
助力快速实现生产级AI NVIDIA正式发布迁移学习工具包(TLT)3.0和预训练模型 原创
近日,在本周举行的CVPR(国际计算机视觉与模式识别会议)上,NVIDIA发布全新预训练模型并宣布迁移学习工具包(TLT)3.0全面公开可用。迁移学习工具包在NVIDIA TAO平台指导工作流程以创建AI的过程中起到核心作用。新版本包括各种高精度和高性能计算机视觉和对话式AI预训练模型,以及一套强大的生产级功能,可将AI开发能力提升10倍。
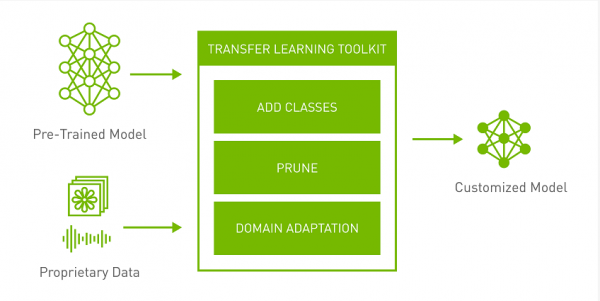
NVIDIA提供高质量的预训练模型和TLT以帮助降低大规模数据采集和标注成本,同时告别从头开始训练AI/机器学习模型的负担。初入计算机视觉和语音服务市场的企业现在也可以在不具备大规模AI开发团队的情况下部署生产级AI。
迁移学习的举一反三
随着企业积极拥抱人工智能技术,强大的AI开发工具成为企业的最大诉求。借助开发工具,企业可以可以更好地加快加快产品上市、降低开发成本以及定制化。不过,对于许多尝试使用开源AI产品创建模型进行训练的工程和研究团队来说,在生产中部署自定义、高精度、高性能AI模型的挑战非常大,从头开始创建一个模型不但耗时耗力,而且成本高昂。而迁移学习可以解决这样的问题。
迁移学习(Transfer Learning)是一种机器学习方法,是把一个领域(即源领域)的知识,迁移到另外一个领域(即目标领域),使得目标领域能够取得更好的学习效果。
NVIDIA Transfer Learning Toolkit是一个基于Python的工具包,它使开发人员能够使用NVIDIA预先训练好的模型,并让开发人员能够使用流行的网络架构适配他们自己的数据来训练、调整、修剪和导出以进行部署。它拥有简单的接口和抽象,提高了深度学习训练工作流程的效率。
利用第三方预先训练好的模型的好处是非常多的,比如不用自己构建训练数据进行模型旋律,节省IT建设投入,同时也不用团队成员学习众多的开源深度学习框架。虽然选择预先训练好的模型会带来诸多好处,但是这些模型经常存在一些问题:现成的模型在特定的应用领域中精度较低或者没有针对GPU进行优化等。
简化AI工作流程
NVIDIA TLT是一个能够消除AI/DL框架复杂性,无需编码就能更快构建生产级预训练模型的AI工具包。TLT通过NVIDIA为常见AI任务开发的多用途生产级模型或者ResNet、VGG、FasterRCNN、RetinaNet和YOLOv3/v4等100多种神经网络架构组合,使用自己的数据对特定用例的模型进行微调。所有模型均可从NVIDIA NGC获得。
预训练模型加速了开发人员的深度学习训练过程,并且减少了大规模数据收集、标记和从零开始训练模型相关的成本。开发者选择NVIDIA提供的预先训练好的模型,然后结合自己场景或者用例的数据,就可以得到输出模型。迁移学习后得到的模型可以直接进入到深度学习应用/项目的部署阶段。
TLT 3.0新版本亮点包括:
- 一个支持边缘实时推理的姿态估计模型,其推理性能比OpenPose模型快9倍。
- PeopleSemSegNet,一个用于人物检测的语义分割网络。
- 各种行业用例中的计算机视觉预训练模型,如车牌检测和识别、心率监测、情绪识别、面部特征点等。
- CitriNet,一个使用各种专有特定域和开源数据集进行训练的新语音识别模型。
- 一个用于问题回答的新Megatron Uncased模型以及许多其他支持语音文本转换、命名实体识别、标点符号和文本分类的预训练模型。
- AWS、GCP和Azure上的训练支持
- 在用于视觉AI的NVIDIA Triton和DeepStream SDK上以及用于对话式AI的Jarvis上的开箱即用部署。
除了技术层面的更新,TLT也在生态合作方面取得了重大进展。训练可靠的AI和机器学习模型需要大量精确标记的数据,而大规模获取标记和注释的数据对一些企业来说极具挑战。
TLT 3.0现在还与AI Reverie、Appen、Hasty.ai、Labelbox、Sama和Sky Engine等数家领先合作伙伴的平台集成,这些合作伙伴提供大量多样化的高质量标签数据,使端到端AI/机器学习工作流程变得更快。
企业可以使用这些合作伙伴的服务来生成和注释数据、通过与TLT无缝集成进行模型训练和优化并使用DeepStream SDK或Jarvis部署模型以创建可靠的计算机视觉和对话式AI应用。
结语
从TLT 3.0可以看到NVIDIA在推动AI应用快速开发的赋能之举,当前AI技术已经深入各行各业,如何将AI与自身业务场景进行融合成为企业的最大诉求。TLT 3.0的推出可以借助NVIDIA预先训练好的模型,帮助企业优化AI工作流程,快速开发AI应用。
来源:至顶网计算频道
好文章,需要你的鼓励


OpenClaw 智能体正式登陆 iOS 与 Android 平台
开源AI智能体OpenClaw今日宣布正式推出iOS和Android应用。用户可通过手机连接OpenClaw Gateway路由层,调用AI智能体及其工具完成各类任务,涵盖编程、餐饮规划等场景。OpenClaw此前因MoltBook社交媒体实验走红,其创始人Peter Steinberger已于今年2月加入OpenAI。尽管MoltBook事件后来被揭露部分由真人假扮智能体,此次移动端上线标志着AI智能体正加速渗透日常生活。

当AI团队“各自为政“时,伊利诺伊大学如何用“梯度指纹“找出问题根源?
多智能体AI系统常因无法精准定位错误来源而难以优化,GBC通过梯度计算为每个AI的输出建立影响力评分,实现跨智能体的精细归因与针对性提示词优化。

“借道”MoP封装,AMD打破“存储墙”与“空间锁”
AMD 最近推出了第二代 AMD Versal Premium MoP(Memory on Package,封装上内存)自适应SoC。

香港大学与字节跳动联手:教机器人“看“人类动作来学习新技能,只需去掉那些令人头疼的旋转信息
香港大学与字节跳动研究团队提出"桥接动作"概念,通过只学习人类手腕的平移轨迹(丢弃噪声大且易误导机器人的旋转信息),实现从人类操作视频向双臂机器人的高效技能迁移。
2021
06/25
10:19
分享
点赞

智引芯程,定义未来:德州仪器亮相 2026 慕尼黑上海电子展
“借道”MoP封装,AMD打破“存储墙”与“空间锁”
优必选万台超仿生人形机器人,要在今年进家庭?
Albertsons借助Databricks构建零售商品智能决策平台
微软正式将 Windows 11 打造为 AI 操作系统
工作中使用未授权AI工具之前,请三思
全球首座AI博物馆Dataland:用数据创造多感官视觉盛宴
ANS框架:Linux基金会为AI智能体建立DNS式信任机制
Origin PC Millennium台式机评测:构建出色但配置并非最优选择
Hirebotics推出无代码防爆协作机器人,专为工业喷涂设计
软件定义汽车时代:从“年”到“周”,研发团队如何高效驾驭复杂度?
美国消费品安全委员会拟出台电动自行车电池安全新规
NVIDIA Blackwell 现已在云端全面可用
为“代理式AI”装上“护栏” NVIDIA打造“三重防线”
黄仁勋现身北京致辞:60年后,计算机正被重新定义
CES 2025 | NVIDIA Isaac GR00T Blueprint 让人形机器人“加速进化”
未来,就在我们手中
CES 2025 | 代理式AI崛起:NVIDIA定义下一代“代理式 AI Blueprint”
深度学习最佳 GPU,知多少?
NVIDIA推出用于多语言生成式人工智能的NeMo Retriever微服务
NVIDIA 初创加速计划 | 2024 NVIDIA 创业企业展示完美收官!
老黄掏出“迷你版AI超算”,每秒67万亿次运算,仅售2070元人民币
