
TAO系列04-启动器CLI指令集与配置文件
在开始使用TAO模型训练工具之前,我们必须先对其操作原理有个基础的理解,因为这套工具能支持30多种神经网络的深度学习,并且横跨视觉类与对话类两种不同领域,究竟是如何做到的?
前面介绍的内容中提过,在TAO工具使用两个不同的Docker容器,去面对视觉类与对话类的模型训练,分别是基于Tensorflow与PyTorch框架。
不过英伟达将复杂的调用工作进行高度的抽象化处理,以启动器CLI指令作为统一的执行接口,并且为每个神经网络提供对应的配置文件组,透过指令集与配置文件的组合,将操作的逻辑变得非常简单,开发人员只要熟悉这套指令集,就能非常轻松地驾驭所有TAO支持的神经网络,进行高效率的模型训练任务。
因此在操作TAO工具之前,首先得对CLI指令集与配置文件有个初步的了解。
- 启动器CLI指令集:
这个指令集的语法非常简单,主要是下面三部分所组成:
tao <task> <sub-task> <args>
- task:包括TAO所支持的神经网络算法以及基础的控制指令,主要分为以下三类:
- 视觉类神经网络:augment、bpnet、classification、dssd、emotionnet、efficientdet、fpenet、gazenet、gesturenet、heartratenet、lprnet、mask_rcnn、multitask_classification、retinanet、ssd、unet、yolo_v3、yolo_v4、yolo_v4_tiny、converter、detectnet_v2、faster_rcnn等
- 对话类神经网络:speech_to_text、speech_to_text_citrinet、text_classification、question_answering、token_classification、intent_slot_classification、punctuation_and_capitalization、spectro_gen、vocoder、action_recognition、n_gram等
- 控制指令类:包括list、stop、info三个功能指令,分别执行列出、终止处理启动器的进程,以及显示TAO的基础信息。
上面所有的信息,可以用tao info --verbose指令,查询到不容版本容器所支持的神经网络类型。
当我们单纯执行tao <task>的时候,就会进入对应的容器里,例如:
- tao ssd 会进入视觉类的容器,这里是tao-toolkit-tf:v3.21.11-tf1.15.5-py3
- tao n_gram 进入对话类容器,这里是tao-toolkit-lm:v3.21.08-py3
- sub-task与args:主要是指TAO所支持的神经网络算法(task)而不同,最简单的方法就是执行 tao <task> --help 去查询个别task后面所需要的<args>。例如:
- 执行tao ssd --help会显示以下信息:大部分视觉类的参数是类似
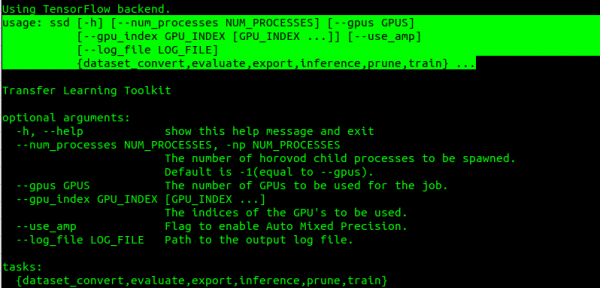
- 执行tao n_gram --help会显示以下信息:大部分对话类参数是类似

以下6种指令是所有模型都具备的功能:
- dataset_convert:将数据集转换成指定格式
- evaluate:模型评估
- export:导出模型
- inference:推理识别
- prune:修剪模型
- train:训练模型
到这里应该能够感受到这个CLI指令集的便利之处,开发人员只要好好记住这组指令,不需要撰写任何C++或Python代码,甚至不需要了解任何一个神经网络的结构与算法,就能非常轻松地面对这么多种复杂的模型训练任务。
- 视觉类神经网络配置文件:
这里需要透过TAO提供的范例来说明配置文件的细节,这里以视觉类的范例为主,请执行下列指令下载范例文件:
|
$ $
$ $ |
wget --content-disposition https://api.ngc.nvidia.com/v2/resources/nvidia/tao/cv_samples/versions/v1.3.0/zip -O cv_samples_v1.3.0.zip unzip -u cv_samples_v1.3.0.zip -d ./cv_samples_v1.3.0 rm -rf cv_samples_v1.3.0.zip && cd ./cv_samples_v1.3.0 |
在cv_samples_v1.3.0文件夹里有20+个子目录,每个子文件夹就对应一个神经网络,下面都有个别的specs子目录,里面就存放对应的配置文件。
每个项目应该是由不同的技术人员所处理,在文件格式与命名方式也不尽相同,大部分是.txt纯文件格式,有些则使用.yaml或.json格式,因此需要针对个别项目,去深入了解每个配置文件里的各项参数。
下面是TAO视觉类模型训练工具的工作流图,每个项目里的配置文件,都是为不同阶段的任务提供所需要的参数。
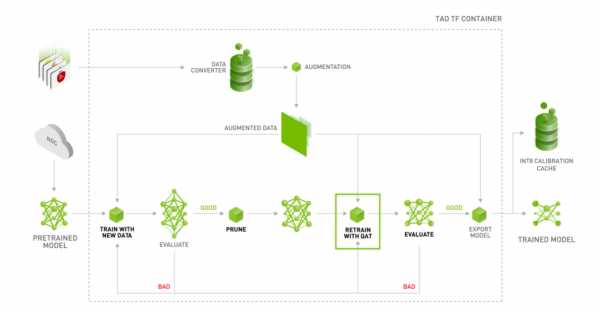
这里以英伟达发展的detectnet_v2神经网络作为范例,里面的配置文件内容比较完整,包括以下7个文件:
- detectnet_v2_tfrecords_kitti_trainval.txt
- detectnet_v2_train_resnet18_kitti.txt
- detectnet_v2_retrain_resnet18_kitti.txt
- detectnet_v2_retrain_resnet18_kitti_qat.txt
- detectnet_v2_inference_kitti_etlt_qat.txt
- detectnet_v2_inference_kitti_tlt.txt
- detectnet_v2_inference_kitti_etlt.txt
这些文件是配合整个执行流程的步骤:
- 格式转换:由于这个训练的容器是基于Tensorflow框架,因此执行训练前需要先将数据集转换成tf_record格式,就会用到detectnet_v2_tfrecords_kitti_trainval.txt配置文件。其他项目里xxx_tfrecords_kitti_xxx.txt主要就是作为这个用途。
- 训练模型:所有项目里的xxx_train_xxx.txt文件,都是该项目进行第一次训练时所需要配置文件,不过每个项目的配置中都不尽相同,以下列出4个项目提供参考:
这里的参数设定,是整个TAO训练模型过程中技术含量最高的环节,我们所能修改的部分大概就是“training_config”组里的”batch_size_per_gpu”与“num_epochs”这两个参数,以及确认“dataset_config”组里的每一个“target_class_mapping”对应是否正确。
其他参数的调整是需要对个别神经网络的结构预与算法有足够了解,如果没有把握的话,建议就使用英伟达已经优化过的参数。
- 评估模型:也使用前面一个配置文件。如果不满意评估结果(例如mAP低于0.5),可以试着加大num_epochs,或者从头检查数据集的图像与标注;如果满意结果的话,就可以继续往下执行。
- 修剪模型:TAO使用比较简单的调整阈值(threshold),而不改变其他参数
- 模型再训练:这个步骤用到的xxx_retrain_xxx.txt配置文件,与第一次训练使用的配置文件中的最大不同点,在于“pretrained_model_file”的部分,第一次训练使用NGC下载的预训练模型,而再训练的部分是使用步骤4修剪步骤所生成的模型,其他设定值是一样的。
- 评估再训练的模型:与步骤3相同。如果对评估结果并不满意,请回到步骤4重复进行;如果感到满意,就能接续往下执行推理识别,验证模型的效果。
后面的推理验证与导出模型的步骤,留在实际项目执行的时候再做说明。到此应该能清楚,在TAO模型训练阶段,需要的就是xxx_tfrecords_xxx.txt、xxx_train_xxx.txt与xxx_retrain_xxx.txt这三个配置文件,后面两个文件的内容几乎一样,只有调用的预训练模型不一样,这样就能让事情变得更加单纯。
整个TAO训练工具的内容,主要就是围绕着CLI指令集与配置文件的组合处理,如此一来,开发人员只要掌握这两个部分,就能轻松驾驭大部分的模型训练任务【完】
来源:业界供稿
好文章,需要你的鼓励


谷歌免费存储空间调整:未绑定手机号仅享5GB
谷歌近期悄然调整账户存储政策:新注册用户若未绑定手机号,免费存储空间将从原来的15GB缩减至5GB。用户需验证手机号后,方可获得完整的15GB空间,用于Gmail、Drive和Photos的共享使用。谷歌表示,此举旨在确保存储空间"每人仅限一份",有效防止滥用。有分析认为,存储硬件成本上升也是推动此次政策调整的重要原因之一。

AI助手越权了?南加州大学等机构揭示大模型代理的“权限失控“问题
FORTIS是专门测量AI代理"越权行为"的基准测试,研究发现十款顶尖模型普遍选择远超任务需要的高权限技能,端到端成功率最高仅14.3%。

美国三大运营商携手卫星技术,向信号盲区宣战
AT&T、Verizon和T-Mobile宣布计划组建合资企业,利用卫星技术消除美国境内的网络覆盖盲区,重点服务农村及网络欠发达地区。该合资企业将整合知识产权与地面频谱资源,推动下一代直连设备(D2D)通信发展。目前三方尚未签署正式协议,现有运营商与卫星服务协议不受影响。此前,T-Mobile已与SpaceX合作推出星链卫星服务,美国联邦通信委员会也刚批准了价值400亿美元的EchoStar频谱出售案。

荷兰Nebius团队:给AI“起草员“瘦身,大模型推理速度最高提升5倍的秘密
荷兰Nebius团队提出SlimSpec,通过低秩分解压缩草稿模型LM-Head的内部表示而非裁剪词汇,在保留完整词汇表的同时将LM-Head计算时间压缩至原来的五分之一,端到端推理速度超越现有方法最高达9%。
2022
03/28
13:30
分享
点赞

美国三大运营商携手卫星技术,向信号盲区宣战
Flytrex无人机携手达美乐,可一次性送达两个大号披萨
欧洲最大3D打印公寓楼提前数月竣工
彼亚乔携手迪士尼推出Grogu主题自主跟随货运机器人
Okta将AI智能体安全管理扩展至Amazon Bedrock并向第三方身份提供商开放
苹果13英寸iPad Pro Magic键盘键盘亚马逊历史低价,直降25%
WhatsApp iOS版Liquid Glass界面设计正式向更多用户推送
OpenAI为ChatGPT Pro推出个人财务管理新功能
赛格威全新Xaber 300电动越野摩托车正式开售,最高时速达96公里
OpenAI再度重组高管架构,全力押注AI智能体战场
出门在外也能用!OpenAI 将 Codex 接入 ChatGPT 移动端
Google Gemini应用图标迎来细微配色调整
分析:NVIDIA第二季度财报再次超出预期背后的新问题
Jetson百万开发者故事 | 校企合作推动实现多项工业场景下AI边缘计算应用
Jetson百万开发者故事 | NVIDIA Jetson助力水产养殖企业打造自动化流水线
Jetson百万开发者故事 | 基于Jetson Nano的便携式岩石分类检测系统:地质学家的新利器
Jetson百万开发者故事 | 让AI成为铁路客运站自动扶梯安全管控的关键
Jetson百万开发者故事 | Jetson开发者突破百万,从TK1到Orin我都经历了啥
百万Jetson开发者故事
Jetson百万开发者故事 | NVIDIA Jetson如何成为可移动智能脑机交互平台
全新NVIDIA Jetson Orin NX 16GB大幅提升边缘AI性能
Triton推理服务器13-模型与调度器(3)
