
Triton推理服务器13-模型与调度器(3)
前面两篇文章,已经将Triton的“无状态模型”、“有状态模型”与标准调度器的动态批量处理器与序列批量处理器的使用方式,做了较完整的说明。
大部分的实际应用都不是单纯的推理模型就能完成服务的需求,需要形成前后关系的工作流水线。例如一个二维码扫描的应用,除了需要第一关的二维码识别模型之外,后面可能还得将识别出来的字符传递给语句识别的推理模型、关键字搜索引擎等功能,最后找到用户所需要的信息,反馈给提出需求的用户端。
本文的内容要说明Triton服务器形成工作流水线的“集成推理”功能,里面包括“集成模型(ensemble model)”与“集成调度器(ensemble scheduler)”两个部分。下面是个简单的推理流水线示意图,目的是对请求的输入图像最终反馈“图像分类”与“语义分割”两个推理结果:
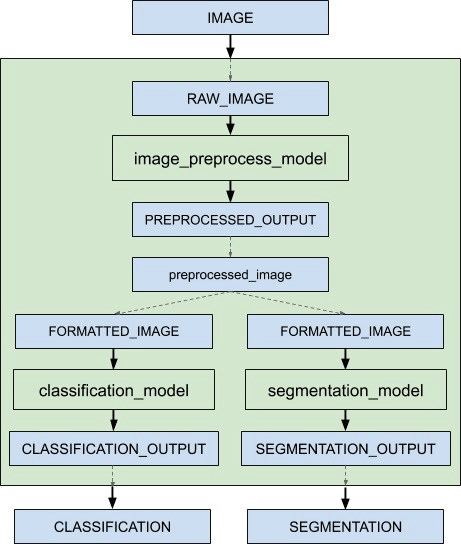
当接收到集成模型的推断请求时,集成调度器将:
- 确认请求中的“IMAGE”张量映射到预处理模型中的输入“RAW_IMAGE”。
- 检查集合中的模型,并向预处理模型发送内部请求,因为所需的所有输入张量都已就绪。
- 识别内部请求的完成,收集输出张量并将内容映射到“预处理图像”,这是集成中已知的唯一名称。
- 将新收集的张量映射到集合中模型的输入。在这种情况下,“classification_model”和“segmentation_model“的输入将被映射并标记为就绪。
- 检查需要新收集的张量的模型,并向输入就绪的模型发送内部请求,在本例中是分类模型和分割模型。请注意,响应将根据各个模型的负载和计算时间以任意顺序排列。
- 重复步骤3-5,直到不再发送内部请求,然后用集成输出名称的张量去响应推理请求。
整个流水线使用3个模型,并进行以下三个处理步骤:
- 使用image_prepoecess_model模型,将原始图像处理成preprocessed_image数据;
- 将preprocessed_image数据传递给classification_model模型,执行图像分类推理,最终返回“CLASSIFICATION”结果;
- 将preprocessed_image数据传递给segmentation_model模型,执行语义分割推理计算,最终返回“SEGMENTATION”结果;
在执行过程中,推理服务器必须支持以下的功能,才能将多种推理模型集成一个或多个工作流水线,去执行完整的工作流程:
- 支持一个或多个模型的流水线以及这些模型之间输入和输出张量的连接;
- 处理多个模型的模型拼接或数据流,例如“数据处理->推理->数据后处理”等;
- 收集每个步骤中的输出张量,并根据规范将其作为其他步骤的输入张量;
- 所集成的模型能继承所涉及模型的特征,在请求方的元数据必须符合集成中的模型;
为了实现的推理流水线功能,Triton服务器使用集成模型与集成调度器的配合,来完成这类工作流水线的搭建管理。接着就执行以下步骤来创建一个流水线所需要的配套内容:
- 在模型仓里为流水线创建一个新的“组合模型”文件夹,例如为“ensemble_model”;
- 在目路下创建新的config.pbtxt,并且使用“platform: "ensemble"”来定义这个模型要执行集成功能;
- 定义集成模型:
无论工作流水线中调用多少个模型,Triton服务器都将这样的组合视为一个模型,与其他模型配置一样,需要定义输入与输出节点的张量类型与尺度。
以上面实示例图中的要求,这个集成模型有一个名为“IMAGE”的输入节,与两个名为“CLASSIFICATION”与“SEGMENTATION”的输出节点,至于数据类型与张量维度内容,就得根据实际使用的模型去匹配。这部分配置的参考内容如下:
|
name: "ensemble_model" platform: "ensemble" max_batch_size: 1 input [ { name: "IMAGE" data_type: TYPE_STRING dims: [ 1 ] } ] output [ { name: "CLASSIFICATION" data_type: TYPE_FP32 dims: [ 1000 ] }, { name: "SEGMENTATION" data_type: TYPE_FP32 dims: [ 3, 224, 224 ] } ] |
从这个内容中可以看出,Triton服务器将这个集成模型视为一个独立模型。
- 定义模型的集成调度器:
这部分使用“ensemble_scheduling”来调动集成调度器,将使用到模型与数据形成完整的交互关系。
在上面示例图中,灰色区块所形成的工作流水线中,使用到image_prepoecess_model、classification_model、segmentation_model三个模型,以及preprocessed_image数据在模型中进行传递。
下面提供这部分的范例配置内容,一开始使用“ensemble_scheduling”来调用集成调度器,里面再用“step”来定义模组之间的执行关系,透过模型的“input_map”与“output_map”的“key:value”对的方式,串联起模型之间的交互动作:
|
ensemble_scheduling { step [ { model_name: "image_preprocess_model" model_version: -1 input_map { key: "RAW_IMAGE" value: "IMAGE" } output_map { key: "PREPROCESSED_OUTPUT" value: "preprocessed_image" } }, { model_name: "classification_model" model_version: -1 input_map { key: "FORMATTED_IMAGE" value: "preprocessed_image" } output_map { key: "CLASSIFICATION_OUTPUT" value: "CLASSIFICATION" } }, { model_name: "segmentation_model" model_version: -1 input_map { key: "FORMATTED_IMAGE" value: "preprocessed_image" } output_map { key: "SEGMENTATION_OUTPUT" value: "SEGMENTATION" } } ] } |
这里简单说明一下工作流程:
- 模型image_preprocess_model接收外部输入的IMAGE数据,进行图像预处理任务,输出preprocessed_image数据;
- 模型classification_model的输入为preprocessed_image,表示这个模型的工作是在image_preprocess_model之后的任务,执行的推理输出为CLASSIFICATION;
- 模型segmentation_model的输入为preprocessed_image,表示这个模型的工作是在image_preprocess_model之后的任务,执行的退输出为SEGMENTATION;
- 上面两步骤可以看出classification_model与segmentation_model属于分支的同级模型,与上面工作流图中的要求一致。
完成以上的步骤,就能用集成模型与集成调度器的搭配,来创建一个完整的推理工作流任务,相当简单。
不过这类集成模型中,还有以下几个需要注意的重点:
- 这是Triton服务器用来执行用户定义模型流水线的抽象形式,由于没有与集成模型关联的物理实例,因此不能为其指定instance_group字段;
- 不过集成模型内容所组成的个别模型(例如image_preprocess_model),可以在其配置文件中指定instance_group,并在集成接收到多个请求时单独支持并行执行。
- 由于集成模型将继承所涉及模型的特性,因此在请求起点的元数据(本例为“IMAGE”)必须符合集成中的模型,如果其中一个模型是有状态模型,那么集成模型的推理请求应该包含有状态模型中提到的信息,这些信息将由调度器提供给有状态模型。
总的来说,Triton服务器提供的集成功能还是相对容易理解与操作的,只要大家留意模型之间所传递的数据张量格式与尺度,就能轻松搭建起这样的推理工作流,去面对实际环境中更多变的使用需求。【完】
来源:业界供稿
好文章,需要你的鼓励


奥运级别的努力:首席信息官为2026年AI颠覆做准备
AI颠覆预计将在2026年持续,推动企业适应不断演进的技术并扩大规模。国际奥委会、Moderna和Sportradar的领导者在纽约路透社峰会上分享了他们的AI策略。讨论焦点包括自建AI与购买第三方资源的选择,AI在内部流程优化和外部产品开发中的应用,以及小型模型在日常应用中的潜力。专家建议,企业应将AI建设融入企业文化,以创新而非成本节约为驱动力。

字节跳动发布GAR:让AI能像人类一样精准理解图像任何区域的突破性技术
字节跳动等机构联合发布GAR技术,让AI能同时理解图像的全局和局部信息,实现对多个区域间复杂关系的准确分析。该技术通过RoI对齐特征重放方法,在保持全局视野的同时提取精确细节,在多项测试中表现出色,甚至在某些指标上超越了体积更大的模型,为AI视觉理解能力带来重要突破。

Spotify推出AI播放列表功能让用户掌控推荐算法
Spotify在新西兰测试推出AI提示播放列表功能,用户可通过文字描述需求让AI根据指令和听歌历史生成个性化播放列表。该功能允许用户设置定期刷新,相当于创建可控制算法的每周发现播放列表。这是Spotify赋予用户更多控制权努力的一部分,此前其AI DJ功能也增加了语音提示选项,反映了各平台让用户更好控制算法推荐的趋势。

Inclusion AI推出万亿参数思维模型Ring-1T:首个开源的超大规模推理引擎如何重塑AI思考边界
Inclusion AI团队推出首个开源万亿参数思维模型Ring-1T,通过IcePop、C3PO++和ASystem三项核心技术突破,解决了超大规模强化学习训练的稳定性和效率难题。该模型在AIME-2025获得93.4分,IMO-2025达到银牌水平,CodeForces获得2088分,展现出卓越的数学推理和编程能力,为AI推理能力发展树立了新的里程碑。
2023
02/02
15:34
分享
点赞

为全天候绿电而生,海辰储能发布全球首个原生8小时长时储能解决方案
为AI+而生,海辰储能发布全球首款锂钠协同AIDC全时长储能解决方案
长时储能开启智慧未来:海辰储能生态日全球首发三大新品
Arm 借助融合型 AI 数据中心,重塑计算格局
奥运级别的努力:首席信息官为2026年AI颠覆做准备
Spotify推出AI播放列表功能让用户掌控推荐算法
Adobe押注生成式AI获得回报,年度营收创历史新高
OpenAI与迪士尼达成十亿美元合作协议,米老鼠和漫威角色进入Sora
甲骨文150亿美元数据中心投资导致股价下跌
Spoor鸟类监测AI软件需求飞速增长
制药行业AI数据质量危机:垃圾进垃圾出的隐患
Harness获得2.4亿美元融资,估值达55亿美元,专注自动化AI编码后的开发流程
分析:NVIDIA第二季度财报再次超出预期背后的新问题
Jetson百万开发者故事 | 校企合作推动实现多项工业场景下AI边缘计算应用
Jetson百万开发者故事 | NVIDIA Jetson助力水产养殖企业打造自动化流水线
Jetson百万开发者故事 | 基于Jetson Nano的便携式岩石分类检测系统:地质学家的新利器
Jetson百万开发者故事 | 让AI成为铁路客运站自动扶梯安全管控的关键
Jetson百万开发者故事 | Jetson开发者突破百万,从TK1到Orin我都经历了啥
百万Jetson开发者故事
Jetson百万开发者故事 | NVIDIA Jetson如何成为可移动智能脑机交互平台
全新NVIDIA Jetson Orin NX 16GB大幅提升边缘AI性能
Triton推理服务器13-模型与调度器(3)
