
Orin开发套件08-用DS容器执行Python范例
前面一篇文章已经带着大家将DeepStream容器配置Python使用环境,本文的重点就是继续执行实际的开发操作。
由于前面开启容器时,透过“-v”指令将容器外路径与容器内形成映射,因此实际代码文件是存放在主机上(容器外),我们可以在主机上使用gedit这个较为便利的编辑器去修改代码,然后在容器内执行应用,如此搭建起实用性更高的开发环境。
在DeepStream范例中的test2是识别功能最丰富的经典范例,不仅能识别对“Car”与“Person”配置唯一的编号进行跟踪功能,还能为“Car”物体进一步分析“厂牌”、“颜色”、“车型”等属性,我们还可以将这些信息改成中文显示。
另一个runtime_source_add_delete项目则是实现“动态添加/删减视频源”的功能,通常在面对“不均衡”监控的时候,会需要这项功能的辅助。
例如“医院的门诊与急诊”的流量在正常工作时间是门诊大于急诊,下班之后的流量就刚好反转,如果能根据时间去调整输入源的增减,就会有很高的实用性;都市中很多道路车流量在上下班高峰期是反转的,如果中控室的监控屏幕数量有限的时候,也可以根据不同状态去调整视频流的来源。
这并不意味着我们得去调整设备的数量,而是调整输入源的“接收开关”,例如道路交通的监控有100台摄像头,是保持24小时全年午休地拍摄并传输数据,而中控室如果只有50个显示屏幕,就只要切换接收输入源的开关就可以。
现在就用容器版DeepStream的Python环境,来执行这两个应用。
- DeepStream-test2项目
这个项目将DeepStream关于物体识别的绝大部分人工智能功能都集于一身,包括以下三大类组件
- 1个具备四类别的物体检测器(object detector)作为一阶段检测器;
- 1个跟踪器(tracker);
- 3个基于“Car”类别的图像分类器(image classifier)作为二阶段分类器。
三者的合作关系如下:
- 将读入的图像传给一阶段检测器进行物体检测计算;
- 将识别出的物体传送给跟踪器去赋予唯一的编号;
- 如果识别的类别为“Car”,则将物体位置坐标分别传送给3个二阶段分类器,对坐标内图形进行“厂牌”、“颜色”、“车型”等属性识别;
- 最后将上面的信息合成回原始图像,然后进行输出作业。
这里使用的检测器与3个二阶段分类器模型都在samples/models下,如以下的路径名:
- Primary_Detector:一阶段监测器
- Secondary_CarColor:识别车辆颜色的二阶段分类器
- Secondary_CarMake:识别车辆厂牌的二阶段分类器
- Secondary_VehicleTypes:识别车辆种类的二阶段分类器
如果前面建立的Python容器环境没有删除的话,现在就可以执行以下指令进入容器内去执行这个范例:
|
$ $ |
sudo xhost +si:localuser:root docker start ds_python && docker exec -it ds_python bash |
进入容器后,执行以下指令:
|
$ $ |
cd sources/deepstream_python_apps/apps/deepstream-test2 ./deepstream_test_2.py ../../../../samples/streams/sample_720p.h264 |
下图就是执行的效果,可以看到每个识别到的物体都有唯一的识别号,在“Car 3”后面还有“gray”与“nissan”等颜色与厂牌的信息。

不过这个容器版有个还未解决的问题,就是“中文显示”的部分,如果有更精通操作系统的朋友可以试着解决这个中文显示问题。
- runtime_source_add_delete项目
这个项目也是基于deepstream-test2多神经网络组合识别项目基础上,使用以下的动态处理函数,因此没有固定的通道结构:
- create_uridecode_bin:作为“多输入源路径解析”功能;
- stop_release_source:停止指定编号数据源,并释放相关资源的内存空间;
- delete_sources:首先删除现有stream中已经End of Stream的数据源,如果没有随机删除一个视频源。如果全部视频源都被删除时,就结束应用;
- add_sources:随机增加数据源,如果数量达到MAX_NUM_SOURCES,10s后删除一个视频源;
- bus_call:总线管理机制,作为触发事件的管理机制。
为了简化运行,这个示例只接收1个H.264视频文件当作4个输入源使用,每10秒添加的视频都会从头开始播放,系统就是为每个输入源设置唯一的编号,作为新增与删除的依据。
|
$ $ $ |
cd sources/deepstream_python_apps/apps/runtime_source_add_delete export DS_ROOT=/opt/nvidia/deepstream/deepstream/ ./deepstream_rt_src_add_del.py file://$DS_ROOT/samples/streams/sample_720p.mp4 |
接下去就会执行以下的7个画面变化:
- 显示第一个输入源的检测结果:
- 10秒后添加第二个输入源的检测结果:

- 再10秒后添加第三个输入源的检测结果:
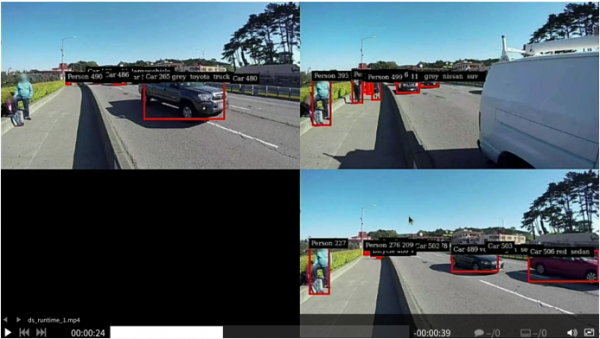
- 再10秒后添加第四个输入源的检测结果:

- 再10秒后随机删除一个输入源:

- 再10秒后又随机删除一个输入源:

- 再10秒后又随机删除一个输入源:

- 再10秒后删除最后一个输入源。
可以修改deepstream_rt_src_add_del.py文件的以下两个粗体下划线的参数,调整输出总数量与间隔时间:
- 第48行:MAX_NUM_SOURCES = 4
- 第278行:GLib.timeout_add_seconds(10, delete_sources, g_source_bin_list)
之后请自行尝试修改的结果。
来源:业界供稿
好文章,需要你的鼓励


谷歌免费存储空间调整:未绑定手机号仅享5GB
谷歌近期悄然调整账户存储政策:新注册用户若未绑定手机号,免费存储空间将从原来的15GB缩减至5GB。用户需验证手机号后,方可获得完整的15GB空间,用于Gmail、Drive和Photos的共享使用。谷歌表示,此举旨在确保存储空间"每人仅限一份",有效防止滥用。有分析认为,存储硬件成本上升也是推动此次政策调整的重要原因之一。

AI助手越权了?南加州大学等机构揭示大模型代理的“权限失控“问题
FORTIS是专门测量AI代理"越权行为"的基准测试,研究发现十款顶尖模型普遍选择远超任务需要的高权限技能,端到端成功率最高仅14.3%。

美国三大运营商携手卫星技术,向信号盲区宣战
AT&T、Verizon和T-Mobile宣布计划组建合资企业,利用卫星技术消除美国境内的网络覆盖盲区,重点服务农村及网络欠发达地区。该合资企业将整合知识产权与地面频谱资源,推动下一代直连设备(D2D)通信发展。目前三方尚未签署正式协议,现有运营商与卫星服务协议不受影响。此前,T-Mobile已与SpaceX合作推出星链卫星服务,美国联邦通信委员会也刚批准了价值400亿美元的EchoStar频谱出售案。

荷兰Nebius团队:给AI“起草员“瘦身,大模型推理速度最高提升5倍的秘密
荷兰Nebius团队提出SlimSpec,通过低秩分解压缩草稿模型LM-Head的内部表示而非裁剪词汇,在保留完整词汇表的同时将LM-Head计算时间压缩至原来的五分之一,端到端推理速度超越现有方法最高达9%。
2022
08/23
11:55
分享
点赞

美国三大运营商携手卫星技术,向信号盲区宣战
Flytrex无人机携手达美乐,可一次性送达两个大号披萨
欧洲最大3D打印公寓楼提前数月竣工
彼亚乔携手迪士尼推出Grogu主题自主跟随货运机器人
Okta将AI智能体安全管理扩展至Amazon Bedrock并向第三方身份提供商开放
苹果13英寸iPad Pro Magic键盘键盘亚马逊历史低价,直降25%
WhatsApp iOS版Liquid Glass界面设计正式向更多用户推送
OpenAI为ChatGPT Pro推出个人财务管理新功能
赛格威全新Xaber 300电动越野摩托车正式开售,最高时速达96公里
OpenAI再度重组高管架构,全力押注AI智能体战场
出门在外也能用!OpenAI 将 Codex 接入 ChatGPT 移动端
Google Gemini应用图标迎来细微配色调整
分析:NVIDIA第二季度财报再次超出预期背后的新问题
Jetson百万开发者故事 | 校企合作推动实现多项工业场景下AI边缘计算应用
Jetson百万开发者故事 | NVIDIA Jetson助力水产养殖企业打造自动化流水线
Jetson百万开发者故事 | 基于Jetson Nano的便携式岩石分类检测系统:地质学家的新利器
Jetson百万开发者故事 | 让AI成为铁路客运站自动扶梯安全管控的关键
Jetson百万开发者故事 | Jetson开发者突破百万,从TK1到Orin我都经历了啥
百万Jetson开发者故事
Jetson百万开发者故事 | NVIDIA Jetson如何成为可移动智能脑机交互平台
全新NVIDIA Jetson Orin NX 16GB大幅提升边缘AI性能
Triton推理服务器13-模型与调度器(3)
