
浪潮分布式存储:让数据融合互通,为“云数智”应用构筑新平台
数字时代,数据共享互通成为刚需
数字经济时代,云计算、大数据、人工智能等新技术快速发展,非结构化数据爆发式增长,数据类型变得愈发复杂多样。在自动驾驶、基因测序、气象预报等云数智应用场景中,一次数据处理可能会涉及到文件、对象、大数据等多种协议,数据间的互通转换成为数据存储中至关重要的一环,具备平台化能力的融合存储成为数字基础设施建设的核心。
以基因测序场景为例,一次完整的基因测序涉及到数据采集、格式化、脱敏、压缩、分析、发布等操作,其过程可以大致分为样本采集、DNA/RNA测序、数据分析和发布四个步骤。在不同的处理阶段,需要使用不同的数据协议进行操作。其中在样本采集和DNA/RNA测序阶段采用NFS文件协议,数据分析阶段采用HDFS大数据协议,数据发布阶段则是通过公网数据共享采用S3对象协议。整个数据处理过程涉及三种协议格式,这就意味着完成一次基因的测序流程需要在NFS、HDFS和S3之间进行两次数据拷贝和数据格式的转换。传统存储仅支持单一的访问协议,这就会造成两个问题:一是数据格式转换和数据拷贝会降低整个数据处理流程的效率;二是多套存储副本增加存储空间成本。
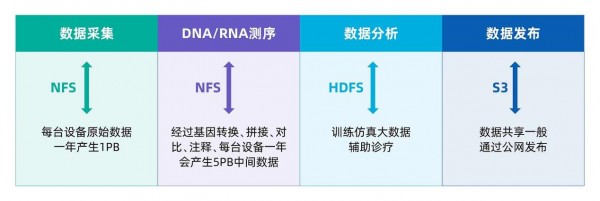
基因测序应用需要使用多种数据协议
百川入海:浪潮基于一套存储 承载多样化数据
浪潮分布式存储平台AS13000基于对非结构化数据协议(NFS/CIFS/HDFS/S3)融合互通的研究进行技术创新,采用统一的数据管理和元数据管理、统一的增值特性服务、统一的分布式存储资源池和统一的管理软件系统,保证各种协议共享同一份数据和元数据。访问过程中无需数据转换和拷贝,并且为每种协议提供原生语义服务,每种服务均可直接访问,无需安装网关、插件或在计算侧或应用层进行改造。
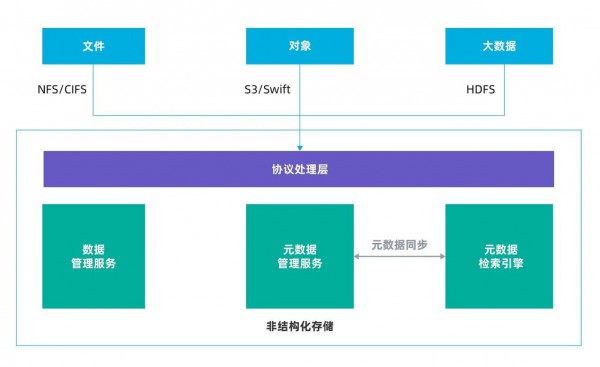
AS13000非结构化数据融合架构
基于“多合一”极简架构,浪潮分布式存储得以实现四个“统一”。
首先,提供统一的数据管理和元数据管理。
数据管理和元数据管理是非结构化数据存储的关键,浪潮分布式存储平台AS13000根据NFS、CIFS、HDFS和S3的语义和元数据特点,抽象各协议的数据和元数据操作,通过一套统一的非结构化数据和元数据管理架构有效地保证各协议的原生访问。
其次,提供统一的增值特性服务。
基于统一的数据访问接口和元数据管理的架构设计,浪潮AS13000对外提供统一的增值特性服务,包括统一配额、QoS、加密、压缩、快照、回收站、分级存储、远程复制、元数据检索等等。
以下图为例:同一个元数据检索服务ElasticSearch支持NFS、CIFS、S3、HDFS多种协议,并且各协议为同一配置入口和查询入口。
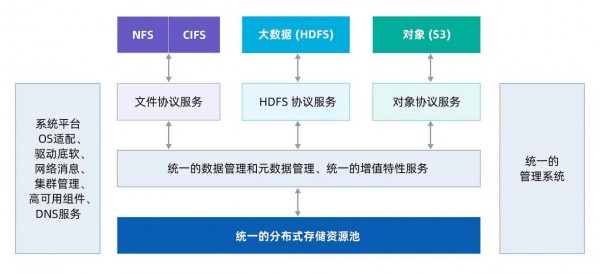
统一增值特性示例:元数据检索服务
再次,构建统一的分布式存储资源池。
AS13000支持NFS/CIFS/HDFS/S3等多种服务协议共享非结构化存储资源池,并且同一个文件不同协议访问的数据和元数据为同一份。例如,通过文件NFS协议写入的一个文件,通过对象存储AWS S3协议、大数据HDFS协议和文件CIFS协议均可读取;每个节点都可以启动文件NAS、大数据HDFS和对象存储S3服务。
最后,打造统一的管理系统。
管理软件负责集群的安装、部署、业务配置、设备管理、监控、告警等功能。浪潮分布式存储平台AS13000打造了融合互通的管理系统,可同时支持NFS/CIFS/HDFS/S3等多种服务协议,增值特性通过统一的配置入口对所有非结构化存储协议同时生效,减少了企业的管理成本。
浪潮分布式存储平台AS13000通过多年来的持续技术创新,以一份数据支持多种协议访问,实现了非结构化数据融合互通,在提升数据处理效率的同时降低了存储购置和运维成本,保障各协议的语义无损和性能无损,构筑了面向“云数智”应用的融合存储平台,助力企业数字化转型,加速释放数据价值。
来源:业界供稿
好文章,需要你的鼓励



明尼苏达大学最新研究颠覆认知:训练AI大模型,只需动其中一层就够了?
这项来自明尼苏达大学等机构的研究发现,大语言模型在强化学习后训练中,只需训练中间少数几层即可匹配甚至超越全参数训练效果,且这一规律跨模型、跨任务高度稳定,为更高效的AI训练策略提供了新思路。


台湾大学与NVIDIA揭秘:你的声音正在悄悄改变AI对你的判断
本文介绍VIBE框架,一套通过开放式任务评估大型音频语言模型声音诱发偏见的系统,测试12个模型后发现每个模型均存在显著性别或口音偏见。
2023
02/02
17:55
分享
点赞

边缘智算筑基、全栈软硬协同,研华科技将AI带进产业闭环
千问AI眼镜将升级为智能体眼镜:能灵活调用Skill和Agent,能全天候感知
对话Moonix郭于晨:先让用户戴上“眼镜”,再让“AI”记录世界
亮相WAIC 2026,临床实证赋能康养升级 无芯科技定义AI疗愈新范式
生态覆盖持续扩散,一文看懂各行业企业鸿蒙化转型进度
WAIC亮出集群协作真功夫,优艾智合领跑工业具身智能规模化
脑部植入物助瘫痪男子重获进食与饮水能力
能源公司IPO融资创21世纪新高,押注AI基础设施热潮
Apple Intelligence获中国监管批准,携手阿里巴巴与百度正式进入中国市场
Moonshot即将发布的Kimi K3有望赶超Anthropic Opus 4.8
OpenAI 为何开始卖 ChatGPT 品牌篮球?
DoorDash推出命令行工具,开发者可借助AI智能体直接下单
