
MLPerf最新发榜,浪潮AI服务器囊括数据中心推理全部冠军
2022年4月7日,全球权威AI基准评测MLPerf™公布最新AI推理(Inference)V2.0榜单,浪潮AI服务器以最高性能获得了数据中心(固定任务)的全部16项冠军。
MLPerf™由图灵奖得主大卫•帕特森(David Patterson)联合顶尖学术机构发起成立,是国际最权威的AI性能基准评测,每年组织AI推理和AI训练测试各两次,以对迅速增长的AI计算需求与性能进行及时的跟踪测评。MLPerf™比赛通常分为固定任务(Closed)和开放优化(Open)两类任务,开放优化能力着重考察参测厂商的AI技术创新力,固定任务则因更公平地考察参测厂商的硬件系统和软件优化的能力,成为更具参考价值的AI性能基准测试。
本次是2022年MLPerf™的首次AI推理性能评测,旨在考察在各类AI任务中,不同厂商计算系统的推理速度和能力。本次评测中,在竞争最激烈的数据中心(固定任务)赛道,共有926项成绩提交,数量较上次比试翻倍,竞争非常激烈。
浪潮AI服务器创推理性能新纪录
本次MLPerf™AI推理性能评测涵盖使用广泛的六大AI场景,包括图像分类、自然语言理解、语音识别、目标物体检测、医学影像分割、智能推荐,每个场景采用最主流的AI模型作为测试任务,分别为ResNet50、BERT、RNNT、SSD-ResNet34、3D-Unet、DLRM。MLPerf™测试要求模型推理精度达到99%以上,对于自然语言理解、医学影像分割和智能推荐3个任务则设置99%与99.9%两种精度要求,以考察当提升AI推理精度要求时对计算性能的影响。
为更加贴近实际应用情况,MLPerf™推理测试在数据中心赛道下设置了离线(Offline)与在线(Server)两种模式。离线模式代表任务所需所有数据都在本地可用,典型场景如大批量医疗影像样本存于本地等待统一识别。在线模式则反映了大部分的即时AI应用,其数据和请求以突发和间歇的方式在线送达,例如用户在浏览购物网站时智能推荐的推理请求。
浪潮AI服务器此次表现出色,以最高性能包揽了此次MLPerf™数据中心(固定任务)赛道的全部16项冠军。
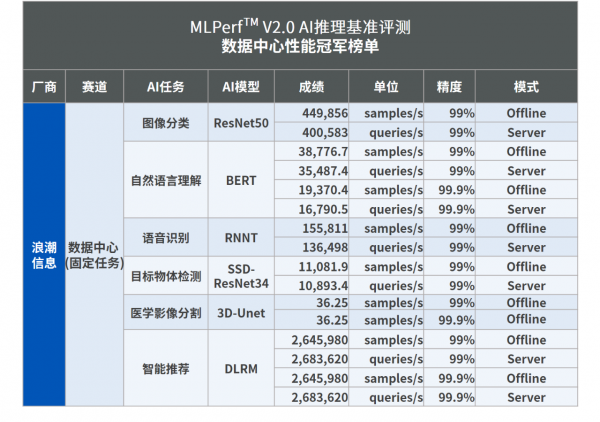
本次MLPerf™测试中,浪潮AI服务器在ResNet50模型任务中创造了每秒处理449,856张图片的性能纪录,相当于仅用2.8秒即完成ImageNet数据集128万张图片的分类;在3D-UNet模型任务中,创造了每秒处理36.25张医疗影像的新纪录,相当于在6秒内完成对KiTS19数据集207张3D医疗影像的分割;在SSD-ResNet34模型任务中,创造了每秒对11,081.9张图片完成目标物体识别及定位的新纪录;在BERT模型任务中,创造了平均每秒完成38,776.7个问答的性能纪录,在RNNT模型任务中,创造了每秒将155,811段语音转为文字的性能纪录,在DLRM模型任务中,则创造每秒实现2,645,980次点击预测的最佳性能纪录。
此外,本次MLPerf™评测还设有边缘推理赛道,浪潮面向边缘场景设计的AI服务器同样表现出色,在边缘固定任务赛道的全部17项任务中斩获了11项冠军。
随着AI应用在各个行业中的持续深化,更快的推理速度,将带来更高的AI应用效率与能力,加速产业智能化转型。相比半年前的MLPerf™AI推理榜单V1.1,浪潮AI服务器将图像分类、语音识别和自然语言理解任务的推理性能分别提升31.5%、28.5%及21.3%,意味着浪潮AI服务器在自动驾驶、语音会议、智能问答和智慧医疗等等场景中,能够更高效快速地完成各类智能任务。
全栈优化能力助推AI性能持续提升
浪潮AI服务器在MLPerf™基准评测中的出色表现,得益于浪潮信息卓越的AI系统设计能力和全栈优化能力。
本次参与测评的浪潮AI服务器NF5468M6J拥有出色的系统设计,以分层可扩展计算架构在业界率先实现对12颗NVIDIA A100 Tensor Core GPU的支持,并以极佳的性能成绩一举揽获12项冠军。浪潮信息也是本次MLPerf™竞赛中可以唯一提供服务器支持8颗500W NVIDIA A100 GPU的厂商,并实现了风冷及液冷两种散热方式。在此次参赛的8颗GPU NVLink高端主流机型中,浪潮AI服务器在数据中心16个任务中斩获14项最佳成绩,展现出在高端机型中的领先优势。其中,NF5488A5是全球首批上市的A100服务器,在4U空间支持8颗第三代NVlink互联的NVIDIA A100 GPU和2颗AMD Milan CPU。NF5688M6是面向大规模数据中心优化设计的具备极致扩展能力的AI服务器,支持8颗A100 GPU和2颗Intel Icelake CPU,支持多达13张PCIe Gen4的IO扩展卡。
在硬件层面,浪潮AI服务器通过对CPU、GPU硬件性能的精细校准和全面优化,使CPU性能、GPU性能、CPU与GPU之间的数据通路均处于对AI推理最优状态;在软件层面,结合GPU硬件拓扑对多GPU的轮询调度优化使单卡至多卡性能达到了近似线性扩展;在深度学习算法层面,结合GPU Tensor Core 单元的计算特征,通过自研通道压缩算法成功实现了模型的极致性能优化。
浪潮信息是全球领先的AI计算厂商,AI服务器市场份额全球第一,连续五年以超50%的市场份额稳居中国AI服务器市场第一。浪潮信息致力于AI计算平台、资源平台和算法平台的研发创新,并通过元脑生态携手领先伙伴加速数实相融。
来源:业界供稿
好文章,需要你的鼓励


星际之门AI数据中心建设雄心遭遇现实挑战
2025年1月,OpenAI、软银、甲骨文和MGX联合宣布"星际之门"计划,承诺投资5000亿美元,部署高达10GW算力基础设施。如今,该项目已从白宫发布会上的宏大承诺,演变为一场前所未有规模的基础设施建设实验。项目已扩展至德克萨斯、威斯康星、俄亥俄等多地,并延伸至阿布扎比和挪威。然而,融资争议、合作伙伴摩擦、能源压力及政策监管收紧,正考验着这一"AI工业园"模式能否真正落地。

阿里巴巴让AI图像生成模型“自我进化“:Qwen-Image-2.0-RL是如何让机器学会审美的?
阿里Qwen团队通过引入强化学习和在线策略蒸馏,将Qwen-Image-2.0升级为Qwen-Image-2.0-RL,让图像生成模型真正学会人类审美,文生图Elo评分提升78分,图像编辑提升93分。

OKX推出AI智能体招聘与支付市场平台
加密货币交易所OKX正式推出AI智能体交易市场OKX AI,允许AI代理相互雇佣、自主结算,并建立基于区块链的可携带信誉档案。该平台经过50家早期服务商封测后向开发者开放,依托稳定币和链上支付基础设施,支持全天候微支付。OKX创始人徐明星表示,传统金融基础设施为人类而建,智能体经济需要为自主软件专门设计的基础设施。

港科大联手快手,让AI画图“减减肥“:一个让图像生成更真实的小技巧
港科大与快手联合提出NormGuard,针对流匹配模型强化学习训练中速度范数膨胀问题,通过训练时单向惩罚约束,在保留奖励的同时改善图像真实感。
2022
04/08
16:39
分享
点赞

星际之门AI数据中心建设雄心遭遇现实挑战
OKX推出AI智能体招聘与支付市场平台
AI编程Token成本将与开发者薪资持平,企业如何应对?
机器学习项目全生命周期管理的成功实践
SVT Robotics的Softbot平台交易量突破40亿笔
Agibot第15000台人形机器人下线,具身AI量产加速
杜尔为大众汽车建设跨工厂集成CO?高效涂装车间
AI对就业的影响:大规模裁员背后的真相与数据
AI重复申请问题推动电网转向"承诺优先"规划
美国消费品安全委员会拟出台电动自行车电池安全新规
江波龙:建设完成mSSD月产能百万交付能力!mSSD高速存储介质赋能端侧AI规模应用
从IO500双榜第一,看国产存储的系统级突破
