
刷新纪录!浪潮AI获自动驾驶nuScenes竞赛目标检测第一名
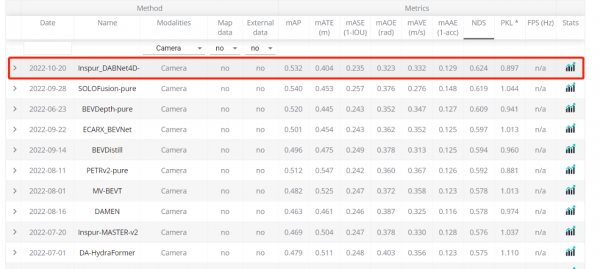
近日,在全球权威的自动驾驶nuScenes竞赛的最新一期评测中,浪潮信息AI团队斩获纯视觉3D目标检测任务(nuScenes Detection task)第一名,并将关键性指标nuScenes Detection Score(NDS)提高到62.4%
自动驾驶已被众多车企与AI 领先公司视为未来出行方式变革最重要的支撑性技术,而目标检测作为自动驾驶技术的核心模块,其算法的精度和稳定性正在众多AI研究团队的推动下,不断创下新高。nuScenes数据集是目前自动驾驶领域中最流行的公开数据集之一,数据采集自波士顿和新加坡的实际自动驾驶场景,是第一个集成摄像头、激光雷达和毫米波雷达等多种传感器,实现360度全传感器覆盖的数据集。nuScenes数据集提供了二维、三维物体标注、点云分割、高精地图等丰富的标注信息,包含1000个场景,拥有140万帧图像、39万帧激光雷达点云数据、23个物体类别、140万个三维标注框,其数据标注量比KITTI数据集高出7倍以上。
此次浪潮信息AI团队参与的纯视觉3D目标检测任务是竞争最激烈的赛道,吸引了百度、鉴智机器人、纵目科技、卡内基梅隆大学、加利福尼亚大学伯克利分校、MIT、清华大学、香港科技大学、上海交通大学等全球各地的顶尖AI团队。
 |
纯视觉3D目标检测任务,就是在不使用激光雷达、毫米波雷达等额外的传感器信息条件下,仅使用6个摄像头完成车外360度环视视野的3D目标检测,不仅需要检测周围环境中所有的车、行人、障碍物、交通标志、指示灯等若干类对象,还要精确感知到他们在真实物理世界中的位置、大小、方向、速度等信息。该项任务的主要难点是通过2D图像难以准确的获取目标的真实深度和速度,当提取的深度信息不准确时,一切的三维感知任务都会变得异常困难;而当提取的速度信息不准确时,则可能会对后续的决策规划任务产生致命性的影响。
浪潮信息AI团队创新开发了基于多相机的时空融合模型架构(Inspur_DABNet4D),在多视角视觉输入统一转换到BEV(Bird Eye View)特征空间这一技术框架的基础上,引入了数据样本增强、深度增强网络、时空融合网络、预训练权重等,得到了更鲁棒更精确的BEV特征,大幅地优化了目标物体监测速度和位移方向预测。
基于多相机的时空融合模型架构实现了四大核心技术突破。一是,更丰富的数据样本增强算法,将真值以真实的3D物理坐标实现拷贝贴图,并实现了时序中的扩展,显著的提高目标检测精度,可将mAP(全类平均正确率,mean Average Precision)平均提升2%+;二是,更强大的深度增强网络,主要针对现有方案深度信息难以学习和建模的问题,通过深度网络架构优化、点云数据监督指导训练、深度补全等技术,大幅提高深度预测精度;三是,更精细的时空融合网络,除了进一步优化驾驶场景中自车运动所带来的时空信息错位融合问题,还引入了sweep帧数据随机抽取与当前帧融合,并实现不同帧的数据样本同步增强操作,使得模型能够端到端学习到更精细的时序特征;四是,更完善的统一建模形式,即针对驾驶场景的视角广、尺度大、任务多的特点,设计了端到端的特征提取、融合、检测头的统一建模架构,结构简单、训练高效、场景通用。预训练模型可随时替换自监督模型,快捷便利地完成测试和精度提升。
得益于更先进算法和更高算力的进步,nuScenes竞赛的3D目标检测任务榜单成绩在2022年取得大幅提升,其中浪潮信息AI团队将关键性指标NDS提升到62.4%,而相比而言年初的榜单最佳成绩是47%。
来源:业界供稿
好文章,需要你的鼓励


Ode with Anthropic:押注AI服务成为企业级市场未来
Ode是由Anthropic、黑石、高盛等机构支持的合资企业,专注于向大型企业派驻前沿工程师,以少数工程师取代大批顾问。TechCrunch播客《Equity》采访了Ode联合创始人Chris Taylor和Eddie Siegel,探讨为何众多企业AI试点项目无法落地投产,以及AI原生服务为何有望成为科技领域最重要的赛道之一。

南加州大学团队揭示:AI抑郁症检测中藏着一个让准确率虚高23%的“致命漏洞“
南加州大学团队发现语音抑郁检测领域存在数据漏洞,并提出CLeaD跨语言对比对齐框架,揭示模型规模越大跨语言性能越差的反直觉规律。

用Gemini几分钟规划你的暑期旅行
本文介绍如何利用Gemini AI助手快速规划暑期旅行。ZDNET撰稿人Elyse Betters Picaro通过向Gemini输入详细提示词,成功生成迪士尼世界家庭旅行的初步行程文档,内容涵盖航班信息、Airbnb住宿建议及景点安排。测试表明,Gemini能自动创建Google文档并汇总关键信息,但在优先推荐谷歌自有平台方面存在一定偏向。ChatGPT也可完成类似任务,但不支持直接生成Google文档。

机械手臂终于学会“看深度“了——KAIST联合POSTECH研究团队让机器人规划与执行真正说同一种语言
KAIST等机构提出3D HAMSTER,通过为视觉语言模型加入深度编码器和几何重建损失,让机器人规划器直接输出三维轨迹,解决了分层机器人系统中规划与执行的维度不匹配问题,显著提升了操作鲁棒性。
2022
11/01
10:41
分享
点赞

Whatnot收购AI推荐公司Shaped,强化直播购物实时个性化能力
ELIZA:首个聊天机器人背后的多重人格与隐藏秘密
研究显示特斯拉LFP电池健康度表现优于镍基电池
苹果携手阿里云通义千问,Apple Intelligence获批在华上线
微软借助AI发现漏洞,单次发布破纪录的570个安全补丁
AI音乐生成器Suno遭入侵,疑从YouTube抓取训练数据
OpenAI首款品牌硬件亮相:RGB迷你键盘助力Codex智能体监控
PrivadoVPN 推出 MCP 服务器,让 AI 智能体直接管理你的 VPN 连接
Stripe与Advent据报出价约534亿美元联合收购PayPal
微软裁员背后的AI影响:你需要了解什么
Ode with Anthropic:押注AI服务成为企业级市场未来
用Gemini几分钟规划你的暑期旅行
