”V2核心。
这里我们将深入剖析这份Neoverse CPU路线图,而且以2022年9月的路线图版本为起点进行回顾。坦率地讲,当初那份路线图反而比2024年的最新版本包含更多细节:
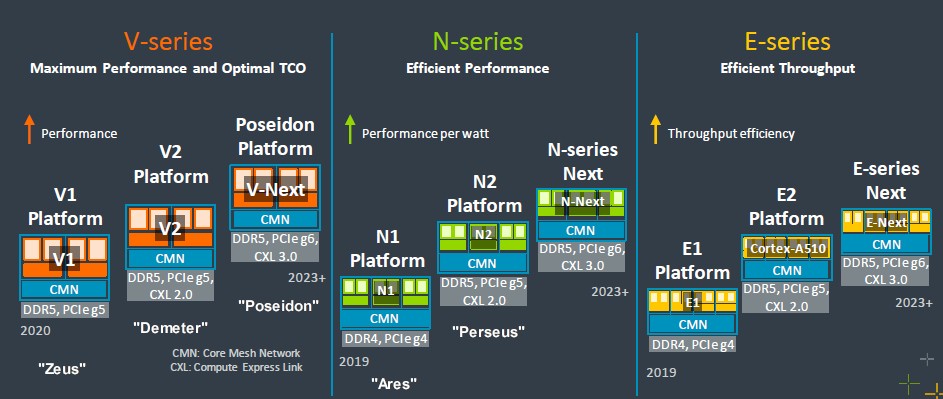
整个Neoverse规划案已经延续六年,在最初诞生的2018年10月,其基本思路只是每年开发一种新的核心与服务器平台,确保能跟台积电制程工艺的发展保持同步。2019年的Ares“阿瑞斯”平台采用7纳米晶体管蚀刻技术,2020年的Zeus“宙斯”则计划采用增强型7纳米工艺,2021年的“波塞冬”打算使用5纳米制程工艺。而且比跟制程发展保持同步更重要的是,人们真心希望Arm能够在可预见的未来,稳定在每一代新产品上保持30%的性能提升比例(部分由架构实现、部分靠功能实现)。
但之后的Neoverse路线图具体划分出了N、V和E核三种核心,并拉开了每一代核心的市场投放时间。例如,“波塞冬”V3核心最初计划在2021年推出,但在两年前的路线图中被调整为更加模糊的“2023年后”,直到如今才真正上市。不过这种变化也在情理之中,毕竟新冠疫情在全球范围内的爆发大大扰乱了芯片供应链与开发计划,Neoverse路线图背后真正的推手——各超大规模基础设施运营商和云服务商所受影响尤其严重。
但我们相信,随着Neoverse战略的持续推进,Arm及其客户的发展都将重新回归正轨。
下图所示为去年公布的Neoverse路线图,仅供大家参考。这份路线图随着计算子系统(CSS)的发布而推出,为了清晰起见,我们特意加注了核心代号:
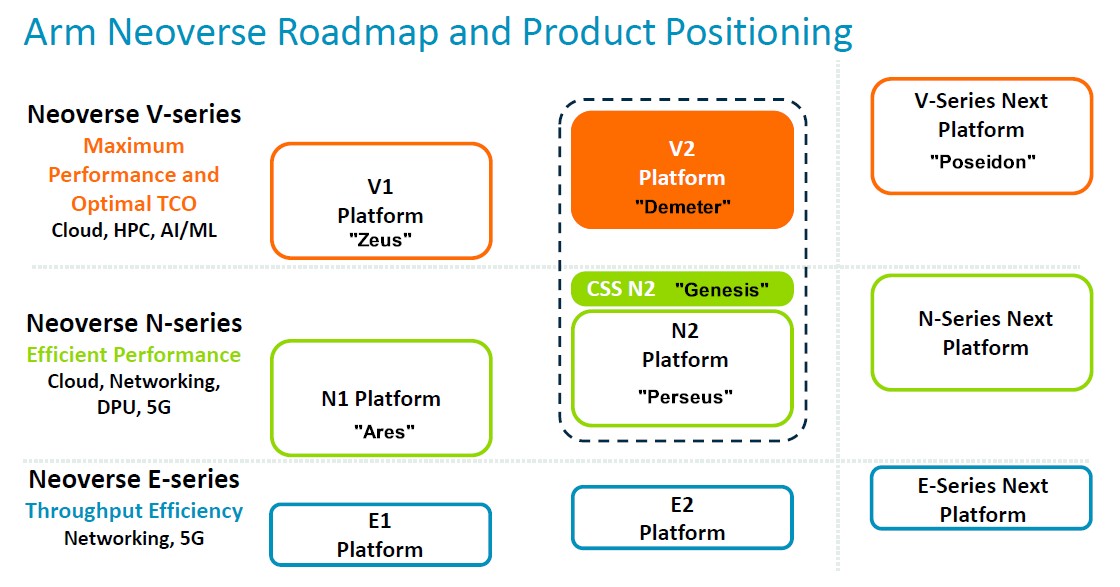
我们曾在之前的文章中提到,英伟达最初部署的“得墨忒耳”V2核心需要借助CSS封装,但现在看来并非如此。好消息是“波塞冬”核心及其CSS封装现已推出,“赫尔墨斯”N3核心及其CCS封装也如期亮相,具体参见2024年的Neoverse路线图:
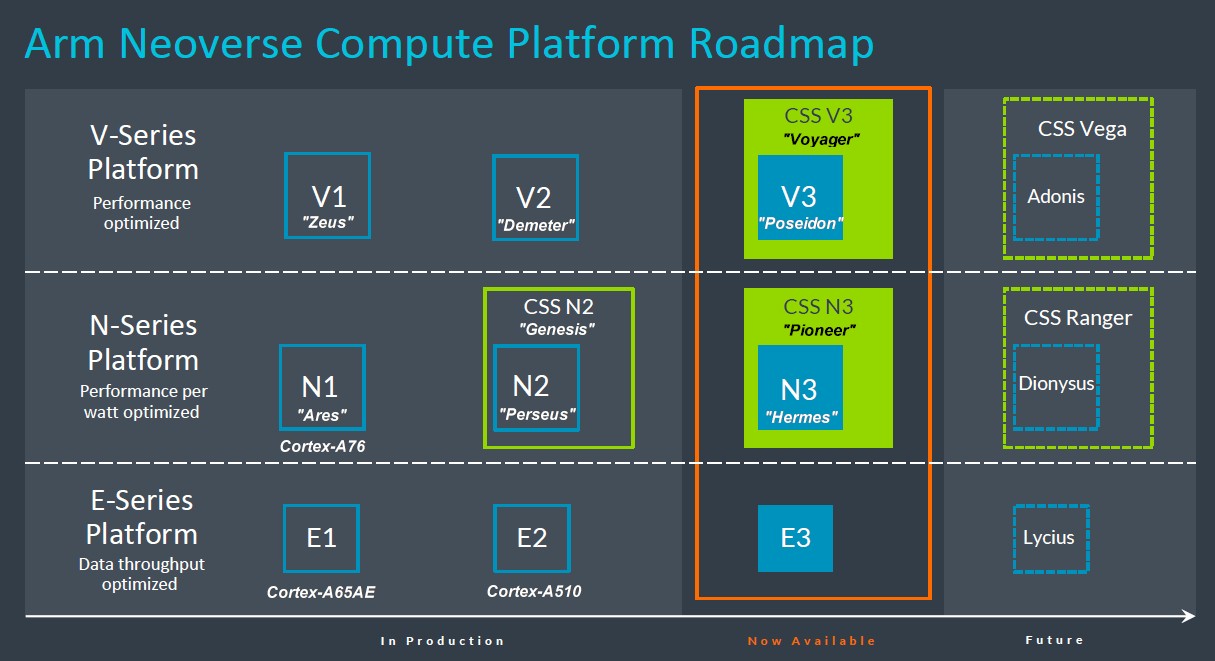
之前我们并不清楚N3和V3 CSS封装将有何代号,所以猜测如果Arm继续按《旧约》中Genesis“创世纪”的传统选择名称,那么答案很可能是Exodus“出埃及记”和Leviticus“利未记”。但现在真相揭晓,Arm选择的分别是CSS V3“Voyager”和CSS N3“Pioneer”。
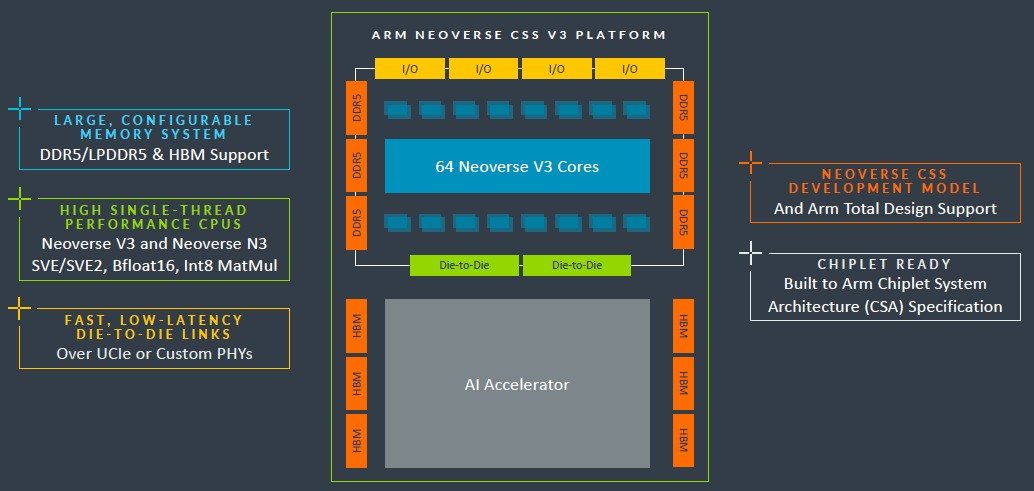
在2024年的路线图上,Arm省去了X轴上的年份标记,因此我们不清楚后续“阿多尼斯”V4核心及其“Vega”CSS封装,包括再下一代“狄俄倪索斯”N4核心及其“Ranger”CCS封装,乃至后续“利西乌斯”E4核心的具体推出时间。Arm Neoverse部门高层承诺在未来提供更多细节。
下面来聊聊目前已经实锤可靠的消息。CSS N3封装将以32个N3核心起步,搭载双DDR5内存控制器、双I/O控制器以及可选芯片间互连。这样如果将两套封装计算复合体共同接入同一插槽,则可提供64个N3核心。这些N3核将根据最新Armv9.2规范构建而成。
关于N3核心和CSS N3封装的制程工艺也未披露,但我们相信Arm会在5纳米、台积电的3纳米制程中做出选择,或者与三星和英特尔同类产品的制程保持一致。
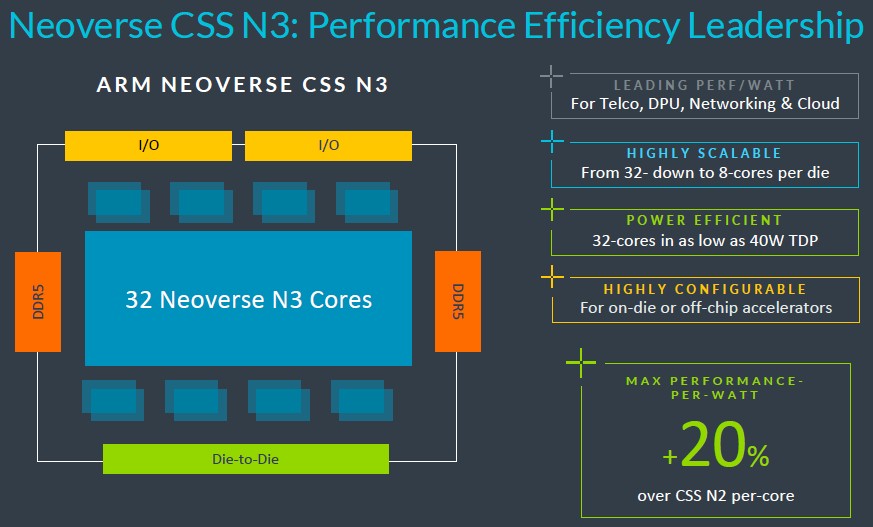
上图中的数据显示,N3 CSS封装可以在40瓦热设计点下提供32个核心,这强烈暗示整套设计很可能将采用台积电的3N 3纳米制程工艺。
据Arm介绍,N3封装还可缩小至8核形式,可能配备单DDR控制器加单I/O控制器。根据之前2022年9月的路线图,我们怀疑N3核心将被放入支持DDR5内存、PCI-Express 6.0外围控制器以及CXL 3.0 coherency overlay的封装当中。但如果图中所示的CSS V3封装属实,那么实际采用的可能仍是上代PCI-Express 5.0与CXL 2.0(我们仅做猜测,并非最终结论)。
我们不清楚N3核心上的向量单元有多宽,也不明确其具体数量。但如果N3核心想要在CPU上执行部分AI训练和各类AI推理负载(Arm显然坚定要走这条路线),那么与之前的N2核心相比,N3就必须得到增强。比较来看,N2核心拥有双128位向量单元,每个时钟周期能够执行四次FP64运算,再做分解即可得出混合精度性能。虽然Arm没有透露,但我们估计N3核心中也可能添加一个矩阵数学单元——或者叫张量核心。
“波塞冬”V3核心也有望以类似的方式得到增强。从历史规律来看,其向量和矩阵运算能力应该会达到“赫尔墨斯”N3核心的两倍,但这同样只是猜测。“宙斯”V1核心采用双256位向量单元,“得墨忒耳”V2核心则改为四128位向量单元;二者每个时钟周期都能执行8次FP64运算,但V2核心的设计效率更高。这也让我们不禁好奇,V3核心将会朝哪个方向继续推进。采用四个256位向量单元的可能性不大,毕竟V1采取的就是这种设计;八128位向量单元就更怪了,因为英特尔在其“Sapphire Rapids”至强SP CPU中就是用这种方式建立起AMX矩阵数学单元。
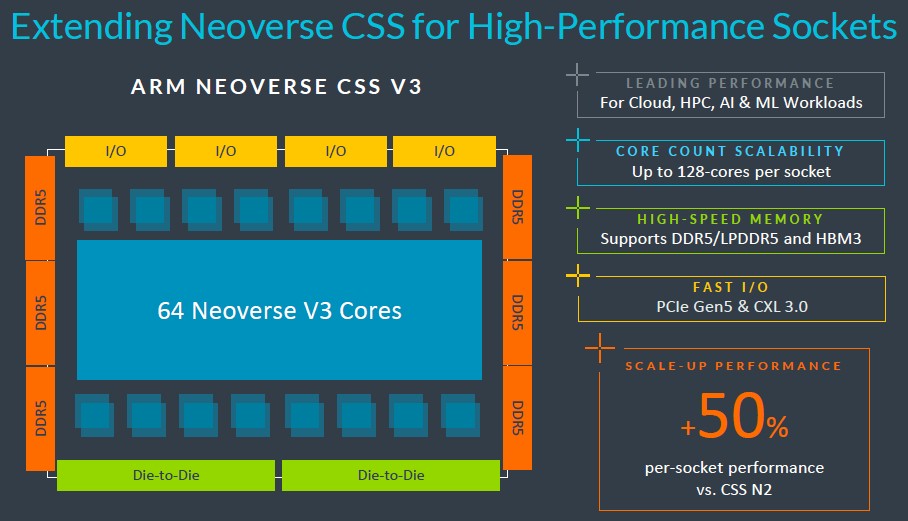
无论如何,基础CSS V3构建块将包含64个V3核心,搭配6个DDR5控制器、4个PCI-Express 5.0 I/O控制器加上双芯片间互连。从2022年9月的路线图上看,V3这代核心有可能会采用PCI-Express 6.0和CXL 3.0。但在推迟之后,二者恐怕要到V4甚至是N4代芯片才可能实现了(也有可能先在N3上实现新PCI-E加旧CXL组合,而V3完全沿用旧组合)。
据Arm介绍,这款CSS V3复合体的性能将较现有CSS N2复合体提升达50%,且两个复合体可放入同一封装,使得单插槽核心上限扩展至128个。最令我们惊讶的是,单插槽居然无法扩展至256个核心,但这很可能是受到CSS封装的限制、而非V3架构本身不够给力。不过考虑到技术或者经济层面的现实意义,估计也不会有人选择单插槽256个V3核心的配置。
V3封装将支持DDR5内存或HBM堆叠内存,我们也一直在关注全球各大CPU厂商对于HBM内存的支持进展。毕竟只要成本不是问题(特别是在生成式AI如此火爆的当下),HBM内存给HPC和AI工作负载带来的增益可谓显而易见,厂商当然也愿意抓住这波机会。
Arm还特别强调,CSS V3封装的设计目标是与加速器紧密连接起来。至少从Grace-Hopper超级芯片复合体的设计思路来看,英伟达肯定非常重视这种直连能力。
为了激发人们的关注,Arm还给出了V2核心、先前N1与V1核心,以及英特尔与AMD过去两代x86处理器的部分早期性能规格。下面来看比较图表:
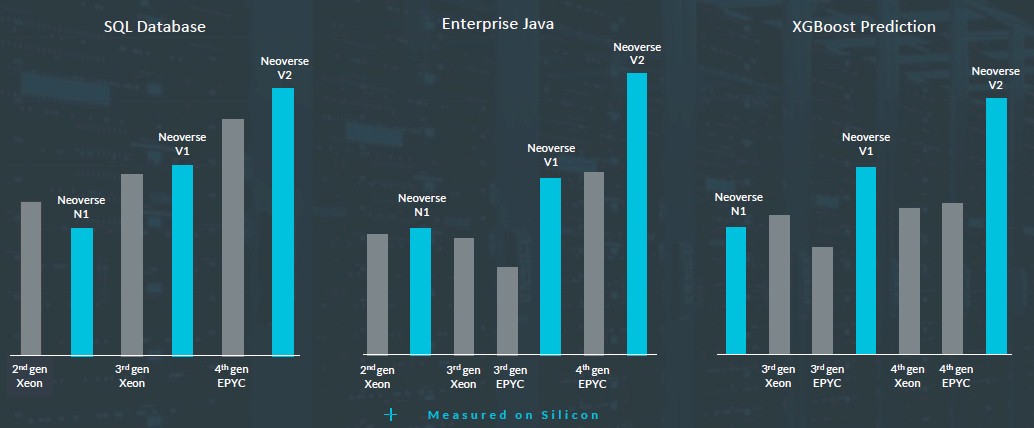
在另一张图表中,我们还能看到在不同工作负载当中,V3核心与V2核心、N3核心与N2核心之间的性能比较:
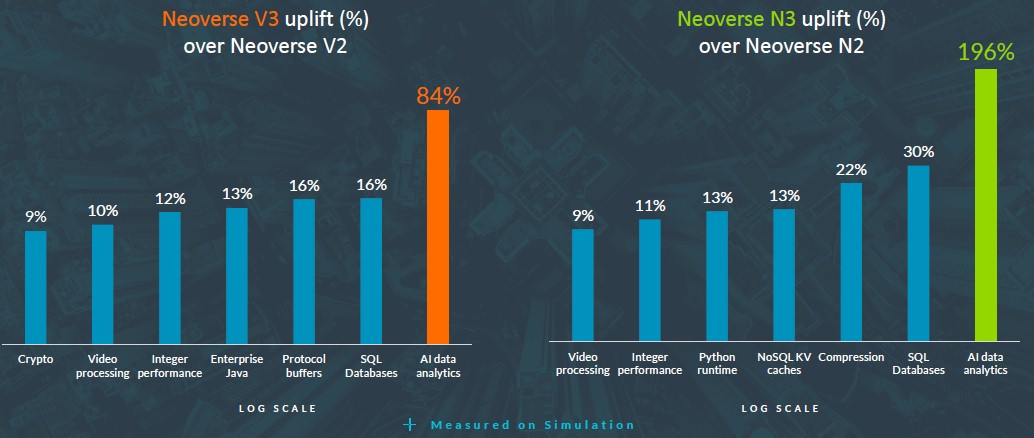
Arm还专注于提高XGBoost性能表现,这是一种在回归、分类和预测场景下常用的经典机器学习算法。
作为补充,Arm也在相对较小的Llama 2大语言模型(仅有70亿参数)上给出了部分AI推理负载的基准测试结果:
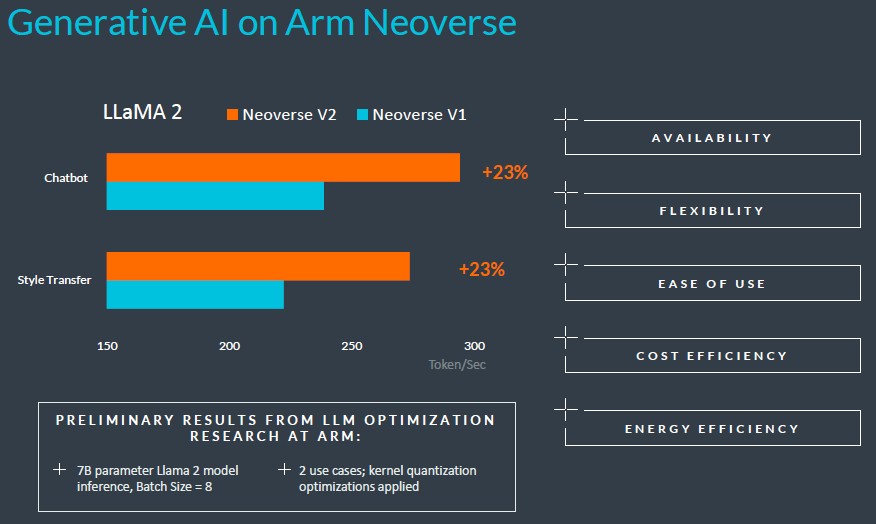
不过目前Arm尚未公布V3设计的性能数据,看来热心群众们还得再等一阵才能得到答案。
好文章,需要你的鼓励


亚马逊Mechanical Turk停止接受新用户,众包平台走向终结
亚马逊旗下运营近20年的众包平台Mechanical Turk已停止接受新用户注册,并将于2026年7月30日正式关闭。该平台于2005年上线,早于AWS公有云业务,曾是全球知名的众包任务市场,涵盖验证码识别、情感标注等人工任务,后转型为AI训练数据标注工具。随着亚马逊推出SageMaker Ground Truth等替代方案,Mechanical Turk的历史使命已宣告终结。

当AI助手“看“电脑屏幕,就像让一个视力正常的人蒙眼操作——德克萨斯大学达拉斯分校的解法
LUMOS是一个让AI通过操作系统无障碍接口直接读取界面语义信息来操控电脑的中间层,避免依赖截图识别,降低AI电脑操作的资源消耗和出错率。

微软推出Memora,致力于解决AI智能体的记忆难题
微软研究院发布Memora记忆系统,旨在解决AI智能体在长期部署中记忆碎片化、检索效率低的问题。Memora通过将存储内容与检索方式解耦,引入"主抽象"与"线索锚点"双组件架构,在LoCoMo和LongMemEval两项基准测试中表现优异,上下文token用量最高可降低98%。但专家提醒,实际企业成本还需考虑索引、存储及合规审计,且该项目目前仍处于研究阶段,尚未达到生产就绪水平。

腾讯混元携手多所高校,让3D网格生成快如闪电——PolyFlow如何破解困扰业界多年的“拓扑难题“
腾讯混元联合多所高校提出PolyFlow,用流匹配模型并行生成艺术家风格3D网格,速度比自回归方法快百倍,几何精度达到新高。
2024
02/22
17:52
分享
点赞

Even Realities完成1.5亿美元融资,估值达10亿美元
数据中心会造成空气污染吗?关键在于电力来源
Day-0支持|摩尔线程完成美团LongCat-2.0极速适配
亚马逊Mechanical Turk停止接受新用户,众包平台走向终结
微软推出Memora,致力于解决AI智能体的记忆难题
SGE计划在英国部署14座BWRX-300小型模块堆,总装机容量达4.2吉瓦
特斯拉在迈阿密划定Robotaxi小范围服务区,得克萨斯扩张仍受阻
Luxonis完成1400万美元融资,为智能自动化打造视觉感知层
.NET 8 与 .NET 9 即将停止支持,微软建议升级至 .NET 10
苹果供应商塔塔电子遭黑客攻击,iPhone 18 Pro核心机密外泄
美国解除对Anthropic旗下Fable 5和Mythos 5大语言模型的出口限制
Meta推出定制CXL芯片Vistara,让旧内存在新服务器中焕发新生
