
ISC TOP500榜单公布 NVIDIA为HPC按下“加速键” 原创
至顶网计算频道 06月23日 新闻消息(文/李祥敬):又到了每年一届的ISC TOP500榜单的公布时刻,由于众所周知的疫情原因,此次TOP500的榜单采用线上直播发布。
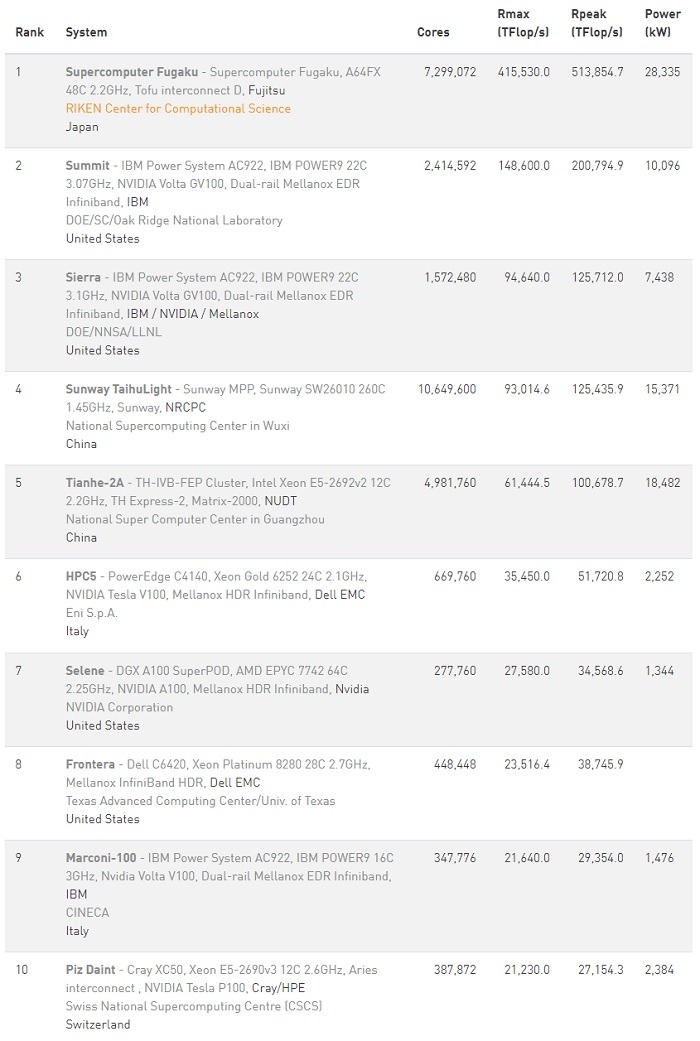
透过最新的榜单,我们看到全球排名前十的超级计算机中有8台采用了NVIDIA GPU、InfiniBand网络技术,或同时采用了两种技术。其中包括美国、欧洲和中国最强大的超级计算机系统。而在2017年6月发布的榜单上,采用两家公司的系统占比总和还不到一半(203套)。

在TOP500榜单的所有系统中,有三分之二的系统(333套)采用了NVIDIA的技术。而榜单上有将近四分之三(74%)的全新InfiniBand系统采用了NVIDIA Mellanox HDR 200G InfiniBand。自2019年11月以来,榜单上使用HDR InfiniBand的TOP500系统数量几乎增加了一倍。共有141台超级计算机使用了InfiniBand,自2019年6月以来增长了12%。
凭借快速数据传输、极低延迟和智能网络计算引擎等技术上的优势,InfiniBand成为众多行业加速研究和应用的标准。比如许多全球领先的气象服务机构都选择NVIDIA Mellanox InfiniBand网络加速其超级计算平台,这些气象服务机构包括西班牙气象局、中国气象局、芬兰气象局、NASA和荷兰皇家气象局。
从上述榜单数据可以看到NVIDIA GPU加速计算和Mellanox InfiniBand网络技术在高性能计算HPC中不可动摇的地位,同时这也从侧面显示出了NVIDIA大价钱收购Mellanox的前瞻性,而随着整合的加速,相信两者会给整个HPC市场带来前所未有的变革作用。
对抗COVID-19
2020年的新冠病毒疫情给全球造成了不可估量的影响。为了有效对抗病毒,全球各地的科学家和研究人员都在竞相寻找治愈COVID-19的方法,而NVIDIA科学计算平台在其中发挥了至关重要的作用。此前NVIDIA就宣布加入COVID-19 HPC联盟(COVID-19 HPC Consortium),携手各界一起查清新冠病毒的本质和来源。

在基因组学领域,Oxford Nanopore Technologies使用NVIDIA GPU在短短7个小时内完成了病毒基因组测序。
在感染分析和预测领域,NVIDIA RAPIDS团队使用GPU加速的Plotly Dash(一种数据可视化工具)为实时感染率分析提供更清晰的洞见。
在结构生物学领域,美国国立卫生研究院(U.S. National Institutes of Health)和德克萨斯大学奥斯汀分校(University of Texas, Austin)正在使用GPU加速软件CryoSPARC和低温电子显微镜重建首个病毒蛋白3D结构。
在治疗领域,NVIDIA与美国国立卫生研究院合作构建了一个AI,该AI可以根据肺部扫描对COVID-19感染进行准确分类,从而制定有效的治疗方案。
在新药研究领域,橡树岭国家实验室在GPU加速的Summit超级计算机上运行了Scripps研究所的AutoDock ,只用了短短12小时对十亿种潜在药物组合进行了筛选。
在机器人技术领域,初创企业Kiwi正在制造自动提供医疗用品的机器人。
在边缘检测领域,Whiteboard Coordinator Inc.建立了一个可以自动测量和筛查人员体温升高的AI系统,每小时可筛查2000多名医护人员。
从以上信息可以看到,面对空前凶残的新冠病毒,各种科技力量迅速团结起来,积极应对。而NVIDIA在其中扮演了“穿针引线”的作用,不管是其GPU硬件产品还是软件产品,NVIDIA在帮助全球应对COVID-19方面尽到了自身的社会责任。
NVIDIA Selene
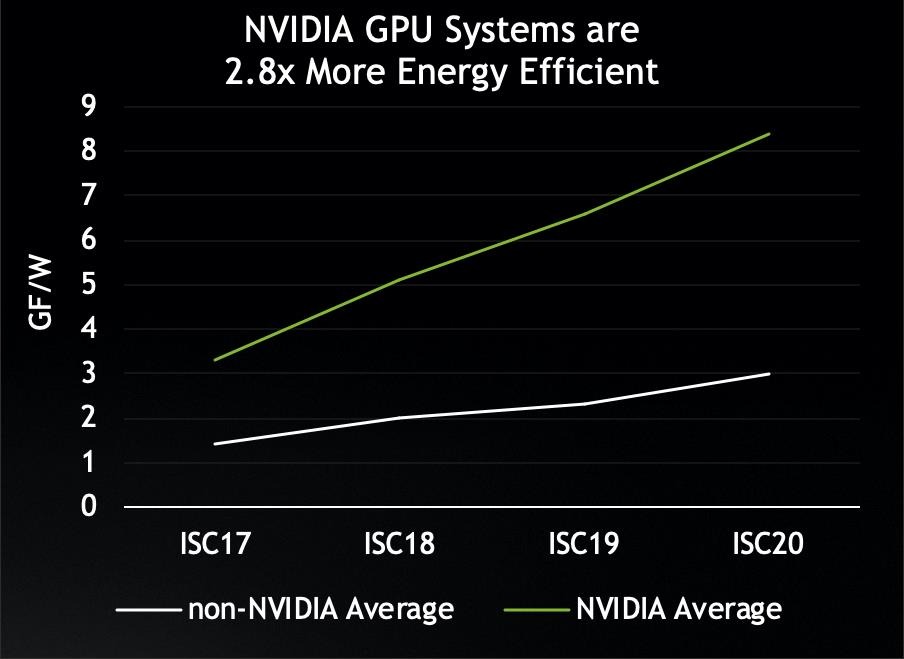
虽然HPC和AI的价值日渐凸显,但是众所周知,HPC是耗电大户,如何优化能耗成为突出的问题,NVIDIA GPU在能耗控制方面做了很多工作。与不使用NVIDIA GPU的系统相比,其能效(以gigaflops/watt为单位)平均高出2.8倍。这也是为何排在TOP500榜单前25的超级计算机中有20台系统都选择采用NVIDIA GPU的原因之一。

在今年的TOP500榜单中,我们看到一个新面孔——Selene,这是NVIDIA内部研究集群的新成员。该系统在Linpack基准测试中以27.5petaflops的性能表现,在最新Green500榜单中排名第二,在整个TOP500榜单中排名第七。
Selene的功耗为20.5gigaflops/watt,与Green500榜单上的第一名相差甚微,但排名第一的系统体积更小,其性能表现仅排在第394位。Selene是排名前100系统中唯一突破20gigaflops/watt能效表现大关的系统,同时也是全球性能排名第二的工业超级计算机。
在能效方面,相比于未使用NVIDIA GPU的其它TOP500系统的平均能效表现,Selene的能效高出了6.8倍。除了出色的能效表现,Selene的快速部署能力也是令人刮目相看。工程师们可以使用NVIDIA的模块化参照架构,在不到四周的时间内就能快速构建Selene。4名操作人员仅需不到1个小时,就能组装起一套由20台系统组成的DGX A100集群,创建出一套性能可以达到2petaflops的系统。
通过添加NVIDIA Mellanox InfiniBand交换机层,工程师将14套分别配置有20台DGX A100系统的模块组的相连接,从而创造出了Selene。Selene系统具有:280台DGX A100系统;2240颗NVIDIA A100 GPU;494台NVIDIA Mellanox Quantum 200G InfiniBand交换机;56TB/s的网络架构;7PB的高性能全闪存。
Selene可以提供超过1exaflops的AI性能。此外,在TPCx-BB关键数据分析基准测试中,其仅使用了16台DGX A100系统就创造了新纪录,其性能表现高出其他系统20倍。Selene之所以有如此上佳表现,这得益于其架构设计和打造的NVIDIA DGX A100系统。
NVIDIA Selene的参考架构其实是NVIDIA的DGX SuperPOD,其基于NVIDIA DGX A100系统。NVIDIA DGX A100在一台6U服务器中集成了8颗A100 GPU以及NVIDIA Mellanox HDR InfiniBand网络技术,可以为高性能计算、数据分析和AI工作(包括训练和推理)等多种组合提供加速,并实现快速部署。
NVIDIA A100
本计划在今年GTC上发布的NVIDIA Ampere架构的GPU由于疫情原因并没有出现GTC Digital上,但是在北京时间5月14日,NVIDIA CEO黄仁勋在其厨房中揭开了NVIDIA A100的神秘面纱。
NVIDIA Ampere GPU采用了7纳米制程工艺,包含超过540亿个晶体管,这样的数据足以令人乍舌。而NVIDIA广泛采用的Tensor Core核心也获得了更新,具有TF32的第三代Tensor Core核心能在无需更改任何代码的情况下,使FP32精度下的AI性能提高多达20倍。此外,Tensor Core核心现在支持FP64精度,相比于前代,其为HPC应用所提供的计算力比之前提高了多达2.5倍。
同时,全新Ampere架构搭载了多实例GPU(MIG)、第三代NVIDIA NVLin、结构化稀疏等技术。其中MIG技术可以将单个A100 GPU分割为多达七个独立的GPU,为不同规模的工作提供不同的计算力,以此实现最佳利用率和投资回报率的最大化。而第三代NVIDIA NVLink使GPU之间的高速联接增加至原来的两倍,实现服务器的高效性能扩展。第三代NVIDIA NVLink互联技术能够将多个A100 GPU合并成一个巨大的GPU来执行更大规模的训练任务。
得益于其诸多创新,NVIDIA A100集合了AI训练和推理,其性能相比于前代产品提升了高达20倍。目前,包括思科、Dell Technologies、HPE、浪潮、联想、Supermicro等已经发布多款内置NVIDIA A100的系统。

为了补充完善上月发布的四卡和八卡NVIDIA HGX A100配置,NVIDIA还发布了PCIe版本的A100。新增的PCIe版本A100使服务器制造商能够为客户提供丰富的产品组合——从内置单个A100 GPU的系统到内置10个或10个以上GPU的服务器等。
据悉,目前有6台在建系统虽然没有出现在此次TOP500榜单中,但它们都采用了NVIDIA于上月发布的A100 GPU。所以可以预计的是在明年的TOP500榜单中,我们将会看到更多搭载NVIDIA A100 GPU的系统。
NVIDIA Mellanox UFM Cyber-AI平台
诚如文章开始所说的,NVIDIA已经开始全面整合Mellanox,相关成果也逐渐问世。例如NVIDIA Mellanox UFM Cyber-AI平台运用AI分析技术检测安全威胁和运行问题并预测网络故障,能够大幅减少InfiniBand数据中心的停机时间。

UFM平台产品系列已管理InfiniBand系统近十年,此次扩展将使用AI学习数据中心的运行节奏和网络工作负载模式。它能根据这一基准追踪系统的运行状况和网络修改并检测性能下降、使用情况和配置文件更改。
该全新平台可发出警报,提示系统和应用异常行为、潜在系统故障以及威胁,并执行纠正措施。它还能在系统遭受黑客攻击,安装恶意应用(例如加密币挖币软件)时发出安全警报。
UFM Cyber-AI平台对UFM Enterprise平台进行了补充。UFM Enterprise平台提供网络监视、管理、性能优化、配置检查和安全电缆管理功能。NVIDIA还发布了UFM系列的第三款产品 —— UFM Telemetry平台。这款工具能够捕获实时网络遥测数据,该数据将被传输到本地或云端数据库,用于监视网络性能和验证网络配置。
NVIDIA在HPC和AI加速计算方面实力雄厚,而Mellanox在网络加速技术方面不容小视。两者的结合将会让计算与网络更加融合,这直接带来的就是突破HPC和AI的瓶颈,实现真正意义上的加速。
重新定义科学计算
如今,AI和分析已成为科学计算中的新需求,AI、数据分析和边缘串流正在重新定义科学计算。NVIDA除了提供丰富的硬件产品外,也在积极发展软件,从而让软硬件更加协同。

这些软件包括CUDA 11;50多个CUDA-X库的新版本;多模式对话式AI服务框架NVIDIA Jarvis;深度推荐应用框架 NVIDIA Merlin;RAPIDS开源数据科学软件库套件;NVIDIA HPC SDK,其中内含编译器、库和软件工具,可最大程度地提高开发者的工作效率以及HPC应用的性能和可移植性。凭借这些功能强大的软件工具,开发者们能够构建并加速HPC、基因组学、5G、数据科学、机器人学等领域的应用。
NVIDIA为700多种HPC应用提速,其中包括所有使用最广泛的科学应用。NVIDIA能够为所有AI框架提速,为科学计算用户在各代架构上的应用提供无缝性能提升,比如从Volta到Ampere等。
在数据分析领域,NVIDIA使用用于数据分析的特定领域CUDA-X库(例如cuDF、cuML和cuGRAPH)以及来自Magnum IO的IO加速技术为Spark3.0、RAPIDS和Dask等关键框架提速,无论这些应用是在数据中心、边缘计算机、超级计算机还是云端。
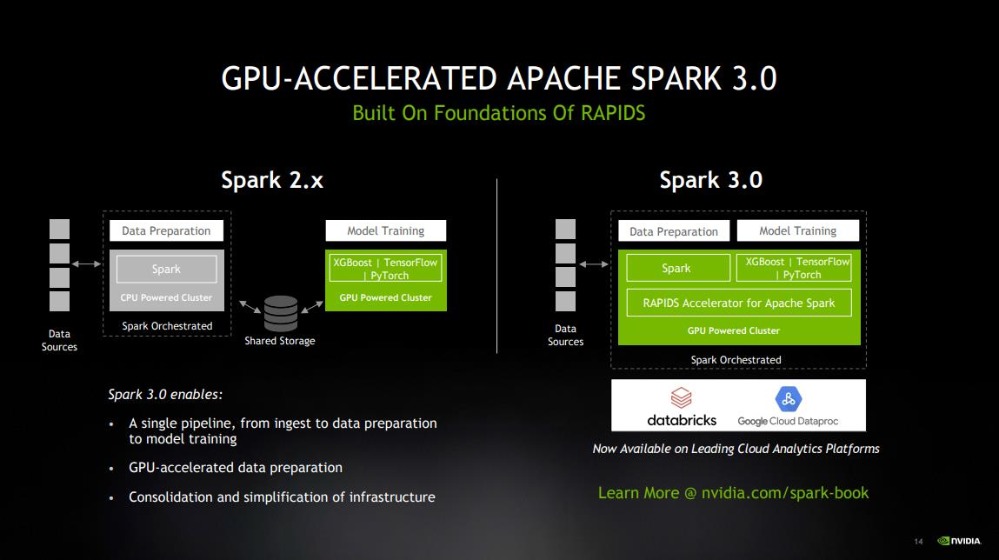
采用RAPIDS开源数据科学软件库套件,并使用由16台NVIDIA DGX A100系统组成的集群,NVIDIA仅用了短短14.5分钟就完成了标准大数据分析基准(TPCx-BB)测试,而目前在CPU系统上运行的记录是4.7小时。
需要特别是指出是今年TOP500榜单的第一名是日本Fugaku超级计算机,而其采用了Arm作为高性能的可行选择。而NVIDIA在去年就已经宣布为Arm处理器架构提供CUDA加速计算软件。
结语
2020年是一个极为特殊的一年,对于HPC市场也是如此。从最新的TOP500榜单,我们可以看到当下HPC发展的新趋势。虽然疫情对于我们的工作和生活造成了很大的影响,但是科技界并没有被病毒吓倒。他们正在联合起来用科技对抗病毒,而以NVIDIA为代表的企业不断赋能科学研究,帮助整个积极应对危机。
好文章,需要你的鼓励

英国NHS无人机快递医疗样本服务正式落地伦敦
英国国家医疗服务(NHS)正将无人机纳入常规医疗物流体系。自今年2月起,无人机每天在雷恩斯公园和圣乔治医院之间运送血液等诊断样本,飞行仅需3分钟,比公路运输快约85%,且碳排放减少高达98%。目前已有逾2000名患者受益。NHS计划将该服务扩展至圣赫利尔、克罗伊登等多家医院,最终惠及约180万名患者。该网络由英国医疗初创公司Apian与谷歌旗下Wing合作运营。

Explyt团队打造的代码智能体评测新标准:光靠“通过/失败“根本不够用
AgentLens是Explyt公司联合俄罗斯学术机构开发的AI编程助手评测基准,通过分析完整人机交互轨迹而非仅看最终结果,从五个维度评估代码智能体的真实表现。

Aetina宣布支持英伟达Jetson T3000和T2000 AI模块
边缘AI计算厂商Aetina宣布,将在其DeviceEdge AIE-KT风冷系列和新款AIE-PT无风扇平台上支持英伟达全新Jetson T3000和T2000模块。T3000基于Blackwell GPU,最高提供865 FP4 TFLOPS算力,功耗70W;T2000则提供400 FP4 TFLOPS,面向视觉AI代理和自主移动机器人等场景。两款模块预计2027年第一季度上市,支持Nemotron、Cosmos 3等英伟达AI软件生态。

机器人的“触觉觉醒“:韩国梨花女子大学如何让小型AI模型在不忘记视觉的前提下学会“感受“材质
韩国梨花女子大学提出Splash框架,通过识别AI模型中的"休眠参数"并只在其中训练触觉能力,让小型多模态AI在学会感知材质触感的同时,完整保留原有视觉语言推理能力。
2020
06/23
11:28
分享
点赞

WAIC2026 现场直击:开普勒顶流人气王,麒麟系列火爆出圈
面壁智能将密度定律带入具身智能
龙磁科技拟投3.58亿元扩建越南永磁铁氧体基地
首创一层Scale-up网络256卡全互联,摩尔线程MTT C256超节点为万卡及十万卡级集群夯实底座
从高血压诊疗入手,北京安贞医院让医疗大模型走出聊天框
西门子肖松:以场景为牵引,推动工业AI从单点实效迈向生产力跃迁
打造Token极致性价比 新华三震撼亮相2026世界人工智能大会
机器人管家系统上线!傅利叶携多款康养陪伴新品方案亮相WAIC 2026
赛那德“ 自主作业机器人天团” 登陆 WAIC:iLoabot-X+模型双升级,秀出具身场景落地硬实力
西门子Eigen工程智能体中国首发首展,荣获2026 WAIC SAIL之星奖
NVIDIA Cosmos 推动物理 AI 前沿发展
PPIO亮相WAIC 2026:发布智能模型网关,打造面向Agent时代的智能Token工厂
NVIDIA Blackwell 现已在云端全面可用
为“代理式AI”装上“护栏” NVIDIA打造“三重防线”
黄仁勋现身北京致辞:60年后,计算机正被重新定义
CES 2025 | NVIDIA Isaac GR00T Blueprint 让人形机器人“加速进化”
未来,就在我们手中
CES 2025 | 代理式AI崛起:NVIDIA定义下一代“代理式 AI Blueprint”
深度学习最佳 GPU,知多少?
NVIDIA推出用于多语言生成式人工智能的NeMo Retriever微服务
NVIDIA 初创加速计划 | 2024 NVIDIA 创业企业展示完美收官!
老黄掏出“迷你版AI超算”,每秒67万亿次运算,仅售2070元人民币
