
MWC 2021:Nvidia宣布5G边缘基础设施平台将支持Arm CPU
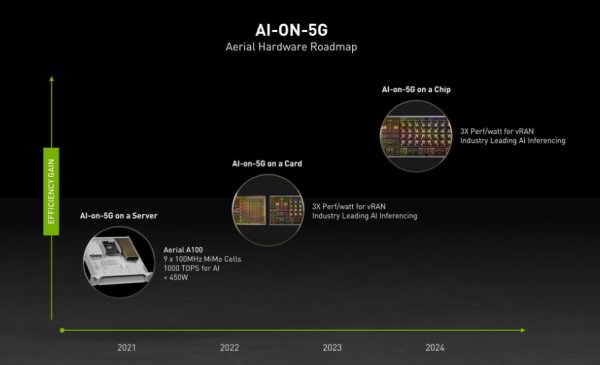
Nvidia正在加紧为网络边缘的5G应用提供动力,在Nvidia Aerial A100 AI-on-5G平台上增加对Arm CPU的支持。
Aerial A100 AI-on-5G是一个统一的融合平台,旨在提供边缘人工智能计算和5G连接。该平台将于4月推出,它把Nvidia Aerial软件开发套件与Nvidia BlueField-2 A100融合卡相结合,后者可以将多个CPU与Nvidia的数据中心处理单元进行配对。
该平台可以为高性能、软件定义的5G基站和人工智能应用提供支持,例如精密制造的机器人、自动导引车、无人机、无线摄像头、自助结账等。换句话说,它为企业提供了在边缘部署智能服务的一个选择。
因为Aerial A100 AI-on-5G平台已经支持英特尔的x86 CPU,所以今天Nvidia在巴塞罗那MWC世界移动通信展上发布的这项公告,有望为用户带来更多选择。Nvidia称,经过Nvidia认证的系统将创造一个“简化的路径,可构建和部署自托管的vRAN,把AI和5G带给私营企业、网络设备公司、软件制造商和电信服务提供商。”
Nvidia表示,Aerial A100 AI-on-5G平台的Arm版本将配置16个Arm Cortex A78处理器,以及即将推出的Nvidia BlueField-3 DPU,从而形成一个独立的融合卡,用于在云原生5G上运行边缘AI应用虚拟无线电区域网络。
Nvidia宣布支持Arm CPU并不令人意外,因为Nvidia正在以400亿美元收购Arm的过程中,这项交易正在接受监管机构的审查,预计要到明年才能完成。
Nvidia电信行业高级副总裁Ronnie Vasishta表示:“我们正在将计算人工智能和电信5G相结合,为5G上的人工智能创建一个软件定义的平台。通过支持Arm,我们不断成长的Aerial平台将加速推进无处不在的‘AI-on-5G’。”
据称,Nvidia的BlueField-3 A100 DPU是专为人工智能和加速计算工作负载设计开发的。它针对5G连接进行了优化,旨在与CPU协同工作。该DPU负责基础设施管理任务,例如扫描网络流量中的恶意软件和调度存储容量,通常这些任务是由CPU处理的,因此把这些任务卸载到DPU,可以让CPU资源释放出来专注用于运行计算任务。”
BlueField-3 DPU将于2022年上半年上市,届时还将搭载Nvidia的AI软件库,包括预训练的模型和Aerial 5G SDK,帮助开发人员缩短部署时间,向他们的应用中添加各种AI功能。
“Bluefield-3结合了Nvidia加速计算和Arm的性能水平,这一组合有助于扩大Arm的生态系统,让网络供应商在创建和部署5G系统方面有更多的选择,”Arm公司高级副总裁、基础设施业务线总经理Chris Bergey这样表示。
首个AI-on-5G创新实验室
打造平台是一回事,但让客户采用这个平台就是另一回事了。因此,Nvidia宣布与谷歌展开合作,创建了首个AI-on-5G创新实验室。
该实验室主要面向那些希望在Nvidia这个新平台上开发和测试解决方案的网络基础设施提供商和AI软件开发者。谷歌将主要贡献他们的Google Anthos平台,用于开发多云和边缘应用。
这对开发者来说是有一定吸引力的,因为Anthos本身就是一个受欢迎的产品,让开发者可以创建由Kubernetes管理的云原生容器化应用,运行在任何类型的云或边缘基础设施上。
谷歌云网络副总裁兼总经理Shailesh Shukla表示:“通过Anthos应用平台,谷歌云将让很多垂直市场的服务提供商和企业能够在网络边缘通过5G进行无缝连接。我们很高兴能够扩大与Nvidia的合作。”
两家公司表示,希望在今年年底之前启动并运行该实验室。
Constellation Research分析师Holger Mueller认为,5G和边缘的争夺战主要是集中在是在平台方面的,谁能够开发出最吸引人的产品并且得到最多企业的采用,谁就将赢得这场竞赛。
“Nvidia在这两方面都取得了进展,一方面Nvidia在5G人工智能软件平台上增加了对Arm芯片的支持,另一方面在企业采用方面,Nvidia与谷歌展开合作,使企业能够熟悉他们的5G AI平台并使用谷歌Anthos为其构建应用。”
来源:siliconANGLE
好文章,需要你的鼓励


AI智能体遭间接提示注入攻击,多款主流模型被测试攻破
Zscaler测试发现,多款主流大语言模型驱动的自主AI智能体存在间接提示注入(IPI)漏洞。测试涵盖26个LLM,其中Llama3和Gemini部分版本被列为"易受攻击",而低版本模型有时表现优于高端版本。专家指出,攻击面源于Transformer架构本身,无法有效区分可信指令与不可信内容。若该漏洞被利用于采购、支付等企业流程,损失规模将远超测试场景中的小额欺诈。

华中科技大学等机构联手打造“科学图像理解“新基准:AI能真正看懂科学示意图吗?
华中科技大学等机构构建SciIR框架,通过8万张科学图像数据集和原子化评测基准,系统解决AI生成科学示意图时"外表合理、内核错误"的核心难题。

ECMAScript 2026正式获批:JavaScript迎来第17版规范更新
ECMA国际已于6月30日正式批准ECMAScript 2026规范,即JavaScript编程语言规范第17版。此版本新增多项实用功能,包括:Math.sumPrecise用于高精度数值求和;Iterator.concat用于迭代器序列化;Array.fromAsync支持从异步来源构建数组;Error.isError用于识别错误对象;Map和WeakMap新增默认值检索方法;Uint8Array支持十六进制与Base64字符串互转;JSON.parse新增源段访问参数;JSON.rawJSON可精细控制原始值的序列化输出。

韩国科学技术院研究团队的新突破:用“双镜头拍照法“让AI用极少数据学会理解图片和文字
韩国科学技术院提出RAHA方法,将图文数据提升到双曲空间,通过范围-残差子空间分解实现选择性语义压缩,用极少合成数据高效训练图文检索模型。
2021
06/29
10:51
分享
点赞

ECMAScript 2026正式获批:JavaScript迎来第17版规范更新
联想Legion 9i Gen 10评测:18英寸性能与体型双料巨兽
大型表格模型:攻克大语言模型的结构化数据难题
太空太阳能发电正式进入能源行业视野
Character.ai杀入微短剧赛道,AI角色可与用户实时互动
西门子联手Databricks与FFT,将生产数据转化为可扩展的AI洞察
Intrinsic如何用软件重新定义工厂自动化未来
AI赋能机器人首次实现塞拉诺火腿自动化标签注射
高带宽内存:它是什么,为何至关重要
四张老显卡拼出64G显存,但我劝你别轻易试
美国国家科学基金会投入2000万美元推进量子研究,对未来数据中心意味着什么?
AI基础设施扩张推高内存成本,低价手机或将大幅减少
NVIDIA Blackwell 现已在云端全面可用
为“代理式AI”装上“护栏” NVIDIA打造“三重防线”
黄仁勋现身北京致辞:60年后,计算机正被重新定义
CES 2025 | NVIDIA Isaac GR00T Blueprint 让人形机器人“加速进化”
未来,就在我们手中
CES 2025 | 代理式AI崛起:NVIDIA定义下一代“代理式 AI Blueprint”
深度学习最佳 GPU,知多少?
NVIDIA推出用于多语言生成式人工智能的NeMo Retriever微服务
NVIDIA 初创加速计划 | 2024 NVIDIA 创业企业展示完美收官!
老黄掏出“迷你版AI超算”,每秒67万亿次运算,仅售2070元人民币
