
IDC:2019年第一季度全球服务器市场收入同比增长4.4%
根据IDC全球服务器季度追踪报告显示,2019年第一季度全球服务器市场厂商收入同比增长4.4%至198亿美元,全球服务器出货量同比下降5.1%至260万台。
2019年第一季度整个服务器市场在经历了连续六个季度的两位数收入增长之后开始放缓,不过增长仍然是比较强劲的。批量出货的服务器收入增长了4.2%,达到167亿美元,中端服务器收入增长30.2%至21亿美元,高端服务器连续第二个季度收入萎缩,同比下降24.7%至9.76亿美元。
IDC基础设施平台和技术研究经理Sebastian Lagana表示:“企业买家和超大规模数据中心通过ODM进行采购的需求相比之前几个季度有所减少,与去年同期进行对比比较困难,这影响了第一季度市场的增长速度。这一点从第一季度出货量的下滑中就能明显看出来,尽管平均销售价格(ASP)同比有所增长,使得很多厂商实现了收入的增长。只要市场对配置丰富的服务器仍然有需求,就可以进一步推动平均销售价格的增长,部分抵消出货量的下滑。”
整体服务器市场厂商排名
2019年第一季度戴尔以20.2%的收入份额位列全球服务器市场第一,其次是HPE/新华三集团,收入份额为17.8%。戴尔的收入同比增长了8.9%,而HPE/新华三集团收入同比增长了0.2%。浪潮/浪潮商用机器、联想和思科并列第三,收入份额分别为6.2%、5.7%和5.3%,收入同比增幅分别为36.4%、3.9%和6.9%。ODM Direct厂商占到了服务器市场总收入的23.0%,同比减少1.0%至45.5亿美元。
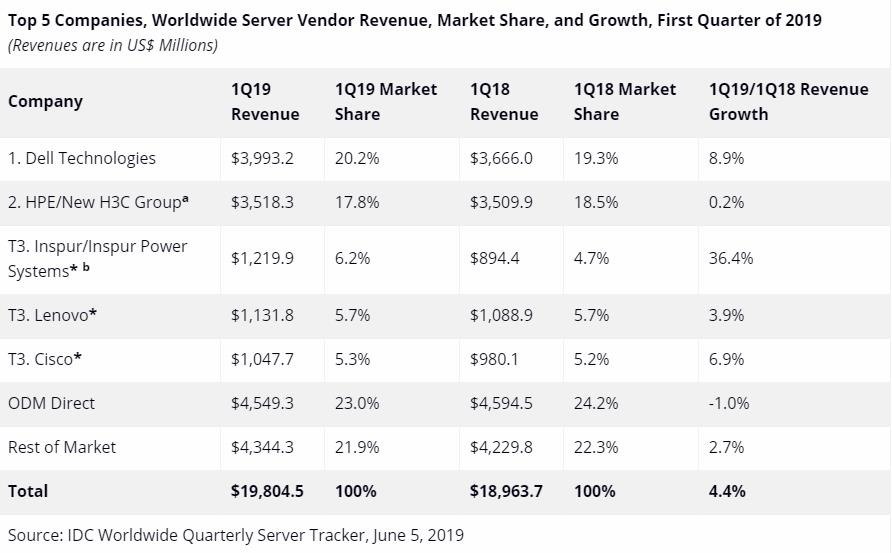
注释:
当全球服务器市场中两家或者更多厂商的收入或者出货量份额小于等于1%的时候,IDC认定这些厂商位于并列位置。
由于HPE和新华三集团现有的合资公司,IDC从 2016年第二季度开始把HPE和新华三集团作为"HPE/新华三集团" 一个整体记录全球市场份额。
由于IBM与浪潮成立了合资公司,所以IDC从2018年第三季度开始将浪潮和浪潮商用机器作为“浪潮/浪潮商用机器”一个整体记录全球市场外部市场份额。

该季度戴尔在出货量方面领先全球服务器市场,占该季度出货量的20.0%。
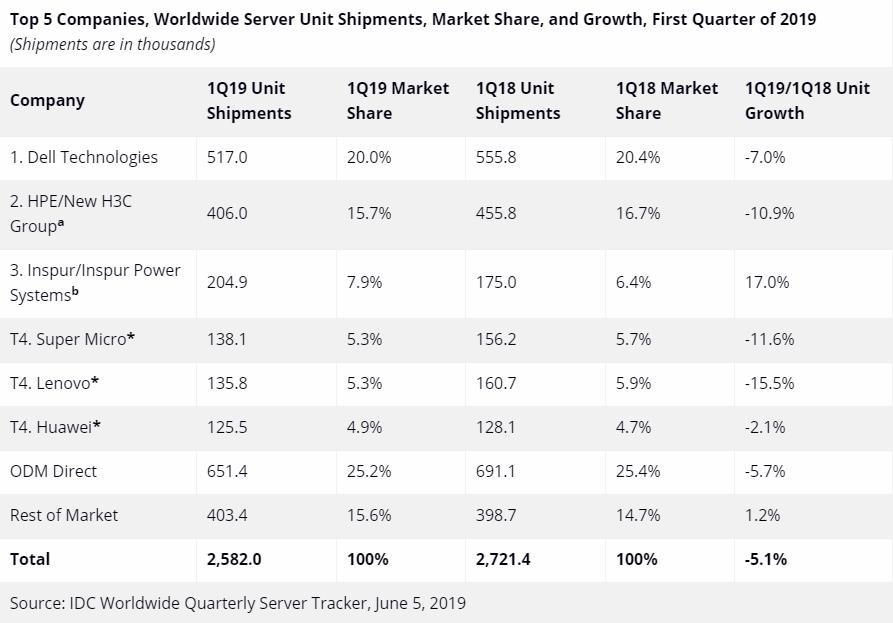
注释:
当全球服务器市场中两家或者更多厂商的收入或者出货量份额小于等于1%的时候,IDC认定这些厂商位于并列位置。
由于HPE和新华三集团现有的合资公司,IDC从 2016年第二季度开始把HPE和新华三集团作为"HPE/新华三集团" 一个整体记录全球市场份额。
由于IBM与浪潮成立了合资公司,所以IDC从2018年第三季度开始将浪潮和浪潮商用机器作为“浪潮/浪潮商用机器”一个整体记录全球市场外部市场份额。
服务器市场亮点
从地区来看,日本是该季度增长最快的地区,收入同比增长9.8%。亚太地区(不包括日本)增长7.4%,欧洲、中东和非洲(EMEA)增长4.1%,美国增长3.5%,加拿大下滑9.6%,拉丁美洲下滑14.9%。该季度中国的厂商收入同比增长了11.4%。
该季度市场对x86服务器的需求增长了6.0%,达到185亿美元,非x86服务器同比减少13.7%至13亿美元。
好文章,需要你的鼓励


美国最高法院裁定地理围栏搜查令须受隐私权保护
美国最高法院以6比3的投票结果,裁定手机位置信息受第四修正案隐私权保护。法院认为,用户在使用谷歌等科技公司服务时,并非主动共享位置数据,因此执法机构在申请地理围栏搜查令时,必须证明存在"合理犯罪嫌疑"并获得法院批准。此裁决虽未完全禁止地理围栏搜查令,但对其使用范围加以限制,对美国执法实践及隐私保护具有深远影响。

南加州大学团队揭示:AI抑郁症检测中藏着一个让准确率虚高23%的“致命漏洞“
南加州大学团队发现语音抑郁检测领域存在数据漏洞,并提出CLeaD跨语言对比对齐框架,揭示模型规模越大跨语言性能越差的反直觉规律。

佛罗里达州勒索软件谈判员因协助黑客勒索美国企业被定罪判刑
佛罗里达州男子Angelo Martino以网络安全公司勒索软件谈判员身份为掩护,与黑客合谋部署BlackCat勒索软件攻击美国企业,被判处逾五年有期徒刑。美国司法部同时没收其逾1000万美元加密货币及资产。Martino与Kevin Martin、Ryan Goldberg三人于2023年联手实施多起攻击,其中一次成功勒索约120万美元后三人平分。BlackCat曾于2024年2月入侵医疗巨头Change Healthcare,导致逾1.92亿人敏感数据外泄。

机械手臂终于学会“看深度“了——KAIST联合POSTECH研究团队让机器人规划与执行真正说同一种语言
KAIST等机构提出3D HAMSTER,通过为视觉语言模型加入深度编码器和几何重建损失,让机器人规划器直接输出三维轨迹,解决了分层机器人系统中规划与执行的维度不匹配问题,显著提升了操作鲁棒性。
2019
06/10
08:27
分享
点赞

Bookshop.org确认今年将推出Kobo电子书阅读器支持
WeWard新增"步行模式":走够步数才能解锁应用
X将通过私信通知用户其互动帖子被社区笔记纠错
"慢社交"应用Roost:让消息像真鸟一样飞行
Truecaller与印度电信监管机构就反垃圾电话规则展开公开交锋
Block与46州达成4500万美元和解,涉Cash App欺诈纠纷
欧盟威胁对Meta开出罚款,剑指Facebook和Instagram上瘾性设计
Disney+考虑推出免费流媒体内容层级
HyperTexting:将开放网络变成类社交媒体信息流的新应用
TV Time关闭之际,创始人打造新追剧应用Bingers
Telegram短链域名t.me因制裁合规问题短暂下线后已恢复
Apple芯片现不可修复漏洞,或成iPhone越狱突破口
