
Triton推理服务器03-开发资源说明
大部分要学习Triton推理服务器的入门者,都会被搜索引擎或网上文章引导至官方的https://developer.nvidia.com/nvidia-triton-inference-server处(如下截图),然后从“Get Started”直接安装服务器与用户端软件、创建基础的模型仓、执行一些最基本的范例。

这条路径虽然能在很短时间内跑起Triton的应用,但在未掌握整个应用架构之前便贸然执行,反倒容易让初学者陷入迷失的状态,因此建议初学者最好先对Triton项目有比较更完整的了解之后,再执行前面的“Get Started”就会更容易掌握项目的精髓。
要获得比较完整的Triton技术资料,就得到项目开源仓里去寻找。与NVIDIA其他放在https://github.com/NVIDIA或https://github.com/NVIDIA-AI-IOT的项目不同,Triton项目有独立的开源仓,位置在https://github.com/triton-inference-server,进入开源仓后会看到如下截屏的内容:
下面列出四大部分的技术资源:
- Getting Start(新手上路):
这里提供三个链接,比较重要的是“Quick Start(快速启动)”的部分,提供以下三个步骤就能轻松执行Triton的基础示范:
- Create a Model Repository(创建模型仓)
- Launch Triton(启动Triton服务器与用户端)
- Send an Inference Request(提交推理要求)
- Production Documentation(生产文件):
这里最重要的是“server documents on GitHub”链接,点进去后会进入整个Triton项目中最完整的技术文件中心(如下图),除Installation与Getting Started属于入门范畴,其余User Guide、API Guide、Additional Resources与Customization Guide等四个部分,都是Triton推理服务器非常重要的技术内容。

因此这个部分可以算得上是学习Triton服务器的最重要资源。
例如点击“User Guide”之后,就会看到以下所条例的执行步骤:
- Creating a Model Repository [Overview || Details]
- Writing a Model Configuration [Overview || Details]
- Buillding a Model Pipeline [Overview]
- Managing Model Availablity [Overview || Details]
- Collecting Server Metrics [Overview || Details]
- Supporting Custom Ops/layers [Overview || Details]
- Using the Client API [Overview || Details]
- Analyzing Performance [Overview]
- Deploying on edge (Jetson) [Overview]
每个步骤都提供[Overview]与[Details]两种说明内容,能够更完整地掌握Triton推理服务器的创建步骤与调试重点,适合初学者的入门使用。
- Examples(范例):
这里的范例,比较重要的是指向https://github.com/NVIDIA/DeepLearningExamples链接,列出针对NVIDIA Tensor Core计算单元的深度学习模型列表,包括计算机视觉、NLP自然语言处理、推荐系统、语音转文字/文字转语音、图形神经网络、时间序列等各种神经网络模型细节,包括网络结构与相关参数的内容。
对于未来要在Triton服务器上,对于所使用的网络后端进行性能优化或者创建新的后端,会有很大的助益,但是对于初学者来说是相对艰涩的,因此现阶段先不做深入的说明与示范。
- Feedback(反馈):
这里会链接到https://github.com/triton-inference-server/server/issues问题中心,是Triton项目中最重要的技术问题解决资源之一,后面执行过程中所遇到的问题,都可以先到这里来查看是否有人已经提出?如果没有的话,也可以在这里提交自己所遇到的问题,项目负责人会提供合适的回复。
以上第2、4两项资源,对初学者来说会有最大的帮助。接着看一下项目里“钉住(Pinned)”的6个仓(如下图),是比较重要的基础部分,涵盖了Triton架构图中的主要板块。
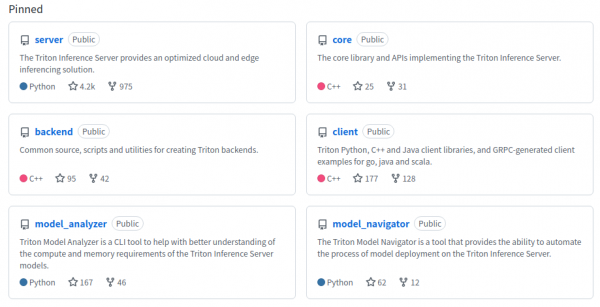
主要内容如下:
- server仓:
这里集成整个项目的主要内容,包括几部分:
- deploy(部署):提供在阿里巴巴、亚马逊等云资源的部署方式,以及基于NVIDIA Fleet指令集、GKE(Google kubernets Engine)、k8s、Helm等应用平台的各种部署方法;
- docker(容器):修正一些创建容器脚本的错误;
- docs(使用说明):就是前面“生产文件(Production Documentation)”的内容,这里不重复赘述;
- qa(质量优化):由于Triton推理服务器有非常多优化的环节,在这个目录下提供上百个不同状况的优化测试脚本;
- src(源代码):目录下存放整个Triton推理服务器的开源代码(.cc)、头文件(.h)与编译脚本(CMakeLists.txt);
- 其他代码与脚本
- core仓:
此存储库包含实现Triton核心功能的库的源代码和标头。核心库可以如下所述构建,并通过其C API直接使用。为了有用,核心库必须与一个或多个后端配对。您可以在后端回购中了解有关后端的更多信息。
- backend仓:
提供创建Triton服务器后端(backend)的源代码、脚本与工具。“后端”是用来执行不同深度学习模型的管理模块,以深度学习框架进行封装,例如PyTorch、Tensorflow、ONNX Runtime与TensorRT等等,用户也可以为了性能目的,自行定义C/C++封装方式。
- client仓
提供Triton用户端的C++/Python/Java开发接口、能生成适用于不同编程语言的GRPC开发接口的protoc编译器,以及对应的用户端范例;
- model_analyzer仓:
深度学习模型(model)是Triton推理服务器的最基础组成元件,因此对分析模型的计算与内存需求是服务器性能的一项关键功能。这个model_analyzer模型分析工具是一种CLI工具,这款新工具可以自动化地从数百种组合中为 AI 模型选择最佳配置,以实现最优性能,同时确保应用程序所需的服务质量,能帮助开发人员更好地了解不同配置中的权衡,并选择能够最大化Triton的性能配置;
- model_navigator仓:
这个model_navigator模型导航器是一种能够自动将模型从源移动到最佳格式和配置的工具,支持将模型从源导出为所有可能的格式,并应用Triton服务器的后端优化。使用模型分析器能找到最佳的模型配置,匹配提供的约束条件并优化性能。
以上是Trtiton开源项目里比较核心的6个仓,另外还有20多个代码仓,其中大约15个是项目提供的后端(backend)扩充应用,例如tensorrt_backend、fil_backend、square_backend等等,以及一些额外的管理工具,并且不断增加中。
本系列后面的内容都会基于这个server仓的docs目录下的内容为主,按部就班地带着读者循序渐进创建与调试Triton推理服务器的运作环境。【完】
来源:业界供稿
好文章,需要你的鼓励


谷歌免费存储空间调整:未绑定手机号仅享5GB
谷歌近期悄然调整账户存储政策:新注册用户若未绑定手机号,免费存储空间将从原来的15GB缩减至5GB。用户需验证手机号后,方可获得完整的15GB空间,用于Gmail、Drive和Photos的共享使用。谷歌表示,此举旨在确保存储空间"每人仅限一份",有效防止滥用。有分析认为,存储硬件成本上升也是推动此次政策调整的重要原因之一。

AI助手越权了?南加州大学等机构揭示大模型代理的“权限失控“问题
FORTIS是专门测量AI代理"越权行为"的基准测试,研究发现十款顶尖模型普遍选择远超任务需要的高权限技能,端到端成功率最高仅14.3%。

美国三大运营商携手卫星技术,向信号盲区宣战
AT&T、Verizon和T-Mobile宣布计划组建合资企业,利用卫星技术消除美国境内的网络覆盖盲区,重点服务农村及网络欠发达地区。该合资企业将整合知识产权与地面频谱资源,推动下一代直连设备(D2D)通信发展。目前三方尚未签署正式协议,现有运营商与卫星服务协议不受影响。此前,T-Mobile已与SpaceX合作推出星链卫星服务,美国联邦通信委员会也刚批准了价值400亿美元的EchoStar频谱出售案。

荷兰Nebius团队:给AI“起草员“瘦身,大模型推理速度最高提升5倍的秘密
荷兰Nebius团队提出SlimSpec,通过低秩分解压缩草稿模型LM-Head的内部表示而非裁剪词汇,在保留完整词汇表的同时将LM-Head计算时间压缩至原来的五分之一,端到端推理速度超越现有方法最高达9%。
2022
12/07
13:52
分享
点赞

美国三大运营商携手卫星技术,向信号盲区宣战
Flytrex无人机携手达美乐,可一次性送达两个大号披萨
欧洲最大3D打印公寓楼提前数月竣工
彼亚乔携手迪士尼推出Grogu主题自主跟随货运机器人
Okta将AI智能体安全管理扩展至Amazon Bedrock并向第三方身份提供商开放
苹果13英寸iPad Pro Magic键盘键盘亚马逊历史低价,直降25%
WhatsApp iOS版Liquid Glass界面设计正式向更多用户推送
OpenAI为ChatGPT Pro推出个人财务管理新功能
赛格威全新Xaber 300电动越野摩托车正式开售,最高时速达96公里
OpenAI再度重组高管架构,全力押注AI智能体战场
出门在外也能用!OpenAI 将 Codex 接入 ChatGPT 移动端
Google Gemini应用图标迎来细微配色调整
分析:NVIDIA第二季度财报再次超出预期背后的新问题
Jetson百万开发者故事 | 校企合作推动实现多项工业场景下AI边缘计算应用
Jetson百万开发者故事 | NVIDIA Jetson助力水产养殖企业打造自动化流水线
Jetson百万开发者故事 | 基于Jetson Nano的便携式岩石分类检测系统:地质学家的新利器
Jetson百万开发者故事 | 让AI成为铁路客运站自动扶梯安全管控的关键
Jetson百万开发者故事 | Jetson开发者突破百万,从TK1到Orin我都经历了啥
百万Jetson开发者故事
Jetson百万开发者故事 | NVIDIA Jetson如何成为可移动智能脑机交互平台
全新NVIDIA Jetson Orin NX 16GB大幅提升边缘AI性能
Triton推理服务器13-模型与调度器(3)
