
Triton推理服务器12-模型与调度器(2)
在“Triton推理服务器11-模型调度器(1)”文章中,已经说明了有状态(stateful)模型的“控制输入”与“隐式状态管理”的使用方式,本文内容接着就继续说明“调度策略”的使用。
(续前一篇文章的编号)
- 调度策略(Scheduling Strategies)
在决定如何对分发到同一模型实例的序列进行批处理时,序列批量处理器(sequence batcher)可以采用以下两种调度策略的其中一种:
- 直接(direct)策略
当模型维护每个批量处理槽的状态,并期望给定序列的所有推理请求都分发到同一槽,以便正确更新状态时,需要使用这个策略。此时,序列批量处理程序不仅能确保序列中的所有推理请求,都会分发到同一模型实例,并且确保每个序列都被分发至模型实例中的专用批量处理槽(batch slot)。
下面示例的模型配置,是一个TensorRT有状态模型,使用直接调度策略的序量批处理程序的内容:
|
name: "direct_stateful_model" platform: "tensorrt_plan" max_batch_size: 2 sequence_batching { max_sequence_idle_microseconds: 5000000 direct { } control_input [ { name: "START" control [ { kind: CONTROL_SEQUENCE_START fp32_false_true: [ 0, 1 ] } ] }, { name: "READY" control [ { kind: CONTROL_SEQUENCE_READY fp32_false_true: [ 0, 1 ] } ] } ] } # 续接右栏 |
# 上接左栏 input [ { name: "INPUT" data_type: TYPE_FP32 dims: [ 100, 100 ] } ] output [ { name: "OUTPUT" data_type: TYPE_FP32 dims: [ 10 ] } ] instance_group [ { count: 2 } ]
|
现在简单说明以下配置的内容:
- sequence_batching部分指示模型会使用序列调度器的Direct调度策略;
- 示例中模型只需要序列批处理程序的启动和就绪控制输入,因此只列出这些控制;
- instance_group表示应该实例化模型的两个实例;
- max_batch_size表示这些实例中的每一个都应该执行批量大小为2的推理计算。
下图显示了此配置指定的序列批处理程序和推理资源的表示:
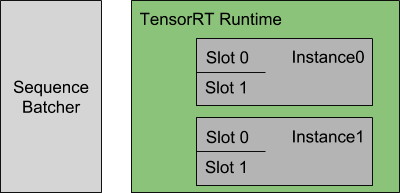
每个模型实例都在维护每个批处理槽的状态,并期望将给定序列的所有推理请求分发到同一槽,以便正确更新状态。对于本例,这意味着Triton可以同时4个序列进行推理。
使用直接调度策略,序列批处理程序会执行以下动作:
|
所识别的推理请求种类 |
执行动作 |
|
需要启动新序列 |
|
|
是已分配处理槽序列的一部分 |
将该请求分发到该配置好的批量处理槽 |
|
是积压工作中序列的一部分 |
将请求放入积压工作中 |
|
是最后一个推理请求 |
|
下图显示使用直接调度策略,将多个序列调度到模型实例上的执行:

左边显示了到达Triton的5个请求序列,每个序列可以由任意数量的推理请求组成。图右侧显示了推理请求序列是如何随时间安排到模型实例上的,
- 在实例0与实例1中各有两个槽0与槽1;
- 根据接收的顺序,为序列0至序列3各分配一个批量处理槽,而序列4与序列5先处于排队等候状态;
- 当序列3的请求全部完成之后,将处理槽释放出来给序列4使用;
- 当序列1的请求全部完成之后,将处理槽释放出来给序列5使用;
以上是直接策略对最基本工作原理,很容易理解。
接下来要进一步使用控制输入张量与模型通信的功能,下图是一个分配给模型实例中两个批处理槽的两个序列,每个序列的推理请求随时间而到达,START和READY行显示用于模型每次执行的输入张量值:
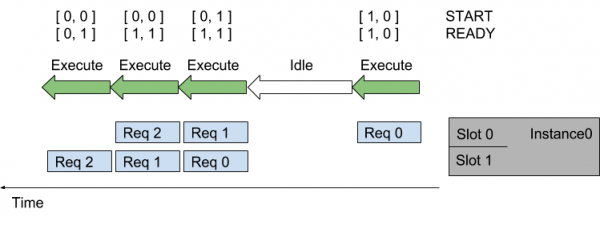
随着时间的推移(从右向左),会发生以下情况:
- 序列中第一个请求(Req 0)到达槽0时,因为模型实例尚未执行推理,则序列调度器会立即安排模型实例执行,因为推理请求可用;
- 由于这是序列中的第一个请求,因此START张量中的对应元素设置为1,但槽1中没有可用的请求,因此READY张量仅显示槽0为就绪。
- 推理完成后,序列调度器会发现任何批处理槽中都没有可用的请求,因此模型实例处于空闲状态。
- 接下来,两个推理请求(上面的Req 1与下面的Req 0)差不多的时间到达,序列调度器看到两个处理槽都是可用,就立即执行批量大小为2的推理模型实例,使用READY来显示两个槽都有可用的推理请求,但只有槽1是新序列的开始(START)。
- 对于其他推理请求,处理以类似的方式继续。
以上就是配合控制输入张量的工作原理。
- 最旧的(oldest)策略
这种调度策略能让序列批处理器,确保序列中的所有推理请求都被分发到同一模型实例中,然后使用“动态批处理器”将来自不同序列的多个推理批量处理到一起。
使用此策略,模型通常必须使用CONTROL_SEQUENCE_CORRID控件,才能让批量处理清楚每个推理请求是属于哪个序列。通常不需要CONTROL_SEQUENCE_READY控件,因为批处理中所有的推理都将随时准备好进行推理。
下面是一个“最旧调度策略”的配置示例,以前面一个“直接调度策略”进行修改,差异之处只有下面所列出的部分,请自行调整:
|
直接(direct)策略 |
最旧的(oldest)策略 |
|
direct { }
|
oldest { max_candidate_sequences: 4 } |
在本示例中,模型需要序列批量处理的开始、结束和相关ID控制输入。下图显示了此配置指定的序列批处理程序和推理资源的表示。
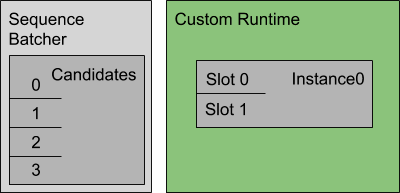
使用最旧的调度策略,序列批处理程序会执行以下工作:
|
所识别的推理请求种类 |
执行动作 |
|
需要启动新序列 |
尝试查找具有候选序列空间的模型实例,如果没有实例可以容纳新的候选序列,就将请求放在一个积压工作中 |
|
已经是候选序列的一部分 |
将该请求分发到该模型实例 |
|
是积压工作中序列的一部分 |
将请求放入积压工作中 |
|
是最后一个推理请求 |
模型实例立即从积压工作中删除一个序列,并将其作为模型实例中的候选序列,或者记录如果没有积压工作,模型实例可以处理未来的序列。 |
下图显示将多个序列调度到上述示例配置指定的模型实例上,左图显示Triton接收了四个请求序列,每个序列由多个推理请求组成:
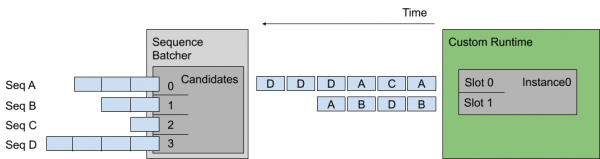
这里假设每个请求的长度是相同的,那么左边候选序列中送进右边批量处理槽的顺序,就是上图中间的排列顺序。
最旧的策略从最旧的请求中形成一个动态批处理,但在一个批处理中从不包含来自给定序列的多个请求,例如上面序列D中的最后两个推理不是一起批处理的。
以上是关于有状态模型的“调度策略”主要内容,剩下的“集成模型”部分,会在“Triton推理服务器13-模型调度器(3)”文中提供完整的说明。【未完,待续】
来源:业界供稿
好文章,需要你的鼓励


科创新源拟用 2.45 亿元收购导热材料企业,新加坡智科承接海外资产整合
今天讲的出海案例是科创新源,这家高分子材料与液冷板厂商拟用 2.45 亿元收购兆科控制权,并拟通过新加坡智科整合越南制造与海外经营资产。

香港理工大学提出“光学推理“:用图片代替文字做推理,效率翻近两倍
香港理工大学提出"光学推理",将AI推理步骤渲染为图片代替文字,在五款顶级AI模型测试中平均节省28%令牌,效率近两倍。

iOS 27 相册 AI 新功能深度解析:苹果如何在不失真的前提下完善你的照片记忆
苹果高管在最新采访中详细介绍了iOS 27照片应用的三项AI新功能。"空间重构"可在拍摄后调整照片构图视角,仅在视角偏移处生成新内容;"扩展"功能允许用户向外延伸画面最多25%,且每张照片仅限使用一次,防止过度修改;"清除"功能则升级为可处理更复杂的对象。苹果强调,所有功能的核心目标是在保留原始记忆真实感的同时,帮助用户完善影像效果。

AI评测系统竟能被轻易“作弊“?卡内基梅隆大学等机构发现16%的测试题可被绕过,并研发出自动防御工具
卡内基梅隆大学等机构发现,16%的主流AI评测任务存在可被绕过的漏洞,并提出三智能体自动防御方案,将KernelBench攻击成功率从76%降至0%。
2023
02/02
15:33
分享
点赞

科创新源拟用 2.45 亿元收购导热材料企业,新加坡智科承接海外资产整合
iOS 27 相册 AI 新功能深度解析:苹果如何在不失真的前提下完善你的照片记忆
iOS 27 Beta 1 新听写功能默认关闭,附开启教程
软通动力向沙特交付机械革命硬件项目,全栈智能业务进入中东本地合作阶段
索尼AI乒乓球机器人如何推动物理AI技术发展
Parallel Systems CEO:我们正在构建全球首个自主货运铁路系统
Dietsmann携机器人技术亮相非洲能源周,推动智能化运维转型
DJI与Insta360专利大战全面爆发,创作者科技领域迎来史上最激烈竞争
桑达尔·皮查伊斯坦福毕业典礼演讲:加州乐观主义与做有价值的难事
MassRobotics宣布2026年机器人奖章得主:斯坦福大学冈村·艾莉森与首尔国立大学金雅英获此殊荣
更便宜、更快速、更懂本土文化:Avataar AI视频模型专为印度规模化场景而生
诺和诺德遭遇网络攻击,患者数据外泄
分析:NVIDIA第二季度财报再次超出预期背后的新问题
Jetson百万开发者故事 | 校企合作推动实现多项工业场景下AI边缘计算应用
Jetson百万开发者故事 | NVIDIA Jetson助力水产养殖企业打造自动化流水线
Jetson百万开发者故事 | 基于Jetson Nano的便携式岩石分类检测系统:地质学家的新利器
Jetson百万开发者故事 | 让AI成为铁路客运站自动扶梯安全管控的关键
Jetson百万开发者故事 | Jetson开发者突破百万,从TK1到Orin我都经历了啥
百万Jetson开发者故事
Jetson百万开发者故事 | NVIDIA Jetson如何成为可移动智能脑机交互平台
全新NVIDIA Jetson Orin NX 16GB大幅提升边缘AI性能
Triton推理服务器13-模型与调度器(3)
