
ThoughtWorks科技棱镜: 计算结构的变革
技术的快速发展令人目眩,对商业的影响深远而难测。ThoughtWorks科技棱镜未来技术趋势分析报告应运而生。
作为一家软件和数字化转型咨询公司,ThoughtWorks必须领先于技术发展趋势,这样才能帮助我们的客户为企业建立战略优势。我们的咨询顾问和客户遍布全球,形成一个庞大的网络,确保我们能对未来技术趋势的发展进程和潜在影响建立广泛视野。我们将在本报告中分享对技术趋势的洞察,这些见解来自于为期五年的对大量客户的调查研究,让外界能一窥为何我们能够通过前沿技术帮助企业实现转型。
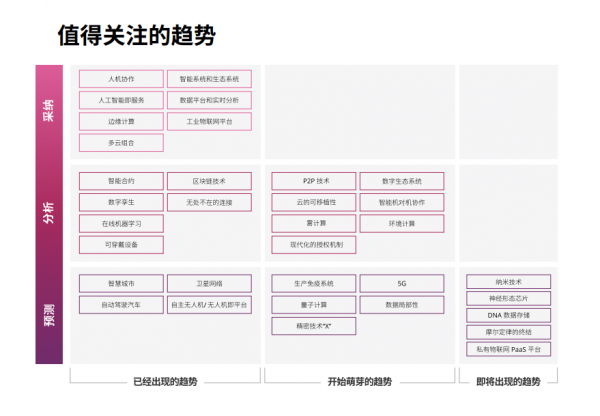
科技棱镜未来技术趋势分析报告涵盖120多个独立技术趋势;为了帮助您深入理解这些趋势,我们分六个“视角”来进行分析。这些视角将帮助您重点了解各个发展趋势对贵企业意味着什么,以及您需要如何做好准备。这些视角可以单独使用,也可以相互结合以形成更多的视角,开辟全新的调查途径和思路。
下面是我们节选“计算结构的变革”的内容,更多完整内容可以参见报告全文。
计算的边界正在扩大,这就为企业带来了无限的可能性。新兴的计算环境不仅为挖掘前所未有的数据分析和处理能力提供了机会,而且也为构建计算架构以更好地满足业务需求打开了机遇之门。
技术透镜未来技术趋势分析为了适应互联网及其所有用户的未来需求,计算领域正在发生变化。现在,数据处理不再仅仅集中在云服务中,而且还会发生在网络边缘、设备之中、跨多个云和托管服务。随着量子和生物计算的兴起,甚至有望实现基于DNA的存储,未来计算领域的发展可能会更加激动人心。
在过去,只有大企业才需要大规模的数据处理。自智能手机出现和物联网设备普及以来,这些设备产生的数据海量增加。数据分析不再是企业数据仓库的专属领域;在由人、设备、汽车、工厂和城市组成的互联网络中,数据可以存在于任何地方。数据越多,对计算能力的要求也就越高。
除了数据和计算位置的变化,计算机体系结构也在不断演进。对移动性的推进大大推动了高效能芯片的开发,甚至包括同时配备“大/小”计算内核的芯片设计,这些计算内核能根据负载进行优化,以实现高性能和高效能。
机会
企业可以通过做出明智的计算选择,来优化IT成本,并且为消费者提供更快响应服务。在企业环境中,并非所有部署方案都能达到相同效果。
尽管云计算容易实现高可用,但数据的实际位置和处理方式依然重要。创新的网络技术无法克服基础的物理问题;与部署在本地甚至部署在家庭或工作场所的数据中心相比,部署在地球另一边的数据中心延迟总是会更高。
这意味着,根据您选择在何处放置数据、如何移动数据以及如何使用数据进行计算,成本和客户体验将会千差万别。选择最合适的硬件(包括芯片类型、大小和内存)将直接影响所需的实例或虚拟机的数量。一些应用领域(医疗保健、金融服务、电信和工业物联网)要求延迟更低,集中式平台无法满足这种要求,因此就需要配置更多的本地计算资源。
无论采用何种资源架构,务必牢记,最终客户将会认为这些都是您的责任。消费者希望他们的联网设备能正常工作,如果由于云提供商宕机,他们无法按响门铃或是解锁联网汽车,他们会责怪门铃供应商或汽车供应商,而不会归咎于提供底层计算的公司。

来源:业界供稿
好文章,需要你的鼓励



腾讯混元视觉团队打造“图像翻译官“:让AI用离散数字读懂每一张照片
腾讯等机构提出ViQ框架,通过两阶段渐进量化训练,让离散视觉编码在多模态理解和图像重建上同时追平连续特征编码器,训练速度最高提升70%。

Chrome、Edge、Firefox 浏览器 AI 功能横评,我最终选了这款
作者对Chrome、Edge和Firefox三款主流浏览器的内置AI功能进行了实测对比。Chrome依托Gemini提供搜索摘要与提示词保存功能;Edge集成Copilot,可针对网页、PDF及多标签页进行问答;Firefox则支持多款AI聊天机器人,并提供更强的隐私保护。综合体验后,作者最终选择Edge作为AI辅助浏览的首选,但仍以Firefox作为默认浏览器。

香港科技大学联手华为研究院:AI绘图训练速度提升2.78倍,秘诀藏在“概率分工“里
香港科技大学与华为联合提出LISA训练方法,通过让副网络对齐"似然分数",将ControlNet等图像生成模型的训练收敛速度提升逾2.78倍,同时改善图像质量与条件控制精度。
2021
03/18
11:04
分享
点赞

Chrome、Edge、Firefox 浏览器 AI 功能横评,我最终选了这款
Firefly宇航公司首次在月球轨道运行NVIDIA Jetson平台
超越数据驱动美学:计算与审美的跨世纪探索
韩国携手三星和SK海力士启动5840亿美元芯片制造计划
Gemini 个性化 AI 图像生成功能现向美国用户免费开放
HP与OpenAI达成合作,共同部署企业级AI智能体平台
Windows 10 用户最长可免费获得安全更新至 2027 年
Raise Us:AI巨头联合出资5亿美元帮助劳动者应对AI时代冲击
MIT首届音乐科技研究展:AI与音乐共创的跨学科探索
特斯拉"完全自动驾驶"集体诉讼引用Electrek报道作为证据
福特3万美元电动皮卡再度现身测试路段
美国最大变压器工厂扩建,剑指AI数据中心用电需求
Thoughtworks召开第28期《技术雷达》发布会,指出面对人工智能趋势,应用大语言模型的两条路
协同创新 Thoughtworks积极推动行业数字化转型
Thoughtworks Live:和衷共济,为企业数字化转型升级加码
Thoughtworks重磅发布变革设计——面向复杂和未知的创新范式变革
敏捷应对不确定性 2022 Thoughtworks技术雷达峰会精彩上演
ThoughtWorks徐昊:从组与织谈起,技术变迁下平台与组织的思考
ThoughtWorks蒋帆:安全“下沉”,DevSecOps向左走向右走
解构数字化时代平台理念——2021年思特沃克技术雷达峰会举行
ThoughtWorks科技棱镜: 计算结构的变革
业务变化不息,架构演进不止 第四届领域驱动设计峰会线上开启
