
助力AI科研,IBM研究院打造Vela超级计算机
蓝色巨人在IBM Cloud中构建起Vela超级计算机,旨在帮助科学家创建并优化新的AI模型。
AI技术离不开强大的性能基础。IBM AI Research一直在研究新的数字与模拟处理器技术,希望借此加速AI处理速度。此次,蓝色巨人宣布在IBM Cloud中构建了一套包含60个机架的大型AI超级计算机,专门支持内部科学家和工程师。这项投资再次证实了AI技术对于研究企业的重要意义。可以想见,IBM未来可能会利用ChatGPT这类工具帮助客户群体、提升服务产品的运行效率。
最新公告
IBM研究院表示,他们已经在华盛顿特区的IBM Cloud基础设施内部署了一台包含60个机架的超级计算机,专门用于支持基础模型方面的研究。每个节点包含8个英伟达A100 GPU和80 GB HMB。IBM拒绝透露各机架安装有多少个节点,但可以肯定的是蓝色巨人这次是砸下了重金。有趣的是,IBM并没有使用HPC中常见的高成本网络互连,而是轻松通过100 Gb以太网卡承载了各节点间的通信。
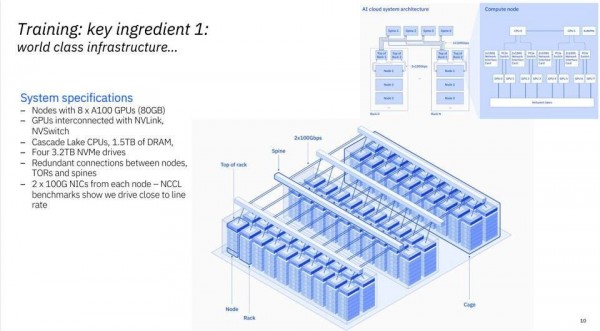
Vela超级计算机目前仅供IBM研究院的内部团队成员使用。
IBM还决定设计一个基于虚拟机的集群接口,而没有采用性能水平更高的裸机配置。IBM在博文中解释道,“我们也曾思考,到底要如何在虚拟机内部实现相当于裸机的性能?经过大量研究和发现,我们设计出一种方法,将节点上的所有功能(GPU、CPU、网络和存储)都公开到虚拟机内,这样就能让虚拟化的资源开销低于5%。根据我们无意间了解到的行业情况,这已经是最低水平了。”Vela还被原生集成至IBM Cloud的VPC环境当中,因此AI工作负载可以直接与当前200多种IBM Cloud服务随意对接。
IBM研究人员正在使用这套云端超级计算机,深入探究基础模型的执行和行为方式。最近一段时间,大语言模型已经一次又一次撼动整个行业。OpenAI打造的ChatGPT甚至在很多人眼中成为了AI版本的“iPhone时刻”。这类模型不需要监督,但却要耗费海量算力。例如,由微软Azure托管的OpenAI超级计算机就搭载10000个英伟达GPU。

IBM正使用开源“RAY”处理数据并验证基础模型。
IBM目前正倾注心力,希望帮客户建立起亲自使用这些模型的能力。除了需要占用大量资源的训练环节之外,整体流程中的数据准备、模型调整和推理处理等工作,也都拉高了客户的理解和实施门槛。
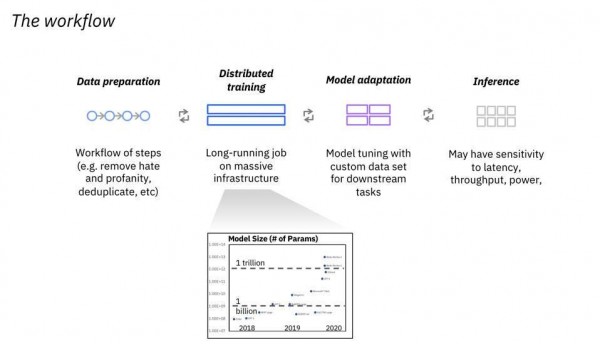
IBM关注整个工作流程,希望帮助客户为基础模型的全面普及做好准备。
从下图可以看到,IBM的目标是对特定模型版本进行定制,确保其满足特定业务需求,并将基础模型托管在云端。ChatGPT采用的是GPT3,这套模型自2021年之后就没有重新训练过了。IBM能不能找到可靠的模型更新或定制方法,又回避成本可能高达数百万美元的重新训练?看来蓝色巨人对自己很有信心。

在无监督情况下训练的基础模型,可以针对特定工作负载进行微调。
总结
我们最初听说IBM AI Research时,就对他们在实验室中使用的低精度数字AI处理器,以及用于推理/训练的模拟计算基础研究印象深刻。到现在,我们才真正理解该部门关注此类技术的根本原因:基础模型就是未来,IBM希望引领自己的客户群体在充分的准备之下,大规模拥抱和部署这些模型——可能是客户的本地基础设施中,也可以在IBM Cloud或者其他公有云上。总之,在这个AI模型为王的新时代,IBM表示自己必须占据一席之地。
好文章,需要你的鼓励


Savi Security:用AI实时拦截AI诈骗电话与短信
Savi Security由Patrick和Ryan Coughlin兄弟创立,融资700万美元,并正式推出iOS和Android应用。该应用可实时筛查短信、语音邮件和来电,识别AI生成的诈骗内容。其核心功能是通话实时监控,用户可在可疑通话中邀请AI助手同步监听,分析行为特征。产品以家庭为单位收费,每月8美元,不限用户数量。FTC数据显示,2025年冒充诈骗造成损失高达35亿美元,是2020年的三倍。

香港中文大学(深圳)与字节跳动联手,造出能“自由调速“的语音大模型
香港中文大学(深圳)与字节跳动联合提出FlexiSLM,首个支持动态与可控帧率的语音大模型,在输入输出两端均实现自适应帧合并,6.25赫兹下推理速度提升一倍,语音对话质量超越同规模固定帧率模型。

Argo CD漏洞警示:GitOps基础设施应被视为零级核心资产
安全公司Synacktiv披露了Argo CD中一个未修复的高危漏洞,影响其repo-server组件的未认证gRPC端点。攻击者若能访问该端点及Redis数据库端口,可执行恶意命令、篡改部署数据,并在启用Auto Sync时自动推送恶意配置。由于Helm chart部署默认未启用网络策略保护,集群内任意受损Pod均可触发攻击。专家建议企业将Argo CD视为零级控制平面组件,实施严格的东西向流量隔离与特权访问管控。

中南大学团队打造“自我进化“的AI训练数据工厂:被丢弃的“废品“竟是最好的老师
这项研究提出DataEvolver框架,把被丢弃的"不合格训练图片"转化为改进数据收集策略的反馈,让AI文字图像生成训练数据的构建流程能自我进化,在相同数据量下显著提升文字渲染质量。
2023
02/08
14:33
分享
点赞

Argo CD漏洞警示:GitOps基础设施应被视为零级核心资产
AI投资拖累科技巨头气候承诺,碳排放持续攀升
Voltpost携手InCharge Energy,路灯电动车充电桩加速在美国扩张
Sonair发布全球首款获安全认证的3D超声波传感器
Niantic Spatial为Scaniverse新增USDZ导出功能,助力机器人仿真工作流
仿脑光传感器有望加速AI图像处理
Norm Ai融资1.2亿美元,估值达12亿美元,以AI智能体重塑法律服务
Bidbus获1500万美元融资,让经销商竞价收购你的二手车
AI法律创业公司Norm完成1.2亿美元C轮融资,跻身独角兽行列
征程赶超|WAIC 2026理论突破:以数理双向赋能为钥,开启AI范式革新新征程
征程赶超|WAIC 2026 Token经济:按下加速键,从技术计量到产业新范式
征程赶超|WAIC 2026科学智能:AI4S从“辅助计算”到“自主发现”,中国如何重塑全球科研版图?
