
AMD这一把算是把AI玩明白了 原创
AMD已经不止一次使用“together we advance_”这个前缀作为主题,希望可以在各个层面都可以实现“同超越,共成就_”。
自2017年AMD回归数据中心处理器,到去年已经提供了第四代AMD EPYC(霄龙)处理器,帮助云、企业和高性能计算等关键应用负载。今年,AMD首席执行官苏姿丰(Lisa Su)也没有让我们失望,抢先带来了包括CPU和GPU在内的一系列更新。
迎来专注云原生的Bergamo
2022年,AMD发布了Zen 4架构的AMD EPYC处理器“Genoa”,Genoa在市场上一直有良好的表现,云工作负载中的性能是竞品处理器的1.8倍,企业工作负载中的速度是竞品处理器的1.9倍。
从2018年开始,亚马逊云科技就与AMD展开了合作,这次亚马逊云科技不仅展示了AMD实例在成本和性能上的优势,同时还宣布正在使用AWS Nitro和第四代EPYC Genoa处理器构建新实例Amazon EC2 M7a,目前Amazon EC2 M7a实例已经提供预览版,性能比M6a实例高出50%。AMD也会使用Amazon EC2 M7a实例处理内部的工作负载,包括芯片设计 EDA软件等。
今年,AMD在计算基础设施上又针对数据中心工作负载进行了优化,因为越来越多的应用都是云原生,AMD也带来了以吞吐量为导向,拥有最高终端密度和效率的AMD EPYC 97X4处理器“Bergamo”。
如果说Genoa是专注于通用的工作负载,Bergamo则专注于云服务器和数据中心,适用于云原生工作负载。
AMD EPYC Bergamo有高达128个内核,每个插槽有多达256个线程,一个普通的2U 4节点平台将有2048个线程。其是由820亿个晶体管组成,在尽可能小的空间内容纳尽可能多的计算能力,可提供一致的x86 ISA支持,最高的vCPU密度。AMD预计Bergamo在5年内将占所有数据中心处理器销售额的25%以上。
此次AMD EPYC Bergamo将Zen 4核心替换为Zen 4c,Zen 4c提供比Zen 4更高的密度,同时保持100%的软件兼容性。AMD优化了高速缓存层次结构,并进行了其他调整,从而节省了35%的裸片面积。CCD核心数量从8个增加到16个,CCD总数从12个减少到8个。

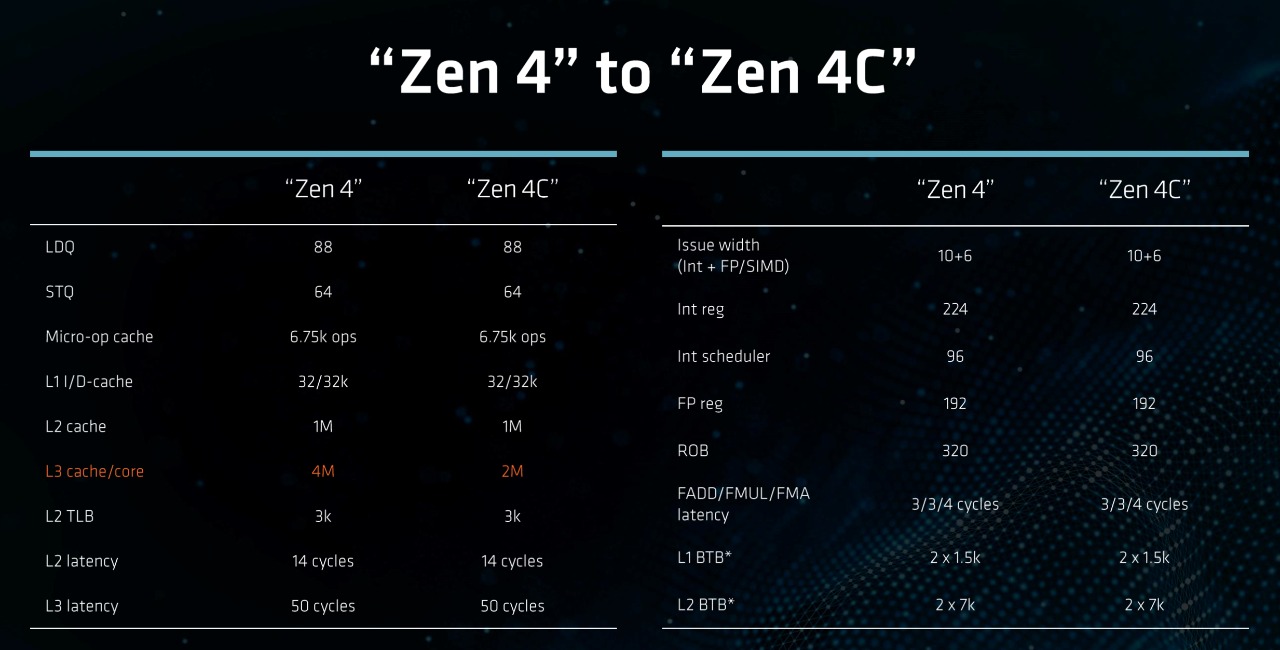
基于Zen 4c的Bergamo EPYC 9704系列处理器现已上市,目前包括EPYC 9754、EPYC 9754S、EPYC 9734三个型号。戴尔PowerEdge系列服务器已经实现支持,同时Bergamo处理器正在向大型云计算客户批量出货,Meta就计划在基础架构中使用 Bergamo,它的性能比上一代Milan芯片高出2.5倍。


除了Bergamo,AMD还带来了更针对技术计算的“Genoa-X”,以及针对电信和边缘计算的“Siena”,预计在下半年上市。

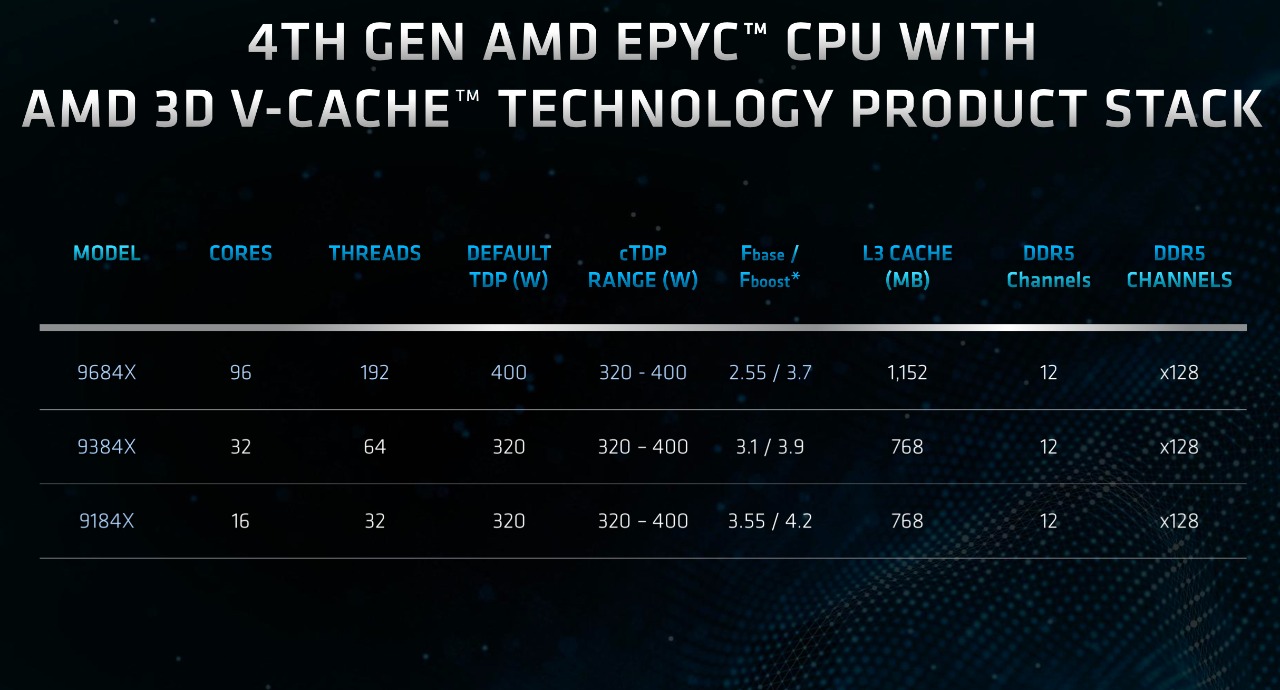
Genoa-X配备了3D V-Cache技术,通过在每个CCD顶部堆叠一个64MB L3 V-Cache芯片增加L3 缓存容量,让Genoa-X可以提供高达1152MB的总L3缓存。Genoa-X与具有相同内核数的友商处理器比较,在各方面都显示出了更强的优势。
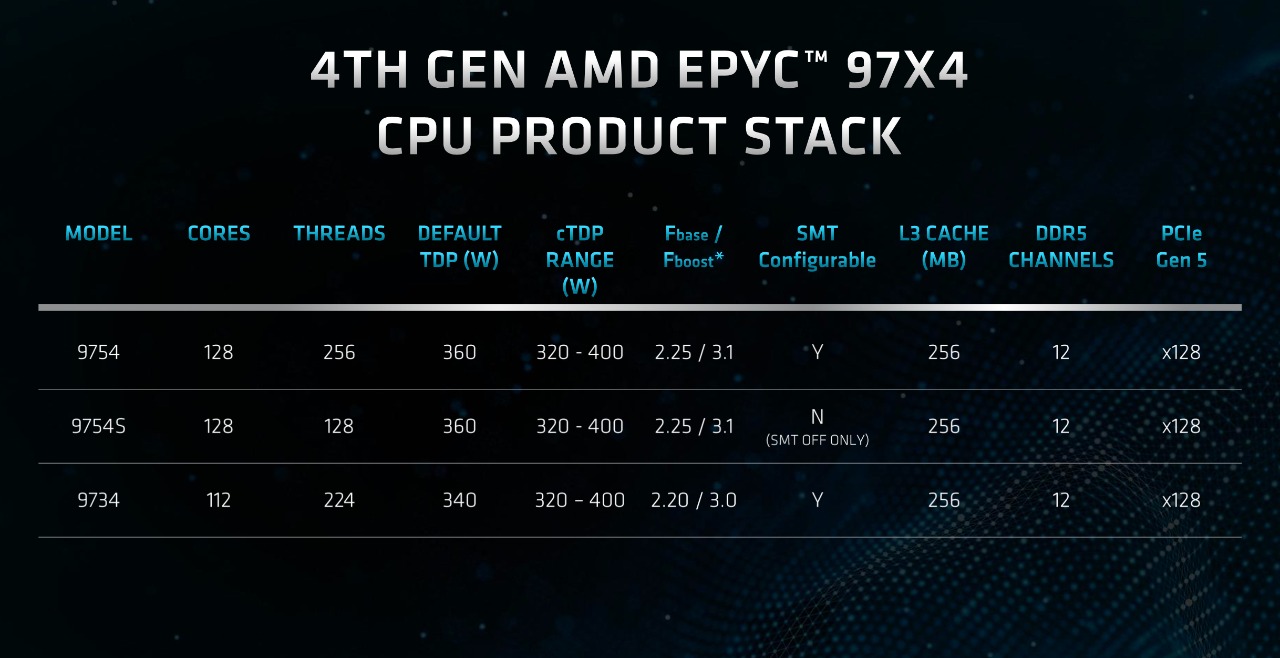
目前Genoa-X系列三个型号分别是,96核的EPYC 9684X、32核的EPYC 9384X、16核的EPYC 9184X。
Microsoft Azure也宣布最新高性能计算用虚拟机HBv4与Azure HX使用Genoa-X,内存将是前一代3倍,工作负载的性能提升最高达到5.7倍。
1530亿晶体管芯片现世MI300X
对于生成式AI,可能现在每个人、每个企业都在关注。Lisa Su说,AI是目前技术的决定性大趋势。她概述了由大型语言模型 (LLM) 驱动的AI市场存在着巨大的市场机会,导致数据中心AI加速器的TAM到2027年将会达到1500亿美元,CAGR将超过50%。
其实在2023年第一季度,AMD就推出了CPU+GPU架构的Instinct MI300正式进军AI训练端。MI300结合AMD的Zen 4 CPU与CDNA 3 GPU,通过“统一内存架构”突破GPU与CPU之间的数据传输速度限制,满足未来AI训练和推理中,海量数据计算和传输的需求。
今天万众瞩目的Instinct MI300系列产品又发布了MI300A和MI300X。
MI300A是全球首个为AI和HPC打造的APU加速卡,目前已出样。其拥有13个小芯片,总共包含1460亿个晶体管,采用了24个Zen 4内核、CDNA3 GPU内核和128GB HBM3内存。与 MI250 相比,其提供了8倍的性能和5倍的效率。


MI300X是AMD针对大语言模型优化的版本,拥有12个5nm的小芯片,晶体管数量达到了1530亿个。MI300X没有集成CPU内核,采用了8 个CDNA3 GPU内核和4个IO内存内核设计。内存达到了192GB,内存带宽为5.2TB/s,Infinity Fabric带宽为896GB/s。


MI300X提供的HBM(高带宽内存)密度约为英伟达H100的2.4倍,HBM带宽则为1.6倍,这让运行更大的模型成为可能,从而降低成本。
现在在单个GPU上运行一个400亿参数的模型,已经不在是幻想。MI300X可以支持400亿个参数的Hugging Face AI模型运行,最多可以运行800亿个参数的模型,而且使用多个MI300X叠加可以处理更多的参数。
现场Lisa Su演示了在单个MI300X上运行拥有400亿个参数的Falcon-40B大型语言模型,写了一首关于旧金山的诗。
MI300X将在第三季度出样,第四季度加大生产,以挑战英伟达在市场重的领先地位。
AMD还发布了新的Instinct平台,可以加快客户的上市时间,并降低总体开发成本。其基于OCP开放计算标准,将8块MI300X加速卡并行,可提供总计多达1.5TB HBM3内存。


而且为了突破CUDA这个护城河,AMD正在不断发展ROCm,这是一套完整的库和工具,可以优化AI软件堆栈。不同于专有的CUDA,ROCm软件栈可与模型、库、框架和工具的开放生态系统兼容。AMD总裁Victor Peng也希望,未来在AI软件生态系统开发中持续采用“开放(软件方法)、经过验证(AI能力)、就绪(支持AI模型)”的理念。
好文章,需要你的鼓励

英国NHS无人机快递医疗样本服务正式落地伦敦
英国国家医疗服务(NHS)正将无人机纳入常规医疗物流体系。自今年2月起,无人机每天在雷恩斯公园和圣乔治医院之间运送血液等诊断样本,飞行仅需3分钟,比公路运输快约85%,且碳排放减少高达98%。目前已有逾2000名患者受益。NHS计划将该服务扩展至圣赫利尔、克罗伊登等多家医院,最终惠及约180万名患者。该网络由英国医疗初创公司Apian与谷歌旗下Wing合作运营。

Explyt团队打造的代码智能体评测新标准:光靠“通过/失败“根本不够用
AgentLens是Explyt公司联合俄罗斯学术机构开发的AI编程助手评测基准,通过分析完整人机交互轨迹而非仅看最终结果,从五个维度评估代码智能体的真实表现。

Aetina宣布支持英伟达Jetson T3000和T2000 AI模块
边缘AI计算厂商Aetina宣布,将在其DeviceEdge AIE-KT风冷系列和新款AIE-PT无风扇平台上支持英伟达全新Jetson T3000和T2000模块。T3000基于Blackwell GPU,最高提供865 FP4 TFLOPS算力,功耗70W;T2000则提供400 FP4 TFLOPS,面向视觉AI代理和自主移动机器人等场景。两款模块预计2027年第一季度上市,支持Nemotron、Cosmos 3等英伟达AI软件生态。

机器人的“触觉觉醒“:韩国梨花女子大学如何让小型AI模型在不忘记视觉的前提下学会“感受“材质
韩国梨花女子大学提出Splash框架,通过识别AI模型中的"休眠参数"并只在其中训练触觉能力,让小型多模态AI在学会感知材质触感的同时,完整保留原有视觉语言推理能力。
2023
06/14
14:23
分享
点赞

WAIC2026 现场直击:开普勒顶流人气王,麒麟系列火爆出圈
面壁智能将密度定律带入具身智能
龙磁科技拟投3.58亿元扩建越南永磁铁氧体基地
首创一层Scale-up网络256卡全互联,摩尔线程MTT C256超节点为万卡及十万卡级集群夯实底座
从高血压诊疗入手,北京安贞医院让医疗大模型走出聊天框
西门子肖松:以场景为牵引,推动工业AI从单点实效迈向生产力跃迁
打造Token极致性价比 新华三震撼亮相2026世界人工智能大会
机器人管家系统上线!傅利叶携多款康养陪伴新品方案亮相WAIC 2026
赛那德“ 自主作业机器人天团” 登陆 WAIC:iLoabot-X+模型双升级,秀出具身场景落地硬实力
西门子Eigen工程智能体中国首发首展,荣获2026 WAIC SAIL之星奖
NVIDIA Cosmos 推动物理 AI 前沿发展
PPIO亮相WAIC 2026:发布智能模型网关,打造面向Agent时代的智能Token工厂
