
Spark SQL性能提升17.7倍是如何实现的?
摘要:在互联网运营商等大规模、超大规模用户中,Spark是最受欢迎的大数据系统,Spark对于内存依赖性很强,所以当负载提高时,硬件平台的内存挑战就会十分明显,浪潮为国内最大的语音识别服务提供商引入了Intel傲腾内存,经过整体优化测试,整体性能提高了17.7倍。
挑战:内存规模限制使 Spark 优势无法充分发挥
Apache Spark是专为大规模数据处理而设计的快速通用的计算引擎,常用来构建大型、低延迟的数据分析应用程序。Spark一个主要特点在于,其能够在内存中进行计算,这使得其数据分析效率往往高于其它计算引擎,但是,服务器内存资源的限制也使得其性能的扩展存在着一定的瓶颈,在超大规模负载中无法充分发挥其利用内存进行计算的性能优势。
某全球领先的语音识别服务提供商是最早将Spark应用到生产环境的团队之一,该公司的语音云通过几千台服务器构成的云计算平台向用户提供多样的、实时语音处理能力,日均服务终端用户超过15亿,日增数据超过100TB。
2014年该公司基于Spark和AI技术构建了DMP大数据平台(用户数据管理平台)。DMP平台的主要功能就是收集、存储、分析和挖掘庞大的用户数据,以实现广告精准投放。
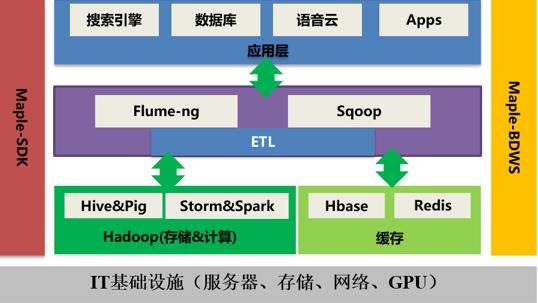
客户业务逻辑结构图
Spark在该公司的大数据平台中主要用于海量用户数据分析,每天支撑稳定运行的Spark SQL统计分析指标和SQL脚本有几千个。但是在将Spark SQL用于海量用户数据分析的过程中,仍然面临着一些痛点,这些都限制了该公司语音云的数据分析能力。
Spark的性能不仅受到CPU、内存、网络、磁盘等硬件设备的制约,而且Spark SQL目前还不支持索引,也严重影响了Spark SQL在进行大规模数据分析时的性能,索引能够提升数据检索的效率,降低硬盘的IO瓶颈;
随着数据量越来越大,即席分析的需求越来越强烈,即席查询是用户根据用户自己的需求,灵活选择查询条件,系统能够根据用户的选择生成响应的统计报表和结果集;在数据仓库和大数据分析系统中,即席查询使用的越多,对系统的性能要求也就越高,如果内存能够缓存更多的热点数据,能够极大的提升即席查询处理速度并降低响应延迟;
数据既有随机读的需求(即席查询-Ad-hoc),又有全表扫描的需求(机器学习);机器学习就是通过特定算法从海量的历史数据中学习规律,从而对新的样本进行分析并对未来做出预测,在模型训练的过程中会产生大量的中间结果数据,通常情况下需要将中间结果数据持久化到文件系统上,如果内存能够缓存更多的中间结果数据,可以提升模型训练的速度;
案例分析:浪潮助力语音云分析能力
随着大数据的技术的逐渐成熟已经数据量的爆发,使得数据分析显得更为重要,互联网用户需要强大的计算性能。作为英特尔的重要战略合作伙伴,浪潮为用户针对互联网、IDC(Internet Data Center)、云计算、企业市场以及电信业务应用等需求,基于全新一代英特尔至强可扩展处理器设计了一款2U 2路机架服务器NF5280M5服务器。该产品满足更多业务对网络带宽、高计算性能、大内存容量的要求,同时对密度和计算性能有较高需求并对存储有一定要求的客户提供了很好的解决方案。
与全新一代英特尔至强可扩展处理器CascadeLake一同上市的英特尔傲腾数据中心级持久内存,可能会很好的解决这个问题,傲腾内存的单设备最大容量达到512GB ,远超DRAM内存的128GB,这使得其可以将系统内存最大扩展至6TB(不包括系统自身内存)。而且,傲腾内存的单位容量价格要远低于DRAM内存,这些特性支持企业在数据中心部署更大、更经济的数据集,在大型内存池中获得新的洞察。
为了解决语音云在Spark SQL数据分析过程中面临的痛点,该公司采用浪潮NF5280M5与傲腾内存,并辅以英特尔OAP软件—优化分析包。OAP旨在为Spark SQL加速Ad-hoc查询。OAP定义了一种新的类Parquet文件列数据存储格式,可以在内存以及傲腾内存中以Fiber为单位提供细粒度的分层缓存机制。更重要的,OAP扩展了Spark SQL DDL,允许用户根据关系定义自定义索引。OAP通过将数据缓存到Executor的堆外内存(傲腾内存)中,加速Ad-hoc。
为了验证傲腾内存在该公司语音云数据分析中的使用效果,我们在实际的方案部署中,选用了浪潮5280M5与傲腾内存的强强组合,分别测试基于傲腾内存/DRAM内存两种配置下的性能对比。我们部署了5台浪潮NF5280M5服务器,其中1台用于Spark的Master节点,另外4台用于Spark的worker节点,每个worker节点部署4根128GB傲腾内存。部署架构如下:
TPC-DS是TPC(事务处理性能委员会)组织发布的一套决策支持系统的性能测试基准,这个基准用于评估服务器的性能。TPC-DS包含一套零售行业的数据模型,采用星型、雪花型等多维数据模型。包含7张事实表,17张维度表,以及99个标准SQL测试案例,每个测试案例几乎都有很高的IO负载或者CPU计算负载,是专门用于评测数据仓库、大数据分析等OLAP系统的基准测试工具之一。该测试集包含了针对大数据集的数据统计、报表生成、联机查询、数据挖掘等复杂的应用,测试数据与真实的商业数据高度相似,可以说TPC-DS是与真实场景非常接近的性能测试基准数据集。目前TPC-DS已经通过了最大100TB数据集规模的性能基准测试。
因此我们选用了TPC-DS大数据基准测试工具,采用了3.5TB的测试数据集,并精选了TPC-DS基准测试工具中与该公司业务场景类似的9个IO密集型SQL测试案例进行评测。测试中浪潮与Intel的工程师在硬件和软件层面进行了大量的优化工作,包括BIOS、操作系统内核、Spark参数的优化;同时Intel工程师针对该公司的实际需求,对OAP软件进行了进一步的优化,以提升Spark在大容量的Parquet文件上创建索引的效率。
从上图中我们看到有两组结果的对比,其实是在我们的测试中进行了两轮测试。第一轮测试模拟DRAM内存和傲腾内存没有缓存任何数据的情况。第二轮测试模拟傲腾内存已经缓存了全部的数据,而DRAM内存因为容量有限只缓存了部分数据的情况。第一轮测试中,因为傲腾内存提供了更大的缓存池,性能有了6倍的提升,在第二轮测试中性能提升更加明显,傲腾内存表现出了17.7X的性能提升(=3452.6/194.28)。
收益分析:
毫无疑问,在浪潮NF5280M5服务器和傲腾内存的共同作用下,内存分析技术无疑给企业和云服务厂商带来了一系列的优势。首先傲腾内存具有大容量、低成本、和持久性存储的特点,可以为企业和云服务厂商降低IT成本、简化基础设施、延长系统和应用的运行时间;同时傲腾内存更靠近CPU,可以与CPU通过内存通道直接进行数据交互,具有高达6.8GB/s的IO带宽和<1us的延时。更重要的是傲腾内存具有超高的随机读写能力,使用傲腾内存用于缓存加速,可以为企业带来巨大的性能提升,帮助企业更快速地获得实时洞察,从而帮助企业创造新的机会,以推动和增强服务的交付能力。
来源:业界供稿
好文章,需要你的鼓励


米拉·穆拉提重返公众视野,谨慎发声
穆拉蒂时隔18个月首次接受重大媒体采访,介绍其创立的Thinking Machines Lab正在开发的"交互模型"。该模型能以200毫秒间隔处理音频、文本和视频流,捕捉人类交流中的中断、修正和停顿。她还谈及OpenAI"政变周"经历,强调行业决策权过于集中的担忧,并回应了公司近期研究人员离职问题,表示这是初创实验室的正常波动。

当AI机器人“自信地“撞向墙壁:STATE16研究院揭示物理AI系统中那些无声无息的致命错误
STATE16研究院这篇综述发现,物理AI系统存在"静默失效"风险——AI以高度自信执行基于错误世界信息的动作,却不触发任何报警,并提出在AI输出与物理执行之间建立独立授权层的框架。

特斯拉疑似删除FSD证据,卡特彼勒加速电动化布局,高压系统技术培训刻不容缓
本期《Quick Charge》播客涵盖多个热点话题:特斯拉疑似试图删除FSD欺诈相关证据以规避巨额赔付;卡特彼勒持续推进建筑领域电气化布局;住宅太阳能30%税收抵免即将到期。此外,嘉宾Tom Pacheco就高压系统与电池技术培训展开探讨,强调电动车技术人才培养的紧迫性。节目同时提醒有意安装太阳能的用户尽快行动,可通过EnergySage平台比较多家安装商报价。

当AI学会“边干边学“:UIUC与微软联合打造的网页智能体训练新范式
UIUC与微软联合研发的OpenWebRL框架让4B小模型仅凭400条初始数据,通过在真实网站上边做边学的强化学习方式,在网页智能体基准上超越了用27万条数据训练的竞争对手。
2019
11/13
19:41
分享
点赞

特斯拉疑似删除FSD证据,卡特彼勒加速电动化布局,高压系统技术培训刻不容缓
智能体网络流量首超真人访问,"死亡互联网"理论引发新争议
Mentium Technologies Luna-R1 AI芯片入选ET-01星座任务,完成多星部署里程碑
汤道生×姚顺雨:腾讯AI下半场,拼的是“模型×产品”系统能力
AI驱动网络犯罪数量飙升,勒索软件受害者年增389%:Fortinet 发布2026年全球威胁态势研究报告
Inbolt将在Automate展会发布视觉驱动机器人编程新功能
笔记本电脑深度清洁指南:内外兼修焕然一新
加利福尼亚州城市通过全美首个由选民投票决定的数据中心禁令
柴油替代方案:AI数据中心如何利用燃气引擎与蒸汽涡轮供电
AI定义汽车时代,车载以太网可靠性面临全新挑战
安全算法的持续更新正变得愈发困难
轨道数据中心本质上是功能强化的卫星
