
Orin开发套件10-从头创建Jetson的容器(1)
使用Docker容器的最大好处就是“独立性强”,在前面文章中我们教大家如何使用NVIDIA在NGC提供创建好的l4t-ml系列镜像为基础,去创建各种机器学习/深度学习的开发或部署用途的独立容器,包括各种基于TensorRT的推理应用、基于Pytorch的各种YOLO相关应用等等。
但是l4t-ml容器内将大部分深度学习所需要的工具全部涵盖进去,使得这个容器镜像变得十分庞大,例如配合JetPack 5.0DP版本的nvcr.io/nvidia/l4t-ml:r34.1.1-py3镜像需要占用16.2G空间,这对大部分存储空间较为紧凑的Jetson边缘设备来说是个不小的负担,需要进一步的优化。
熟悉Docker创建容器的人都知道,只要使用“docker build -f DOCKERFILE”方式就能创建容器,不过Dockerfile内容是有复杂度的,至少包含以下两大部分:
- 基础镜像:
这是相对神奇的环节,我们至少得先在一个“以操作系统为基础”的基础镜像文件之上去创建新的容器,不过还好操作系统源头都会提供这些基础镜像,只要我们能找到这些基础镜像的发行位置,就能在Dockerfile一开始使用“FROM”指令进行导入。
在Jetson设备上使用的L4T(Linxun for Tegra)版本Ubuntu操作系统是由NVIDIA所维护,因此操作系统基础镜像也由NVIDIA所提供,并且存放在NGC云中心提供下载,可以在https://catalog.ngc.nvidia.com/orgs/nvidia/containers/l4t-base/tags上找到详细的内容与下载的指令。
l4t-base容器内只有最基础的操作系统、驱动与Python开发环境,并未安装CUDA、cuDNN或TensorRT等开发库,L4T版本与JetPack版本是对应的,请参考下表:

如果要使用l4t-base镜像为基础,去创建与深度学习相关应用的镜像文件,就需要自行在Dockerfile内加入CUDA/cuDNN/TensorRT以及其他所需要的依赖库与软件的安装步骤,以下整理出不同Jetpack版本所对应的CUDA/cuDNN/TensorRT/OpenCV的版本,提供读者在创建相关镜像时候可以参考:
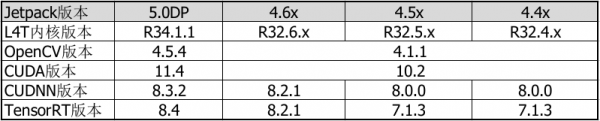
从上面简表可以看出,在JetPack 4.4至4.6版本的操作系统都是Ubuntu 18.04、CUDA版本都是10.2、Python3的版本都是3.6、OpenCV版本都是4.1.1,至于cuDNN与TensoRT则有些微的差异,基本上镜像文件的兼容性比较高。不过到了JetPack 5.0之后,操作系统升级至Ubuntu 20.04版之后,包括Python、OpenCV、CUDA版本的变化就比较大,与JetPack 4.x版本的镜像
基础容器的版本编号是对应L4T版本号,如下图:
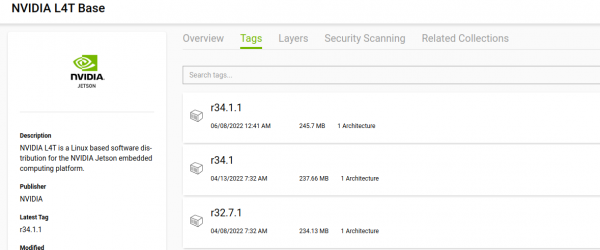
因此要创建Jetson容器的首要工作,就是先确认系统的L4T版本,然后再挑选合适的基础镜像来进行创建的任务。
- 添加所需软件的安装步骤与其他细节:
这部分就是将平常安装软件的正确步骤加入Dockerfile,使用“RUN”指令来执行所有安装内容,为了要让容器结构更加简化,通常会将所有需要的依赖库全部放在一个“RUN”指令里操作,因此创建者需要先收集并确认所需要的内容。
由于创建的容器会以root用户进行操作,因此过程都不需要用“sudo”去取得权限,可以直接使用apt-get、pip或dpkg等安装方式,有些需要预先下载的.deb、.whl或压缩文件,在使用过后最好删除以减少空间的占用。
这部分的细节内容相当繁琐,需要比较多的执行经验与整理过程,对初学者来说难度较大,因此本文特别挑选NVIDIA高级工程师所维护的jetson-container开源项目,针对在Jetson设备上创建深度学习与ROS两大类应用,提供各种对应的Dockerfile参考内容,包括安装CUDA、cuDNN、TensorRT、OpenCV、PyTorch、Tensorflow以及ROS相关环境的细节,读者可以参考这些内容再进行调整。
接下来就是下载jetson-container项目,并且以创建l4t-ml容为示范来进行讲解其操作的重点,读者只要比照相同的逻辑进行调整与修改,就能轻松地创建自己的应用与开发用途的容器镜像。
- 下载开源项目
项目开源仓位置在 https://github.com/dusty-nv/jetson-containers,请执行以下指令下载到Jetson设备上:
|
$ $ |
git clone https://github.com/dusty-nv/jetson-containers cd jetson-containers |
项目仓的内容总共有将近60个文件,主要分为以下三大类:
- 在主目录下有12个以“Dockerfile.xxx”格式命名的文件,作为创建各种容器所需要的配置文件;
- 在scripts目录下有16个创建容器与确认各项相关软件版本的.sh脚本文件;
- 在test目录下有21个测试用的Python代码。
接下来分析执行的重点。
- 分析创建容器的脚本
这个项目主要提供深度学习与ROS两大应用类别的容器创建资源,真正的使用入口就是scripts目录下的docker_build_ml.sh与docker_build_ros.sh这两个脚本,其余脚本多是辅助用途的,用来协助判断相关软件版本,然后甚至对应变量给执行脚本进行完整的镜像创建步骤。
现在以docker_build_ml.sh为例来进行说明,后面可以加上all、tensorflow或pytorch等机器学习框架选项,现在来看看脚本的主要内容:
- 确认基础镜像版本:
前面说过,创建Docker镜像的首要任务就是要确认L4T版本,然后指定NGC中合适的基础镜像版本,作为Dockerfile中第一个“FROM”的参数,在“docker build”过程中下载这个镜像。
- 脚本第4行“source scripts/docker_base.sh”会启动docker_base.sh脚本以确认需要下载的基础镜像版本;
- 而docker_base.sh第3行又呼叫l4t_version.sh脚本,获取本系统上的l4t版本,例如为r34.1.1,分别存入以下5个变量之中:
- $L4T_VERSION=34.1.1
- $L4T_RELEASE=34
- $L4T_REVISION=1.1
- $L4T_REVISION_MAJOR=1
- $L4T_REVISION_MINOR=1
然后传回给docker_bash.sh脚本使用;
- docker_base.sh根据上面变量决定基础镜像版本,存放到$BASE_IMAGE_L4T里,例如“nvcr.io/nvidia/l4t-base:r34.1.1”,这样就完成第一个最重要的工作!
- 确认OpenCV与Python版本:
脚本第6、7行分别执行opencv_version.sh与python_version.sh,去决定这两个部分的版本。
其中OpenCV部分经过作者修改之后固定为4.5.0版本,并以$OPENCV_DEB与$OPENCV_URL变量存放安装包的下载路径与名称。而Python版本则指定于所使用的Jetson设备上的版本,如果是JetPack 4.x版本的设备则Python版本为3.6,如果是Jetpack 5.0以后版本的设备则Python版本为3.8。
- 确认各容器相关应用版本:
这部分主要是PyTorch与Tensorflow的版本,因为这两个是目前深度学习领域使用率最高的框架,因此这里就以这两个工具为主来创建深度学习的容器镜像。
脚本第37~137行与160~221行的内容,会根据$L4T_RELEASE变量,分别针对创建PyTorch与TensorFlow镜像所需要的配套资源,提供完整的对应参数,包括需要赋予对应的下载链接、文件名称、镜像标签(tag)等等信息,在PyTorch部分还需要提供torchvision与torchaudio的版本。
下表是根据NGC提供的l4t-ml镜像所整理的各项版本信息:
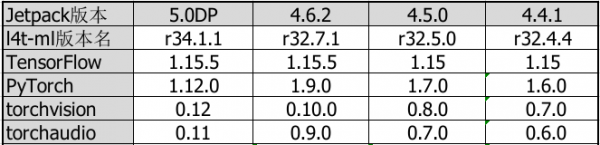
前面判断好相关版本信息之后,就会分别调用第14行build_pytorch()与第142行build_tensorflow()分别创建l4t-pytorch与l4t-tensorflow容器镜像。
下面截屏是build_pytorch()的主要内容,会调用scripts/docker_build.sh脚本与目录下的Dockerfile.pytorch配置文件,然后套用6个“--build-arg”参数进行实际创建的工作,这样就完成对l4t-pytorch镜像的创建任务。

创建l4t-tensorflow镜像的方式也是大致相同,就不重复说明。脚本最后第229~235行是创建包含PyTorch与Tensorflow两种框架的l4t-ml镜像,主要指令如下:
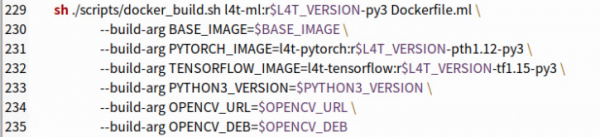
这样就完成在Jetson上从头创建深度学习相关的容器镜像任务,另一个创建ROS应用的docker_build_ros.sh脚本内容也是雷同,所有的关键就是先确认$L4T_RELEASE版本信息,其他的软件版本都会根据这个参数进行调整。
本文先讲解这个开源项目内的脚本内容,下一篇文章会进一步说明Dockerfile的主要细节,这样就能很轻松地掌握容器镜像的创建过程。
来源:业界供稿
好文章,需要你的鼓励


谷歌免费存储空间调整:未绑定手机号仅享5GB
谷歌近期悄然调整账户存储政策:新注册用户若未绑定手机号,免费存储空间将从原来的15GB缩减至5GB。用户需验证手机号后,方可获得完整的15GB空间,用于Gmail、Drive和Photos的共享使用。谷歌表示,此举旨在确保存储空间"每人仅限一份",有效防止滥用。有分析认为,存储硬件成本上升也是推动此次政策调整的重要原因之一。

AI助手越权了?南加州大学等机构揭示大模型代理的“权限失控“问题
FORTIS是专门测量AI代理"越权行为"的基准测试,研究发现十款顶尖模型普遍选择远超任务需要的高权限技能,端到端成功率最高仅14.3%。

美国三大运营商携手卫星技术,向信号盲区宣战
AT&T、Verizon和T-Mobile宣布计划组建合资企业,利用卫星技术消除美国境内的网络覆盖盲区,重点服务农村及网络欠发达地区。该合资企业将整合知识产权与地面频谱资源,推动下一代直连设备(D2D)通信发展。目前三方尚未签署正式协议,现有运营商与卫星服务协议不受影响。此前,T-Mobile已与SpaceX合作推出星链卫星服务,美国联邦通信委员会也刚批准了价值400亿美元的EchoStar频谱出售案。

荷兰Nebius团队:给AI“起草员“瘦身,大模型推理速度最高提升5倍的秘密
荷兰Nebius团队提出SlimSpec,通过低秩分解压缩草稿模型LM-Head的内部表示而非裁剪词汇,在保留完整词汇表的同时将LM-Head计算时间压缩至原来的五分之一,端到端推理速度超越现有方法最高达9%。
2022
09/22
11:30
分享
点赞

美国三大运营商携手卫星技术,向信号盲区宣战
Flytrex无人机携手达美乐,可一次性送达两个大号披萨
欧洲最大3D打印公寓楼提前数月竣工
彼亚乔携手迪士尼推出Grogu主题自主跟随货运机器人
Okta将AI智能体安全管理扩展至Amazon Bedrock并向第三方身份提供商开放
苹果13英寸iPad Pro Magic键盘键盘亚马逊历史低价,直降25%
WhatsApp iOS版Liquid Glass界面设计正式向更多用户推送
OpenAI为ChatGPT Pro推出个人财务管理新功能
赛格威全新Xaber 300电动越野摩托车正式开售,最高时速达96公里
OpenAI再度重组高管架构,全力押注AI智能体战场
出门在外也能用!OpenAI 将 Codex 接入 ChatGPT 移动端
Google Gemini应用图标迎来细微配色调整
分析:NVIDIA第二季度财报再次超出预期背后的新问题
Jetson百万开发者故事 | 校企合作推动实现多项工业场景下AI边缘计算应用
Jetson百万开发者故事 | NVIDIA Jetson助力水产养殖企业打造自动化流水线
Jetson百万开发者故事 | 基于Jetson Nano的便携式岩石分类检测系统:地质学家的新利器
Jetson百万开发者故事 | 让AI成为铁路客运站自动扶梯安全管控的关键
Jetson百万开发者故事 | Jetson开发者突破百万,从TK1到Orin我都经历了啥
百万Jetson开发者故事
Jetson百万开发者故事 | NVIDIA Jetson如何成为可移动智能脑机交互平台
全新NVIDIA Jetson Orin NX 16GB大幅提升边缘AI性能
Triton推理服务器13-模型与调度器(3)
