
AMD当前已成无可争议的数据中心GPU性能王者

没有什么比出色的硬件更能激励人们开发并调整软件,借此充分发挥其性能与功能优势。犹记得首款“Antares”Instinct MI300系列GPU公布时的豪言壮语,AMD希望在生成式AI市场上与英伟达正面较量,并尽其所能通过MI300A和MI300X GPU加速器争夺市场份额。
面对生成式AI这块巨大的蛋糕,目前的头号受益者当然就是英伟达——该市场对于计算引擎的需求增长速度已经超过了整个行业所能交付的极限,因此不仅业务规模可观、利润也是相当丰厚。换言之,英伟达之所以还没有清晰感受到AMD MI300 GPU平台的冲击和威胁,就是因为需求巨大而供应不足,所以双方暂时还岁月静好、相安无事。
从两头来看,这种激烈的竞争可能将被进一步推迟,因为未来一、两年内AI训练与大型推理加速器的需求恐怕会继续超过供应。但好消息是,供应短缺将让各类加速器架构都拥有自己的生存空间,各自在大语言模型和工具生态中占据一定比例,这对某些厂商来说也算是前所未有的宽松发展周期。不过随着市场供应正常化,且所有大语言模型和深度推荐算法模型(DLRM)都经过软件工程师的针对性调优之后,这场大洗牌早晚会到来并最终引发残酷的价格战。到那个时候,AI硬件市场的畸形辉煌也将归于平静。
但在此之前,各家加速器芯片厂商还将继续马力全开,无忧无虑地把自家产品在世界各地的超大规模基础设施运营商、云服务和HPC数据中心那边卖上个好价格。而谁能在这段时间里让自己的技术获得更高的渗透率,谁就能成功摊薄成本、为将来归于正常的GPU市场和行业竞争做好充分准备。
封装比芯片本身更重要
AMD在圣何塞召开的Advancing AI大会上公布了MI300产品家族,基本与英伟达、英特尔和其他AI加速器厂商的节奏保持一致。因此对于系统架构师和AI软件开发者们来说,目前最值得关注的就是MI300的原始规格数据。从吞吐量和速度指标上看,由苏姿丰团队开发的“恶魔”MI300系统甚至还具有微弱优势,在一定程度上压倒了黄仁勋团队打造的“地狱猫”H100系统。
其实这里的“恶魔”和“地狱猫”并不是官方名称,只是在拿汽车爱好者熟悉的道奇挑战者肌肉车打比方。地狱猫是这部车子的高性能调教版本,而恶魔还要更极致一些。
从内存带宽和原始算力来看,AMD的MI300X就是GPU版的“恶魔”,其拥有192 GB HBM内存、5.3 TB/秒内存带宽和750瓦额定功率下的163.4万亿次FP64矩阵数学运算能力。而全新英伟达H200配备的则是141 GB HBM3e内存、4.8 TB/秒内存带宽,在实际工作负载上的FP64矩阵性能可达上代H100的1.6到1.9倍,700瓦额定功率下的FP64性能则为66.9万亿次,只能算是略逊于“恶魔”的“地狱猫”。AMD MI300A拥有128 GB HBM3内存、5.3 TB/秒带宽、760瓦额定功率下122.6万亿次FP64矩阵数学运算能力,基本对应挑战者的SRT车型。至于英伟达的上代H100,配备80/96 GB HBM3内存、3.35 GB/秒带宽、在700瓦额定功率下提供66.9万亿次FP64矩阵数学算力,相当于挑战者R/T Turbo。我们毫不怀疑,当英伟达明年公布“Blackwell”数据中心GPU时,这款新品应该能够实现全面反超。但AMD也不会坐以待毙,目前其MI400也已经在紧锣密鼓的研发当中。
英伟达和AMD正在相互较劲,争相打造更加令人难以置信的强大产品。两家公司的市场份额则将由实际发货的GPU数量决定,双方也都会根据客户关注的指标为其GPU性能指标制定相应的售价。
跟往常一样,我们将通过三个切入点对MI300家族的更新做全面剖析。首先,我们将简要讨论新款AMD GPU加速器与其前几代AMD硬件的比较。之后,我们会深入研究MI300设备的架构,最后再分别拿AMD MI300A跟英伟达GH200 Grace-Hopper混合设备、以及AMD MI300X同英伟达H100/H200加速器进行一番正面对垒。
根据AMD公司今年6月的爆料,MI300将提供两个版本。其中MI300X是一款纯GPU加速器,负责承担基础模型提出的高强度AI训练与推理需求;而MI300A则是一款混合设备,将Epyc CPU与Instinct GPU纳入同一封装,且二者共享相同的HBM内存空间,从而为需要在CPU上运行串行代码、并将结果交由GPU进行并行处理的负载带来效率提升。
当时,AMD是拿MI300与MI250X进行性能比较并做出上述说明,这也让我们对MI300A的性能和功耗产生了不切实际的判断。下面来看AMD的表述原文:
“截至2022年6月7日,AMD性能实验室对采用AMD CDNA™3 5纳米FinFET制程工艺设计的AMD Instinct™MI300 APU(850瓦)加速器进行了性能测试,预计可实现2507万亿次FP8结构化稀疏浮点运算性能。”
当时看到这里的850瓦数字,我们认为这代表着AMD对MI300A GPU进行了超频,从而获得与MI300X相当甚至更好的向量与矩阵数学性能,而MI300X的正常性能可能都达不到这样的水平。但这也很合理,毕竟MI300A将先期入驻劳伦斯利弗菲尔国家实验室的“El Capitan”超级计算机,这台算力达2百亿亿水平的性能巨兽将基于HPE的百亿亿级“Shasta”Cray EX机器,全面采用液冷设计。但事实证明,MI300A上的GPU并没有超频,而且尽管HBM容量有所下降,凭借相同的活动内存栈数量(与初代Hopper H100 GPU类似),其内存带宽也完全没有减少。只不过与MI300X相比,MI300A上的HBM内存栈更少——后者为每栈8芯片,而前者则为每栈12芯片。因此MI300A的计算性能低于我们的预期,但内存带宽性能则比预期略好。
不过我们仍然期待El Capitan Turbo能够对GPU做做超频,毕竟这就是超级计算系统存在的意义——彻底榨干硬件上的每一滴资源。换句话说,这些芯片在具有特定带宽限制的工作负载上的有效性能,将主要由内存和原始算力所决定。
下面来看“Antares”MI300X与MI300A与之前AMD Instinct数据中心GPU之间的规格对比:
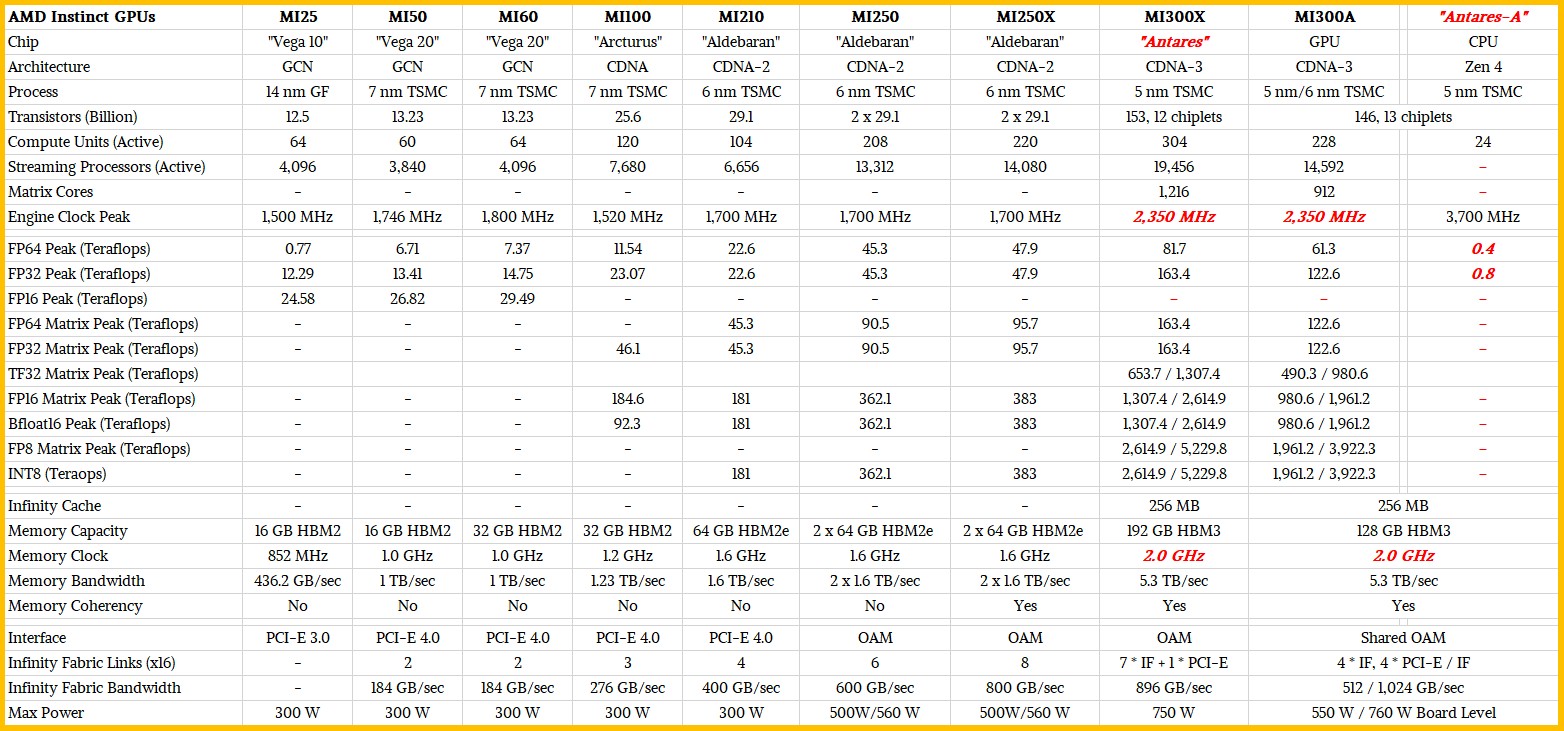
目前还不清楚MI300X和MI300A GPU的时钟速率跟HBM3内存规格,但表内使用的预估数字应该都比较靠谱。
可以明显看到,自MI25和MI50时代以来,AMD已经成功完成了一波大提升。毕竟曾经的数据中心GPU计算完全由英伟达所主导,而MI100让AMD朝着正确方向迈出了第一步,MI200成为转折点,而MI300则凭借全面的技术储备代表着AMD的真正崛起。另外可能从表中看不出来,AMD的小芯片方法和封装也都大有进展,将2.5D芯片互连同台积电的CoWoS中介层相结合,成功把Mi300计算复合体跟HBM内存和3D计算块(CPU加GPU)堆叠在了Infinity Cache 3D垂直缓存与I/O晶片之上。这种2.5D加3D的封装模式被AMD称为3.5D封装。
我们将在后文的架构研究中深入讨论封装细节。在这里,我们先来看看这两款AMD计算引擎的算力、内存及I/O指标,并将其与上代产品做一一比较。我们将从全容量MI300X独立加速器的算力部分开始:

MI300X配备有8个加速计算芯片(AMD称之为XCD)。每个XCD包含40个计算单元,但暂时只开放其中36个计算单元以提高5纳米小芯片的制造良品率。也就是说,AMD在设计中还潜藏着另外10%的性能空间,所以如果后续开始生产全容量版本,大家也完全不必感到惊讶。
按照整个理论设计方案,MI300X共拥有304个计算单元,其中19456个流核心负责执行向量数学运算,1216个矩阵核心负责执行矩阵数学运算。矩阵核心(大家更熟悉的称呼可能是张量核心)支持2:4稀疏性,可将稀疏矩阵简化为密集矩阵,从而实现吞吐量实际加倍的效果。向量引擎不支持稀疏性。从上表可以看到,MI300X支持所有必需的数据格式,MI300A也同样支持这些格式。

在内存方面,每个MI300X计算单元配备32 KB的L1缓存,每个XCD中所有计算单元共享4 MB的L2缓存,再加上MI300X复合体中全部XCD共享的256 MB Infinity Cache。I/O芯片上连接着8个HBM3内存栈(采用双控制器设计,每控制器对应4个I/O晶片),每对HBM3内存之间的小方块仅起隔离作用,帮助降低MI300X复合体的制造难度。HBM3栈共分12个芯片,每芯片提供2 GB容量,因此总内存容量为192 GB、总带宽则为5.6 TB/秒。

其中4个底层I/O芯片(AMD称之为IOD)拥有7条Infinity Fabric链路,其组合峰值环带宽为896 GB/秒,可将8个MI300X整合为单个共享内存虚拟GPU。整个复合体拥有一个PCI-Express 5.0 x16端口,用于连接外部网络和系统。总体来看,MI300X复合体中的聚合I/O带宽可达1 TB/秒。
下面来看MI300X与上一代MI250X的比较结果:
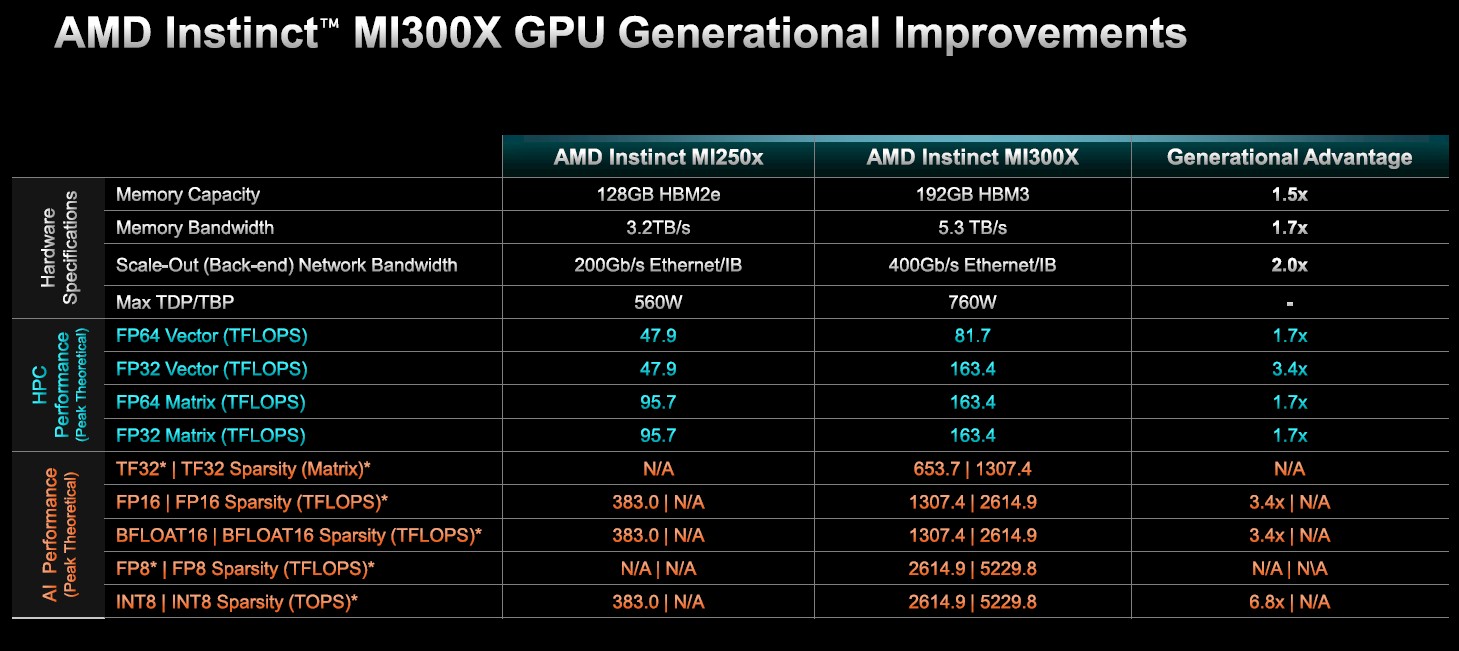
可以看到,MI300X的性能可以达到1.7倍到3.4倍之间(FP32优化实现了性能倍增,而且MI300X的矩阵引擎还支持稀疏性),而主内存增加至1.5倍、带宽增长至1.7倍、外部网络带宽增加至2倍,而总运行功率则仅提升35.6%。
这就是我们说的工程改造。多位行业知名人士表示,封装将是计算科学后续发展的新杠杆,而MI300X及其兄弟产品MI300A已经用实际成果证明了这一点。
在MI300A方面,AMD塞进了2个GPU芯片以及3个八核“Genoa”Epyc 9004芯片,由此构建起共享计算复合体。其中GPU和CPU均可寻址同一套内存,不必通过总线或者互连机制往来传递数据。

MI300X共拥有228个计算单元,6个XCD上共有14592个流核心和912个矩阵核心。该芯片组的额定功率为550瓦,使用MI300A电路板封装后的额定功率为760瓦。

MI300A复合体的高速缓存与MI300X相同,但相较于后者的12个内存芯片,MI300A的HBM3内存栈仅有8个芯片,因此总内存容量只有128 GB。下调内存容量是为了抑制功耗、发热量和成本,更好地满足传统HPC市场那敏感的预算要求。

MI300A上的I/O也与MI300X略有不同。其中配备4个Infinity Fabric链路,带宽为512 GB/秒,另外4条链路的带宽同样为512 GB/秒,具体可以选择4个PCI-Express 5.0 x16链路或者4条额外的Infinity Fabric链路。这种配置灵活性允许用户对4个MI300A CPU-GPU复合体紧密耦合起来,也可以使用附带的高通量管道获取额外的I/O、或者压缩I/O以容纳更多GPU。
综合来看,MI300A与MI250X的比较结果如下:
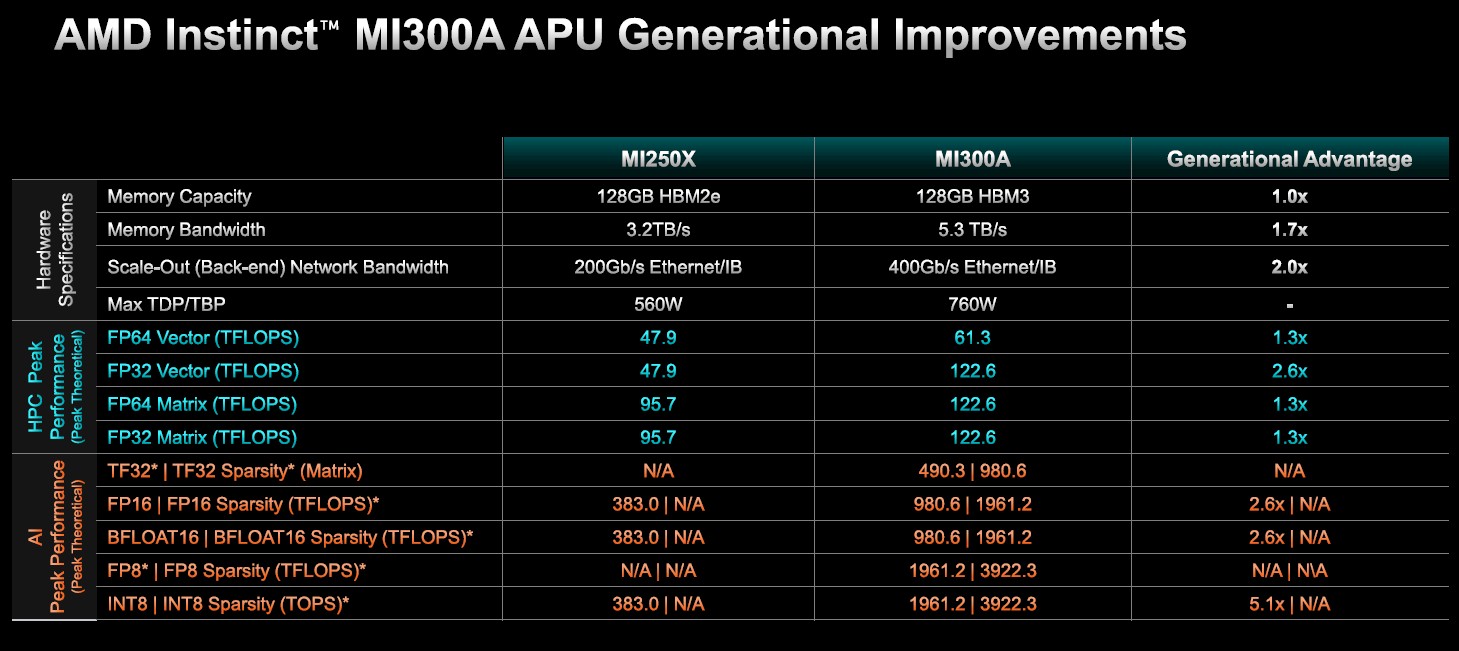
两款设备可支持的HBM内存容量相同,但MI300A的内存带宽为后者的1.7倍,而且实际上可由GPU和CPU小芯片共享。此外,MI300A的外部互连速度同样翻倍,峰值理论性能提高至1.3倍至2.6倍,运行功率则增加了35.6%。
我们期待看到这样的共享内存设计,会如何影响HPC和AI工作负载的实际应用性能。
平台比封装又更重要
归根结底,客户购买的是平台,而不是芯片或者插槽。AMD公司表示,MI300X GPU可以与上代MI200系列一样,接入至相同的开放计算通用基板(UBB)当中。

如果将8个MI300X设备捆绑起来,则单一UBB复合体能够在启用稀疏性的情况下以BF16/FP16精度提供21千万亿次(对于密集数据,性能减半为10.5千万亿次)算力,且拥有1.5 TB的HBM3内存容量。至于GPU与外部环境之间,则由一条PCI-Express 5.0 x16通道提供896 GB/秒的Infinity Fabric传输带宽。换句话说,CPU将可通过多节点网络结构实现对集群的全方位访问。
好文章,需要你的鼓励


NHS App将引入AI分诊工具,助力缩短患者等待时间
英国NHS计划在NHS App中部署AI智能分诊工具,作为三年100亿英镑数字化转型计划的一部分。该工具可引导患者前往最合适的医疗服务渠道,包括全科医生、药店或急诊等。试点数据显示,早高峰电话等待人数减少29%。此外,AI语音记录工具可为临床医生节省近四分之一的行政时间。该应用将于未来12个月向约20万患者开放,并计划于2028年4月前全面推广。

当AI助手“看“电脑屏幕,就像让一个视力正常的人蒙眼操作——德克萨斯大学达拉斯分校的解法
LUMOS是一个让AI通过操作系统无障碍接口直接读取界面语义信息来操控电脑的中间层,避免依赖截图识别,降低AI电脑操作的资源消耗和出错率。

Station F加速器助力欧洲AI创业公司崛起
巴黎创业中心Station F正在筹备其F/ai加速器项目的第二批次,计划于9月启动。第一批次吸引了AMD、Anthropic、OpenAI、Meta等众多科技巨头支持,20家AI初创公司共完成3400万美元的种子前融资,并已有两支团队获得国际认可。第二批次将新增ElevenLabs、Nebius、Rippling等合作伙伴,目标是帮助初创公司在六个月内实现100万欧元收入,推动欧洲AI创业生态发展。

腾讯混元携手多所高校,让3D网格生成快如闪电——PolyFlow如何破解困扰业界多年的“拓扑难题“
腾讯混元联合多所高校提出PolyFlow,用流匹配模型并行生成艺术家风格3D网格,速度比自回归方法快百倍,几何精度达到新高。
2023
12/07
14:29
分享
点赞

Station F加速器助力欧洲AI创业公司崛起
橡树岭国家实验室与克利夫兰诊所联合模拟聚变反应堆材料化学
Even Realities完成1.5亿美元融资,估值达10亿美元
数据中心会造成空气污染吗?关键在于电力来源
Day-0支持|摩尔线程完成美团LongCat-2.0极速适配
亚马逊Mechanical Turk停止接受新用户,众包平台走向终结
微软推出Memora,致力于解决AI智能体的记忆难题
SGE计划在英国部署14座BWRX-300小型模块堆,总装机容量达4.2吉瓦
特斯拉在迈阿密划定Robotaxi小范围服务区,得克萨斯扩张仍受阻
Luxonis完成1400万美元融资,为智能自动化打造视觉感知层
.NET 8 与 .NET 9 即将停止支持,微软建议升级至 .NET 10
苹果供应商塔塔电子遭黑客攻击,iPhone 18 Pro核心机密外泄
