
NVIDIA Jetson Nano 2GB 系列文章(35):Python版test1实战说明
上一篇文章已经带着大家安装DeepStream的Python开发环境,并且执行最简单的deepstream-test1.py,让大家体验一下这个范例的效果。本文则进一步以这个Python代码讲解DeepStream插件工作流,并且扩充USB摄像头作为输入,以及将输出透过RTSP转发到其他电脑上观看。
如果还未安装Python环境或下载Python范例的,请至前一篇文章中找安装与下载的步骤,这里不再重复。
前面文章中已经简单提过DeepStream所用到的插件内容,但那只是整个框架中非常基础的一小部分,本文要用代码开始解说范例的时候,还是得将Gstreamer一些重要构成元素之间的关系说明清楚,这样才能让大家在代码过程得以一目了然。
现在先把这个test1范例的执行流程先讲解清楚,这样在阅读后面的代码就会更加容易掌握上下之间的交互关系。这里的流程对C/C++版本与Python版本是完全一样的,只不过代码不过用Python来说明:
- 首先filesrc数据源元件负责从磁盘上读取视频数据
- h264parse解析器元件负责对数据进行解析
- nvv4l2decoder编码器元件负责对数据进行解码
- nvstreammux流多路复用器元件负责批处理帧以实现最佳推理性能
- nvinfer推理元件负责实现加速推理
- nvvideoconvert转换器元件负责将数据格式转换为输出显示支持的格式
- nvdsosd可视化元件负责将边框与文本等信息绘制到图像中
- nvegltransform渲染元件和nveglglessink接收器元件负责输出到屏幕上。
建立DeepStream应用程式的步骤与Gstreamer几乎一样,都是有固定的步骤,只要熟悉之后就会发现其实并没有什么难度,接下去就开始我们的执行步骤。
- 创建DeepStream应用的7大步骤:
- 初始化Gstreamer与创建管道(pipeline)
|
# 从“def main(args):”开始 GObject.threads_init() # 标准GStreamer初始化 Gst.init(None) # 创建Gst物件与初始化 pipeline = Gst.Pipeline() # 创建与其他元素相连接的管道元素 |
- 创建所有需要的元件(element):用Gst.ElementFactory.make() 创建所需要的元素,每个元素内指定插件类别(粗体部分)并给定名称(自行设定):
|
# 阶段1-处理输入源的插件: # 建立“源”元素负责从文件读入数据 source = Gst.ElementFactory.make("filesrc", "file-source") # 解析文件是否为要求的h264格式 h264parser = Gst.ElementFactory.make("h264parse", "h264-parser") # 调用NVIDIA的nvdec_h264硬件解码器 decoder = Gst.ElementFactory.make("nvv4l2decoder", "nvv4l2-decoder") # 创建nvstreammux实例,将单个或多个源数据,复用成一个“批(batch)” streammux = Gst.ElementFactory.make("nvstreammux", "Stream-muxer")
# 阶段2-执行推理的插件: # 使用NVINFERE对解码器的输出执行推理,推理行为是通过配置文件设置 pgie = Gst.ElementFactory.make("nvinfer", "primary-inference")
# 阶段3-处理输出的插件: # 根据nvosd的要求,使用转换器将NV12转换为RGBA nvvidconv = Gst.ElementFactory.make("nvvideoconvert", "convertor") # 创建OSD以在转换的RGBA缓冲区上绘制 nvosd = Gst.ElementFactory.make("nvdsosd", "onscreendisplay") # 最后将osd的绘制,进行渲染后在屏幕上显示结果 transform=Gst.ElementFactory.make("nvegltransform", "egltransform") sink = Gst.ElementFactory.make("nveglglessink", "nvvideo-renderer") |
- 配置元件的参数:
|
# 以args[1]给定的文件名为输入源视频文件 source.set_property('location', args[1]) # 设定流复用器的尺寸、数量 streammux.set_property('width', 1920) streammux.set_property('height', 1080) streammux.set_property('batch-size', 1) streammux.set_property('batched-push-timeout', 4000000) # 设定pgie的配置文件 pgie.set_property('config-file-path', "dstest1_pgie_config.txt") |
- 将元件添加到导管之中:用pipeline.add()
|
pipeline.add(source) pipeline.add(h264parser) pipeline.add(decoder) pipeline.add(streammux) pipeline.add(pgie) pipeline.add(nvvidconv) pipeline.add(nvosd) pipeline.add(sink) if is_aarch64(): pipeline.add(transform) |
- 将元件按照要求连接起来:本范例的管道流为file-source -> h264-parser -> nvh264-decoder -> streammux -> nvinfer -> nvvidconv -> nvosd -> video-renderer
|
source.link(h264parser) # file-source -> h264-parser h264parser.link(decoder) # h264-parser -> nvh264-decoder # 下面粗线的三行,是streammux的特殊处理方式 sinkpad = streammux.get_request_pad("sink_0") srcpad = decoder.get_static_pad("src") srcpad.link(sinkpad) streammux.link(pgie) # streammux -> nvinfer pgie.link(nvvidconv) # nvinfer -> nvvidconv nvvidconv.link(nvosd) # nvvidconv -> nvosd nvosd.link(transform) # nvosd -> transform transform.link(sink) # transform -> video-renderer |
前面5个步骤都是比较静态的固定步骤,只要将想开发的应用所需要的插件元件进行“创建”、“给值”、“连接”就可以。
接下去的部分是整个应用中非常关键的灵魂,就是我们得为整个应用去建构“信息(message)传递系统”,这样才能让这个应用与插件元件之间形成互动,进而正确执行我们想要得到的结果。其相互关系图如下,这里并不花时间去讲解调用细节,想了解的请自行参考Gstreamer框架的详细使用。
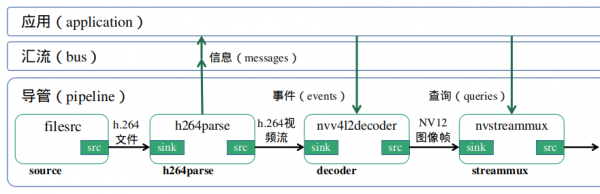
- 创建一个事件循环(evnet loop):将信息(mesages)传入并监控bus的信号
|
loop = GObject.MainLoop() bus = pipeline.get_bus() bus.add_signal_watch() bus.connect ("message", bus_call, loop) # 用osdsinkpad来确认nvosd插件是否获得输入 osdsinkpad = nvosd.get_static_pad("sink") # 添加探针(probe)以获得生成的元数据的通知,我们将probe添加到osd元素的接收器板中,因为到那时,缓冲区将具有已经得到了所有的元数据。 osdsinkpad.add_probe(Gst.PadProbeType.BUFFER, \ osd_sink_pad_buffer_probe, 0) |
注意粗体“osd_sink_pad_buffer_probe”部分,这是代码中另一个重点,需要自行撰写代码去执行的部分,就是代码中第41~126行的内容,这里面的处理以“帧”为单位(在“while l_frame is not None:”里面),将该帧所检测到的物件种类进行加总,并且将物件根据种类的颜色画出框框。
事实上在这80+行代码中,真正与数据处理相关的部分,只有20行左右的内容,注释的部分占用不小的篇幅,这是作者为大家提供非常重要的说明,只要耐心地去阅读,就能轻松地掌握里面的要领。
- 播放并收听事件:这部分就是个“启动器”,如同汽车钥匙“执行发动”功能一样。
|
# 配置导管状态为PLAYING就可以 pipeline.set_state(Gst.State.PLAYING) try: loop.run() # 执行前面创建的事件循环 except: pass # 执行结束之后,需要清除导管,将状态为NULL就可以 pipeline.set_state(Gst.State.NULL) |
以上就是建立DeepStream应用的标准步骤,可以将“def main(args):”部分的代码当作是个模板去加以利用。
至于“osd_sink_pad_buffer_probe”函数的作用,就是从osd接收器提取接收的元数据,并更新绘图矩形、对象信息等的参数,里面的代码也都是标准内容,可以在别的应用在重复套用。更多参数优化的细节部分,须花时间详细阅读DeepStream开发手册。
接下来就实际执行一下Python版本的deepstream-test1代码,看看效果如何!
- 执行deepstream_test_1.py
前面文章中已经将NVIDIA/AI-IOT/deepstream-python-apps项目下载到Jetson Nano 2GB上的<DeepStream根目录>/sources下面,现在就到这个目录下去执行
|
cd <DeepStream根目录>/sources/deepstream_python_apps/apps cd deepstream-test1 |
下面有执行文件deepstream_test_1.py、配置文件dstest1_pgie_config.txt与说明文件README,这个配置文件就是步骤3最后“pgie.set_property”里面指定的文件,在执行文件里看不到任何与推理模型相关的内容,原来都放在设定文件里面去指定了。
关于设定文件的参数设定部分,是相对容易了解的,这里不多花时间说明,接下去直接执行以下指令看看执行结果:
|
python3 deepstream_test_1.py ../../../../samples/streams/sample_720p.h264 |
就能跑出我们熟悉的结果,
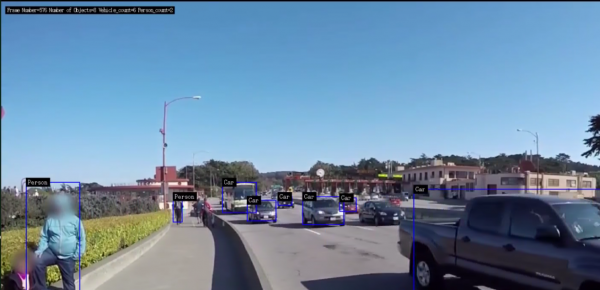
如果觉得左上方显示的字体太小,请自行改动代码第110行的字体号数。下图是字体放大到20号时候的显示结果,现在就可以看到很清楚了。

到这里,相信您应该对DeepStream代码有更深层次的了解,在了解整个框架与工作流程之后,可以发现要开发一个基础应用,并不是一件太困难的事情,不过建议您多反复阅读代码内的每一行说明,并且自行适度修改些参数看看效果会有什么变化,一旦熟悉这些逻辑与交互关系之后,就会觉得DeepStream其实很简单。《完》
来源:业界供稿
好文章,需要你的鼓励



明尼苏达大学最新研究颠覆认知:训练AI大模型,只需动其中一层就够了?
这项来自明尼苏达大学等机构的研究发现,大语言模型在强化学习后训练中,只需训练中间少数几层即可匹配甚至超越全参数训练效果,且这一规律跨模型、跨任务高度稳定,为更高效的AI训练策略提供了新思路。


台湾大学与NVIDIA揭秘:你的声音正在悄悄改变AI对你的判断
本文介绍VIBE框架,一套通过开放式任务评估大型音频语言模型声音诱发偏见的系统,测试12个模型后发现每个模型均存在显著性别或口音偏见。
2021
09/30
15:35
分享
点赞

机器人管家系统上线!傅利叶携多款康养陪伴新品方案亮相WAIC 2026
赛那德“ 自主作业机器人天团” 登陆 WAIC:iLoabot-X+模型双升级,秀出具身场景落地硬实力
西门子Eigen工程智能体中国首发首展,荣获2026 WAIC SAIL之星奖
NVIDIA Cosmos 推动物理 AI 前沿发展
PPIO亮相WAIC 2026:发布智能模型网关,打造面向Agent时代的智能Token工厂
端侧感知、私有闭环、量子协同, NVIDIA全栈异构计算范式“接管”实体产业底座
边缘智算筑基、全栈软硬协同,研华科技将AI带进产业闭环
千问AI眼镜将升级为智能体眼镜:能灵活调用Skill和Agent,能全天候感知
对话Moonix郭于晨:先让用户戴上“眼镜”,再让“AI”记录世界
亮相WAIC 2026,临床实证赋能康养升级 无芯科技定义AI疗愈新范式
生态覆盖持续扩散,一文看懂各行业企业鸿蒙化转型进度
WAIC亮出集群协作真功夫,优艾智合领跑工业具身智能规模化
NVIDIA Blackwell 现已在云端全面可用
为“代理式AI”装上“护栏” NVIDIA打造“三重防线”
黄仁勋现身北京致辞:60年后,计算机正被重新定义
CES 2025 | NVIDIA Isaac GR00T Blueprint 让人形机器人“加速进化”
未来,就在我们手中
CES 2025 | 代理式AI崛起:NVIDIA定义下一代“代理式 AI Blueprint”
深度学习最佳 GPU,知多少?
NVIDIA推出用于多语言生成式人工智能的NeMo Retriever微服务
NVIDIA 初创加速计划 | 2024 NVIDIA 创业企业展示完美收官!
老黄掏出“迷你版AI超算”,每秒67万亿次运算,仅售2070元人民币
