
基于Omniverse的NVIDIA Isaac Sim现已发布公测版
全新Isaac模拟引擎不但能够创造更逼真的环境,而且还能简化合成数据生成和域随机化,从而建立真值数据集来训练用于物流、仓库、未来工厂等的各种机器人。

Omniverse是NVIDIA模拟器的根本基础,包括加入了多项新功能的Isaac平台。NVIDIA Isaac Sim目前已发布公测版,您可以通过该平台探索更高级的机器人模拟功能。
Isaac Sim基于NVIDIA Omniverse平台而构建,它是一个机器人模拟应用与合成数据生成工具。机器人专家可使用它更高效地训练和测试机器人,模拟机器人与指定环境的真实互动,而且这些环境可以超越现实世界。
Isaac Sim的发布还增加了经过改进的多摄像头支持功能、传感器功能以及一个PTC OnShape CAD导入器,让3D素材的导入变得更加轻松。从实体机器人的设计和开发、机器人的训练,到在“数字孪生”中的部署(数字孪生是一种精确、逼真的机器人模拟和测试虚拟环境),这些新功能将全方位地扩大可以建模和部署的机器人和环境范围。
主要新功能
- 支持多摄像头
- 带合成数据的鱼眼相机
- 支持ROS2
- PTC OnShape导入器
- 经过改进的传感器支持
- 超声波传感器
- 力传感器
- 自定义激光雷达模式
- 可从NVIDIA Omniverse Launcher中下载
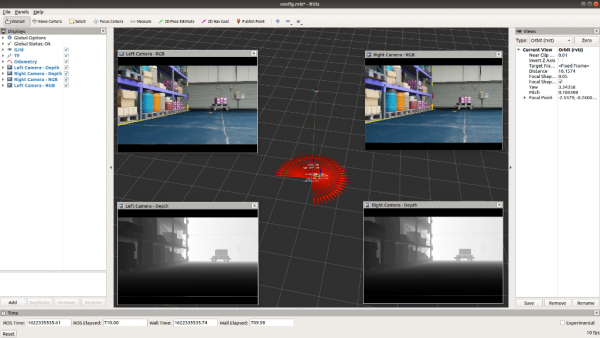
Isaac Sim可以将多摄像头传感器数据发送到Rviz(ROS可视化工具)
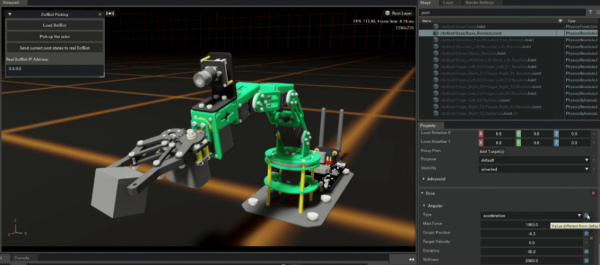
在Isaac Sim中控制Dofbot操作机器人
Isaac Sim实现了更多的机器人模拟
开发者早已明白强大的模拟环境对机器人测试和训练的益处,但此类模拟器往往存在着限制其使用的缺点。Isaac Sim通过以下优势来弥补这些缺点。
逼真的模拟
为了提供逼真的机器人模拟,Isaac Sim运用了Omniverse平台的强大技术:使用PhysX 5进行高级GPU物理模拟、借助实时光线追踪和路径追踪实现高逼真度,以及支持物理渲染的材质定义语言(Material Definition Language ,MDL)。
模块化设计与丰富的应用
Isaac Sim专为解决许多最常见的机器人用例而创建,包括操控、自主导航和用于训练数据的合成数据生成。其模块化设计能够让用户轻松自定义和扩展工具集,以适应多种应用和环境。
无缝连接和互操作性
借助NVIDIA Omniverse,Isaac Sim可以使用Omniverse Nucleus和Omniverse Connectors在通用场景描述(USD)中合作构建、分享、导入环境模型与机器人模型。通过ROS/ROS2接口或功能齐全的Python脚本,以及用于导入机器人模型和环境模型的插件,可以轻松地让机器人的大脑与虚拟世界相连。
Isaac Sim的合成数据生成助力实现机器学习
合成数据生成是一个重要的工具,它正在被越来越多地用于训练当今机器人的感知模型。获取真实世界的、正确标记的数据是一项耗时且成本高昂的工作。 但就机器人技术而言,在现实世界中收集某些所需的训练数据可能太困难或太危险。 对于必须靠近人类工作的机器人来说尤其如此。
Isaac Sim 内置了对训练感知模型很重要的各种传感器类型的支持。这些传感器包括 RGB、深度、边界框和分割。

玻璃物体的真值合成数据
在公测版中,我们能够输出KITTI格式的合成数据。这些数据可以直接用于NVIDIA迁移学习工具包,以使用特定用例数据提高模型性能。
域随机化
域随机化能够对定义模拟场景的参数进行更改,如场景中的照明、颜色和材质纹理等。域随机化的主要目标之一,便是通过将神经网络暴露在所模拟的各种域参数中,来加强机器学习(machine learning ,ML)模型的训练。这有助于模型在真实世界场景中实现有效的泛化。实际上,这项技术能够教会模型忽略不重要的内容。
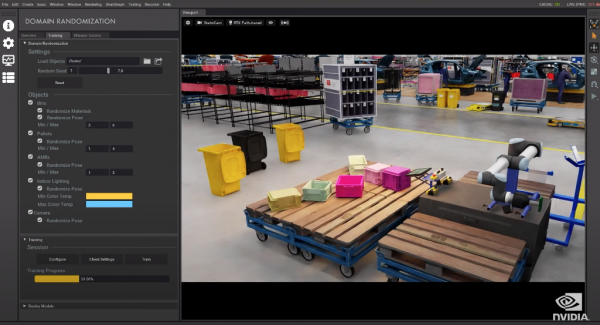
工厂场景的域随机化
Isaac Sim能够对定义一个特定场景的多个不同属性进行随机化。借助这些功能,机器学习工程师可以确保合成数据集包含足够的多样性来驱动稳健的模型性能。
可随机化的参数
|
颜色 |
动作 |
|
规模 |
亮度 |
|
纹理 |
材质 |
|
网格 |
可视性 |
|
旋转 |
|
在Isaac Sim公测版中,我们通过允许用户定义随机化区域来增强域随机化功能。开发人员现在可以在场景中要随机化的区域周围绘制一个框,场景的其余部分将保持静态。
更多关于Isaac Sim的信息
观看2021年GTC大会上的最新Isaac Sim 分会:从模拟到现实。https://www.nvidia.com/en-us/on-demand/session/gtcspring21-s31824/
可通过以下教程进一步了解如何导入您自己的机器人。
https://www.youtube.com/watch?v=pxPFr58gHmQ
阅读开发者博客,进一步了解如何使用Isaac Sim来训练Jetbot:
- https://developer.nvidia.com/blog/training-your-jetbot-in-isaac-sim/
- https://developer.nvidia.com/blog/training-your-nvidia-jetbot-to-avoid-collisions-using-nvidia-isaac-sim/
即刻下载
现已有成千上万的开发者采用Isaac Sim机器人进行开发,欢迎加入我们的抢先体验计划,成为这一社区中的一员。即刻下载Isaac Sim,体验更高级的机器人模拟功能。
来源:业界供稿
好文章,需要你的鼓励


雪佛兰Equinox EV租赁价格大涨,月租金突破500美元
雪佛兰Equinox EV本月租赁价格大幅上涨。此前LT1车型月供仅需269美元,如今同等条件下已涨至554美元/月。与此同时,优惠力度也从最高1万美元缩水至1000美元,融资利率从0%升至2.9%。相比之下,2027款Bolt EV月供仅411美元,现代IONIQ 5最低259美元/月,特斯拉Model Y起步459美元/月,Equinox EV的性价比优势明显减弱。

清华大学与泉城实验室联手破解AI“千人一面“难题:当语言模型学会真正理解人类的多样性
清华大学与泉城实验室提出PSII框架,通过将人口统计学向量和文化价值向量直接注入大型语言模型内部隐藏层,有效解决AI民意模拟中的"多样性崩塌"问题,显著提升模拟结果对真实人类分布的还原度。

Decart发布Oasis 3世界模型,为机器人训练注入真实感
前沿AI研究机构Decart发布最新世界模型Oasis 3,旨在弥合虚拟仿真与物理AI之间的鸿沟。该模型将超写实交互图形能力与强大物理引擎相结合,可生成动作驱动的视频流,支持多视角环境模拟,延迟低于200毫秒。开发者能够借助自然语言提示,快速构建多样化极端场景,有效解决机器人和自动驾驶领域长期存在的"仿真到现实"差距问题,大幅降低物理AI训练成本。

当AI“侦探“学会质疑自己的情报员:马萨诸塞大学研究团队让搜索引擎不再“将错就错“
马萨诸塞大学研究团队提出Critic-R框架,通过独立批评者模型读取AI推理中的"内心独白"来检验检索质量,并利用自动产生的判断信号训练检索模型,无需人工标注即可提升多跳问答准确率约10.9%。
2021
06/29
10:54
分享
点赞

雪佛兰Equinox EV租赁价格大涨,月租金突破500美元
无锡(惠山)国产智算中心一期正式点亮,摩尔线程为具身智能及千行百业夯实算力底座
Decart发布Oasis 3世界模型,为机器人训练注入真实感
Visual Components 5.1发布:工厂仿真软件新版本支持大规模自主生产环境验证
AI既令人兴奋又让人焦虑,企业究竟该如何面对?
芬兰与瑞典联手推进6G韧性联合研究计划
微软公布智能体AI系统七大新型安全漏洞
GitHub Copilot推出桌面应用与画布功能,同步启用按量计费模式
谷歌DeepMind分拆公司如何追踪隐藏的药物靶点
Snowflake峰会观察:智能体浪潮下平台的核心竞争力之争
亚马逊"故事回顾"功能正式向美国Kindle设备及iPhone应用推出
Anthropic推出聚焦生命科学的全新大语言模型
NVIDIA Blackwell 现已在云端全面可用
为“代理式AI”装上“护栏” NVIDIA打造“三重防线”
黄仁勋现身北京致辞:60年后,计算机正被重新定义
CES 2025 | NVIDIA Isaac GR00T Blueprint 让人形机器人“加速进化”
未来,就在我们手中
CES 2025 | 代理式AI崛起:NVIDIA定义下一代“代理式 AI Blueprint”
深度学习最佳 GPU,知多少?
NVIDIA推出用于多语言生成式人工智能的NeMo Retriever微服务
NVIDIA 初创加速计划 | 2024 NVIDIA 创业企业展示完美收官!
老黄掏出“迷你版AI超算”,每秒67万亿次运算,仅售2070元人民币
