
百万倍加速:加速计算重新定义药物研发
引言:NVIDIA将通过《NVIDIA 加速计算,百万倍加速行业应用》系列文章,为您详解NVIDIA如何通过数据中心规模的全栈加速计算,助力包括多个行业实现百万倍计算性能飞跃,高效解决人类挑战。
在日前举办的全球顶级超算大会SC22上,有着HPC领域诺贝尔奖之称的戈登贝尔奖揭晓,来自NVIDIA与芝加哥大学等机构的研究员凭借共同开发的一个处理基因组规模数据的先进模型,获得旨在表彰基于高性能计算的COVID-19研究的“戈登贝尔特别奖”。
身为加速计算先驱的NVIDIA何以在医疗方面取得如此瞩目的成就?凭借全球领先的AI计算平台和对多个行业的深耕打造的AI全栈解决方案,在过去的几年,NVIDIA对包括医疗健康在内的多个行业的AI应用带来了百万倍的加速。
过去十年,全球迎来一场AI革命,人工智能在各行各业引发了颠覆性的变革。在机器学习、深度学习、大规模语言模型等AI能力的加持下,药物研发等领域正迎来百万倍的效率飞跃。而这一切的背后,离不开加速计算。
加速计算引领行业新方向
半个多世纪前,尚在仙童半导体公司任职的戈登·摩尔预测,硅基芯片中的晶体管数量每18-24个月左右会实现翻番,性能因此获得成倍提升,成本则成倍下降。之后数十年间,这一预测成为推动半导体产业发展的准则。时至今日,硅基半导体接近尺寸维度的物理极限,继续研发先进制程工艺的成本不断递增,曾被奉为圭臬的摩尔定律正走向消亡。
另一方面,AI在加速计算的推动下飞速发展。据《经济学人》统计,仅仅从2012年到2018年,用于训练大型模型的计算能力就增长了30万倍,并且约每三个半月翻一番。
作为加速计算的主导者,NVIDIA 的GPU是掀起这场行业变革浪潮不可或缺的重要推力。AI应用的工作负载以重复密集型计算为主,而GPU擅长并行计算,可以让AI计算的速度获得几何倍数的提升。NVIDIA不断针对AI场景优化产品,让以GPU为核心的“全栈加速计算”成为AI计算不可或缺的一部分。加速计算与机器学习相结合,在全球包括药物研发在内的科学计算相关的多个行业掀起一场百万倍加速的革命,并超越摩尔定律成为半导体行业新的风向标。
三大驱动力助推百万性能飞跃
今年 GTC大会上,NVIDIA创始人兼CEO黄仁勋在主题演讲中指出,过去十年中,NVIDIA加速计算在 AI 领域中实现了百万倍的加速,并引发现代 AI 革命。未来十年,将力争在再实现百万倍的提速,以应对药物研发等人类面临的重大挑战。
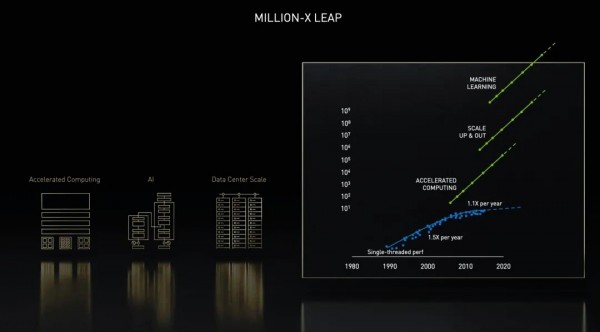
利用 AI 的大规模加速计算可实现指数级加速
过去的十年,在计算能力的构建,和对应用程序的计算性能的提升上,发生了跨越式发展。
首先,加速计算和异构计算已经成为业界共识,围绕着GPU芯片,NVIDIA建立了丰富的加速计算软件生态;第二,数据中心,因其具有强大的扩展能力,能够支撑起超大规模的计算任务,成为新的计算单元;第三,也是最具变革性的驱动力是 AI的广泛应用,将很多科学计算过程,用神经网络进行模拟代替,从而进一步简化计算,提高速度。
加速计算、数据中心大规模扩展,和 AI 的结合正在推动科学计算和工业计算的高速发展,实现百万倍的性能飞跃,从而解决 气候变化、药物研发、数字孪生,等等以往最具计算挑战的问题。
目前,NVIDIA已建立了一个从计算架构、硬件、算法和软件以及应用框架多角度协同,并且覆盖CPU 、GPU 、DPU三芯的全栈数据中心级加速计算平台,这种全栈式加速计算技术能力,使得NVIDIA成为全球“加速计算专家”。
NVIDIA 的 CUDA 库和 NVIDIA SDK 是加速计算的核心,伴随着每一个新的 SDK,新的科学领域、新的应用和行业都可以利用到 NVIDIA 强大的计算能力,这些 SDK 解决了计算、算法和科学交叉领域中极其复杂的问题,NVIDIA 的全栈方法产生的复合效应,实现了百万倍的加速。NVIDIA SDK 现已服务于医疗健康、能源、交通、零售、金融、媒体和娱乐等多个行业,并且每年都保持着高速的更新和扩展。通过在全栈和数据中心级实现加速,多个行业将在AI 的推动下受益并实现百万倍飞跃。
NVIDIA加速药物研发突破瓶颈
得益于NVIDIA数据中心级全栈加速计算能力和人工智能技术的进步,药物研发领域也将迎来效率升级。
研发时间一直是药物研发领域的一大痛点。一款新药从研发到上市,平均需要10年之久。对药企而言,缩短新药研发的时间就意味着更早获得回报;而对于一些身患重症甚至绝症的病人来说,新药更早问世,则意味着他们有更大的机会重获新生。
为助力药物研发领域加快速度,NVIDIA专门打造了一套名为NVIDIA Clara Discovery的AI加速计算软件平台。该解决方案集GPU加速及优化框架、工具、应用和预训练模型于一体,整合了人工智能、数据分析、模拟仿真和可视化能力,可支持化学信息学研究、蛋白质结构预测、候选药物虚拟筛选以及分子动力学模拟等药物开发过程中的跨学科工作流程。通过加速计算,研究人员可以一次模拟数以百万的分子,同时筛选出数百种潜在药物,从而降低成本、提高效率。
此外, NVIDIA 推出的基因测序分析加速软件 NVIDIA Clara Parabricks可以大幅提升基因组学分析的速度和准确性,大型语言模型(LLM)框架NVIDIA BioNeMo则可用于训练和部署超算规模的大型生物分子语言模型,帮助科学家更好地了解疾病,并为患者找到治疗方法。
全球医药企业研发效率实现指数级提升
在NVIDIA针对医疗行业的全栈加速计算平台的赋能下,来自全球的药物研发企业,正在跨越曾经的计算鸿沟,实现研发效率的指数级提升:
- AI制药公司Entos 在Clara Discovery的帮助下,利用自主开发的 OrbNet深度学习架构将蛋白质和候选药物之间的化学反应模拟速度提高1000 倍,从而在三个小时内就完成了原本需要超过三个月时间的工作量。
- 现已加入NVIDIA的初创公司 Parabricks在对序列基因组中的关键标志物和异常值检测时,使用 NVIDIA DGX 人工智能超级计算机将遗传信息分解成微小的单独碎片进行处理,成功把原先需要几天完成的工作缩短到半小时以内,效率提升超过50-80倍。
- 全球化学模拟软件开发领导者Schrödinger通过采用NVIDIA DGX系统提升计算药物研发平台的速度和准确性,实现对数十亿分子快速、准确的评估,加速新的治疗方法的开发。
- 生物技术公司 Recursion通过部署基于 NVIDIA DGX SuperPOD 参考架构的超级计算机BioHive-1 ,使其能够在一天内便能运行完成深度学习项目,而之前使用他们已有的集群完成该项目需要一周以上。
- 初创公司 Peptone 使用基于 NVIDIA DGX 系统、BlueField-2 DPU 和 NVIDIA InfiniBand 网络构建的 NVIDIA DGX SuperPOD 集群 - Cambridge-1超级计算机,能够在几个小时内,针对数百万种蛋白质并行地执行高吞吐量推理 ,并基于这些计算结果,研发针对特定 IDP 的专有创新药。
- 初创企业 PrecisionLife借助 NVIDIA GPU ,可以在短短几个小时内分析 10 万名患者的数据,这在以前是不可能实现的, 这使得其可以在大型患者群体中识别具有匹配疾病驱动因素、疾病进展和治疗反应的亚群,帮助研究人员选择正确的药物研发目标、为个人选择正确的治疗方式并为临床试验选择合适的患者。
- 以AI驱动的生物医药科技企业英矽智能在NVIDIA加速计算平台的帮助下,仅用时不到 18 个月,就实现了从靶点发现、分子生成和设计、体内体外疗效确认及安全性评估、到提名临床前候选化合物的早期药物发现过程,相比传统方法所需的四年半左右的耗时,节约了三分之二的时间,及花费成本也远低于传统的方式。
- “AI+冷冻电镜” 驱动的新型药物研发企业水木未来在使用冷冻电镜预处理图像时,借助NVIDIA GPU计算平台,样品筛选、样品质量监控和数据采集的效率提升高达10倍以上,大大降低了药物研发的成本。
- 新一代机器学习+生物技术初创企业燧坤智能借助NVIDIA GPU计算平台,使其开发的AI4D线上服务平台的计算效率和模型训练速度有超过10倍的提升,对靶点的定向分子进行生成与筛选、分子的类药性及成药性预测效率均有巨大帮助,大幅缩减了药物研发后期投入,提高了药物临床及上市成功率。
凭借数据中心级别的全栈能力,NVIDIA针对医疗健康领域也拥有丰富的的全栈加速计算方案,除了Clara Discovery,NVIDIA还有针对医疗设备、医学影像、基因组学和患者看护需求的Clara Holoscan、Clara Parabricks以及Clara Guardian等针对不同医疗应用场景的解决方案。
从传统医药巨头到初创企业,越来越多的全球医疗企业选择NVIDIA加速计算平台来提升AI生产力,降低研发成本。Million-X百万倍计算性能飞跃的愿景,已经在医疗健康以及更多关乎人类未来褔祉的领域落地生根。未来,只要人类探索科技,发现未知的脚步还在继续,加速计算的梦想就永远不会停息。
来源:业界供稿
好文章,需要你的鼓励


数据中心最新动态:2026年7月
全球数据中心建设需求持续高涨。北美方面,美国数据中心建设支出年化达510亿美元,微软在威斯康星州开放33亿美元设施,亚马逊和谷歌宣布在密苏里州合计投资250亿美元。欧洲方面,SoftBank将在法国建设5GW AI数据中心,投资额达750亿欧元。亚太地区,AirTrunk计划在印度投资210亿美元建设3GW数据中心。中东与非洲地区也有多项大规模项目落地。

当AI做“陪练老师“:弗吉尼亚理工大学等机构用大模型的“解题日记“预测考题难度
这项研究提出Epi2Diff方法,通过将大型推理模型的解题思考过程拆解为认知片段序列,提取过程特征预测考题对人类的难度,在四个真实考试数据集上超越了所有对比基线。

企业如何在边缘端与云端之间合理分配AI算力
随着企业将AI融入机器人、工业设备等物理基础设施,边云协同架构正成为关键课题。以Luminous Robotics和先正达为例:前者在太阳能农场部署的机器人每秒做出10次决策,数据定期上传云端持续优化模型;后者通过Cropwise平台整合卫星、无人机、拖拉机传感器数据,辅助农民完成约150项农业决策。两家公司均强调,边缘端负责实时响应,云端负责模型训练与更新,同时保持人工监督以确保安全与准确性。

南京大学联手阿里巴巴:让AI图像生成变得更“聪明“,一个让图像生成模型真正理解画面的新框架
南京大学与阿里巴巴提出MIMFlow,将掩码图像建模与标准化流端到端融合,让生成模型专注语义建模,以更少参数和更少令牌在ImageNet上取得FID 2.50的优异表现。
2022
12/07
10:00
分享
点赞

NVIDIA Blackwell 现已在云端全面可用
为“代理式AI”装上“护栏” NVIDIA打造“三重防线”
黄仁勋现身北京致辞:60年后,计算机正被重新定义
CES 2025 | NVIDIA Isaac GR00T Blueprint 让人形机器人“加速进化”
未来,就在我们手中
CES 2025 | 代理式AI崛起:NVIDIA定义下一代“代理式 AI Blueprint”
深度学习最佳 GPU,知多少?
NVIDIA推出用于多语言生成式人工智能的NeMo Retriever微服务
NVIDIA 初创加速计划 | 2024 NVIDIA 创业企业展示完美收官!
老黄掏出“迷你版AI超算”,每秒67万亿次运算,仅售2070元人民币
