
NVIDIA Jetson Nano 2GB 系列文章(4):体验并行计算性能
在本系列上一篇文章里,我们介绍了如何进行网络设置及添加 SWAPFile 虚拟内存。在本篇文章中,我们将会带领大家体验并行计算性能。
当我们在 Jetson Nano 2GB 上安装好 JetPack 系统后,就可以开始运行一些范例。借助范例来体验,是最直接的方式。
好多开发者问 Jetson Nano 2GB 真的可以支持 CUDA 么?本篇我们教大家跑几个经典 CUDA Sample,带领大家逐步执行,熟悉 Ubuntu 的指令,因为未来在 Jetson Nano 2GB 上的实验,全部都需要在文字终端中输入指令。
注意:在绝大部分 Linux 操作系统中,因为大量工作都是在文字终端中操作,因此需要为文字指令提供更方便的协助:
-
可以用“复制-粘贴”方式将教程的指令复制到文字终端上执行
-
文字终端提供“补齐”功能,即输入指令前面几个字母,如果记不住完整的指令,只要按一下“TAB”键,就能提供补齐功能,可以在实际操作的时候去熟悉。
CUDA 范例体验性能
CUDA(Compute Unified Device Architecture,统一计算架构)是 NVIDIA 过去十多年异军突起的最重要核心技术,也是近年来并行计算领域中最被称颂的技术。不过 CUDA 这项技术比较偏地底层的加速应用,需要有足够的 C/C++ 等编程基础与并行计算概念才好上手,本系列文章专注于“轻松上手”的任务,因此并不占用篇幅去讲解 CUDA 的原理。
接下来我们先以几个 CUDA 经典范例,让大家感受一下并行计算所带来的惊人威力,这是 Jetson 嵌入式设备执行 AI 深度学习应用的一个最关键动力来源。
编译 CUDA Samples
JetPack 系统将 CUDA 环境安装在 /usr/local/cuda 下面,请使用以下指令进入:

说明:有人可能发现在 /usr/local 下面有 <cuda> 目录与 <cuda-10.2> 目录,两者的内容完全一样。事实上 <cuda> 这个目录是一种类似 Windows 捷径的软链接方式,实际的内容指向 <cuda-10.2> 这个目录。因为 JetPack 以后会更新 CUDA 版本,所有 <cuda-10.2> 可能会改变,于是就使用 <cuda> 软连接来确保一致性。
进入到这个目录之后,指向“ls”指令,看看里面有什么内容:


这里会看到从 <0_Simple> 到 <7_CUDALibraries> 等多个范例目录,每个目录下都有多个范例 C/C++ 源代码,NVIDIA 在这方面积累十多年经验,提供的范例相当丰富,绝大部分的基础应用都能在这里找到对应范例源代码。
每个范例执行之前,都需要经过“编译”的工作,编译的执行有两种选择:
-
在这里(/usr/local/cuda/samples)直接执行“sudo make”编译指令。
您可以看到目录里面有个 Makefile 文件,make 编译指令会根据 Makefile 的内容进行操作,这个目录的 Makefile 文件会引导 make 指令将整个 <samples> 目录下的所有范例全部编译完成,比较省事,当然也会耗费较多时间。
-
到个别目录中,对个别范例进行编译。
海洋模拟实验-oceanFFT
我们来执行一个海洋模拟实验,这个执行的范例在<5_Simulations/oceanFFT>,就可以执行以下指令:
# 确认现在的位置在 /usr/local/cuda/samples

说明:
-
在指令“cd 5_Simulations/oceanFFT/”的部分,当您输入“cd 5”然后按下“TAB”键,就会发现系统为您将“_Simulations/”字串补齐,后面内容也一样,当您继续输入“o”字母,然按下“TAB”键,系统自动将“ceanFFT/”等字母补齐,非常方便!
-
在 /usr 下面目录的拥有人(owner)是 root 身份,而不是您登录的身份,因此执行需要 sudo 指令取得执行权限
-
在 make 指令后面加上“-jn”参数,可以调用多线程方式加快编译性能,但 n 的数量取决于可用的 CPU 核数。前面提过 Jetson Nano 2GB 不同工作模式下的 CPU 可用核数不一样
执行上述指令后,会看到以下截屏的讯息,没有出现任何错误,表示编译成功。

接下来检查一下编译的结果,这里使用 “ls -l”指令来查看,会比较清楚。

会看到如下面截屏的信息。最左边一栏代表每个文件的属性,这里不多做解释,接下来的一栏“root root”表示该文件的拥有者,然后是占用空间、生成日期/时间,最右边则是文件名。
在这里的讯息中,可以看到“oecanFFT”、“oecanFFT_kernel.o”、“oecanFFT.o”这三个文件的生成日期与其他文件不同,就是这次编译过程中所产生的。其中两个 .o 的文件属于“中间文件”,而我们所需要的文件就是“oecanFFT”这个执行文件。

再查看“oecanFFT”最左边的的属性中有“x”,表示是“可执行”文件。接下来就试试看它的执行结果如何?
有些初学者一开始会执行以下指令,看看会出现什么结果:

结果出现以下的错误信息:
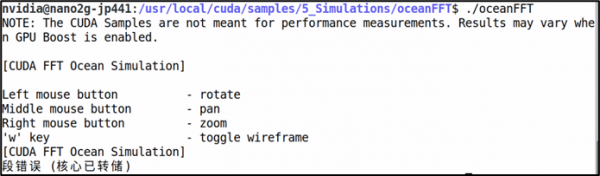
这个问题就是前面所说到的“拥有者权限”问题,因此解决方法就是在指令前面加上“sudo”就行,然后就能看到下面截屏的动态海洋模拟效果。

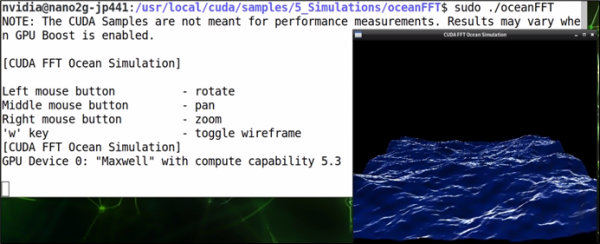
这样就完成了第一个 CUDA 范例的执行,请根据上图左边提示,利用鼠标与一些简单的热键来操作 oceanFFT 模拟效果。
烟雾粒子模拟- smokeParticles
这个范例也在 /usr/local/cuda/samples/5_Simulations 里面,可以在前面一个范例的位置(oceanFFT)执行以下指令进入:

也可以在任何位置执行以下指令进入:

进到 <smokeParticles> 目录后,同样执行编译动作

可能会发现这个范例的编译时间,比前面的 oceanFFT 更久,大约需要 3 分钟 20 秒的时间,因为复杂度变高了。编译完成后,同样执行以下指令去启动这个范例:

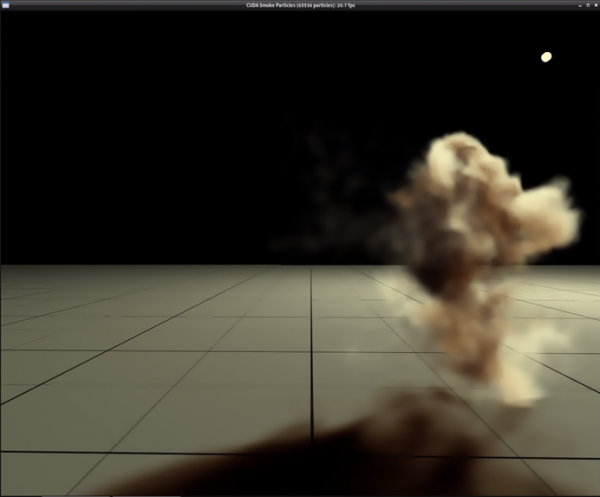
这个实验除了模拟(256x256=65,536)个烟雾粒子的运动变化,还有光影处理的部分,可以看到在截屏右上角有个光点,这是作为模拟光源的位置,然后烟雾粒子运动时,还要计算影子的动态,所以计算量相对比较大。
执行 nbody 粒子碰撞模拟
前面两个范例都只有 GPU 的执行,没办法体会 GPU 并行计算与 CPU 计算的性能差异,这个 nbody 范例提供 GPU 与 CPU 的执行,可以让大家更清楚两者之间的性能差距。
Nbody 范例也在 /usr/local/cuda/samples/5_Simulations 下面,如果你还在前面一个范例的位置,可以执行以下指令进入 nbody。

也可以在任何位置执行以下指令进入:

进到 <nbody> 目录后,同样执行编译动作

编译是速度挺快,大约一分钟的时间。接着同样执行 nbody 执行文件:

执行结果会出现如下方视窗的动态模拟状况。

这个范例预设是在 GPU 上执行,并且预设粒子数量为 1024 个。可以视窗头部看到一些性能相关的信息,包括:

执行的终端里会出现如下截屏的信息,有很多参数可以设定,包括粒子数量可以用“-numbodies=<N>”这个参数去改变。

这个范例能支持多个 GPU 同时计算,不过 Jetson Nano 2GB 只有一个 GPU,因此“-device=<d>”变量在这里起不了作用。此外,Jetson Nano 2GB 不支持双精度计算,所以“-fp64”这个变量也没有用处。
接下去使用“-cpu”这个参数,来指定由 CPU 执行 nbody 这个范例,指令如下:

一开始执行,相信您就能感受到性能的差距。下面截屏是 CPU 执行的结果:
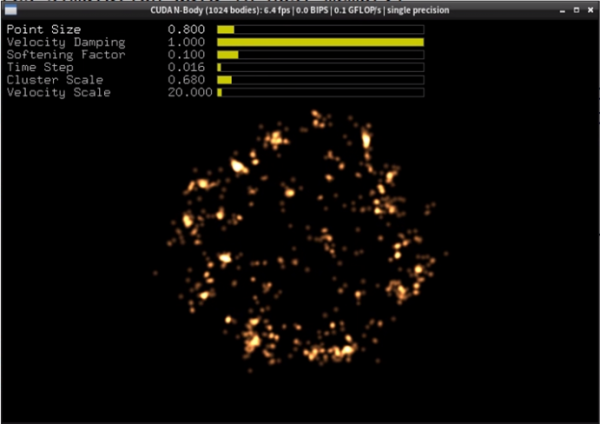
将视窗头部的性能数据与前一个在 GPU 上执行的结果进行比较,可以发现各项指标大约有 10 倍左右的差距,这效果就非常显而易见了。
以上为 Jetson Nano 2GB 上的 CUDA Sample 中三个范例的执行,在 CUDA Sample 中总共有数十个范例,您都可以按照前面所说的步骤去编译、执行,多尝试一些范例会更加感受到 Jetson Nano 2GB 的性能优势。
来源:英伟达
好文章,需要你的鼓励


数据中心最新动态:2026年7月
全球数据中心建设需求持续高涨。北美方面,美国数据中心建设支出年化达510亿美元,微软在威斯康星州开放33亿美元设施,亚马逊和谷歌宣布在密苏里州合计投资250亿美元。欧洲方面,SoftBank将在法国建设5GW AI数据中心,投资额达750亿欧元。亚太地区,AirTrunk计划在印度投资210亿美元建设3GW数据中心。中东与非洲地区也有多项大规模项目落地。

当AI做“陪练老师“:弗吉尼亚理工大学等机构用大模型的“解题日记“预测考题难度
这项研究提出Epi2Diff方法,通过将大型推理模型的解题思考过程拆解为认知片段序列,提取过程特征预测考题对人类的难度,在四个真实考试数据集上超越了所有对比基线。

企业如何在边缘端与云端之间合理分配AI算力
随着企业将AI融入机器人、工业设备等物理基础设施,边云协同架构正成为关键课题。以Luminous Robotics和先正达为例:前者在太阳能农场部署的机器人每秒做出10次决策,数据定期上传云端持续优化模型;后者通过Cropwise平台整合卫星、无人机、拖拉机传感器数据,辅助农民完成约150项农业决策。两家公司均强调,边缘端负责实时响应,云端负责模型训练与更新,同时保持人工监督以确保安全与准确性。

南京大学联手阿里巴巴:让AI图像生成变得更“聪明“,一个让图像生成模型真正理解画面的新框架
南京大学与阿里巴巴提出MIMFlow,将掩码图像建模与标准化流端到端融合,让生成模型专注语义建模,以更少参数和更少令牌在ImageNet上取得FID 2.50的优异表现。
2021
03/17
16:38
分享
点赞

NVIDIA Blackwell 现已在云端全面可用
为“代理式AI”装上“护栏” NVIDIA打造“三重防线”
黄仁勋现身北京致辞:60年后,计算机正被重新定义
CES 2025 | NVIDIA Isaac GR00T Blueprint 让人形机器人“加速进化”
未来,就在我们手中
CES 2025 | 代理式AI崛起:NVIDIA定义下一代“代理式 AI Blueprint”
深度学习最佳 GPU,知多少?
NVIDIA推出用于多语言生成式人工智能的NeMo Retriever微服务
NVIDIA 初创加速计划 | 2024 NVIDIA 创业企业展示完美收官!
老黄掏出“迷你版AI超算”,每秒67万亿次运算,仅售2070元人民币
