
神州控股旗下因特睿参与项目荣获国家技术发明奖一等奖
2019年1月8日,2018年度国家科学技术奖励大会在人民大会堂隆重召开,北京大学梅宏院士-黄罡教授团队与神州数码控股有限公司旗下北京因特睿软件有限公司(简称“因特睿”)合作完成的“云-端融合的资源反射机制及高效互操作技术”项目,获国家技术发明奖一等奖。北京大学梅宏院士、北京大学教授黄罡、因特睿总经理张颖等参加了颁奖大会。

这是神州控股坚持以数字中国为己任,以自主创新技术的产业化应用驱动发展,积极践行产学研深度融合、协同创新所取得的重大成果。
世界领先技术打破信息孤岛,创新数据价值
打破信息孤岛,实现其业务数据和功能与第三方系统的高效互操作,已成为实施大数据战略的重大需求,也是制约大数据价值链上下游的卡脖子技术。
传统互操作采用“白盒”技术思路,在全面了解信息孤岛内部实现细节的基础上进行二次开发,效率低、成本高、风险难控。该项目提出颠覆式技术途径——“黑盒”思路,揭示信息系统内部基于云-端融合特性的计算反射机理,发明了通过系统客户端外部监测与控制来实现业务数据和功能高效互操作的整套技术及平台,消除了系统源码、数据库表、后台权限、原开发团队等“白盒”依赖,信息孤岛开放效率平均提升2个数量级。
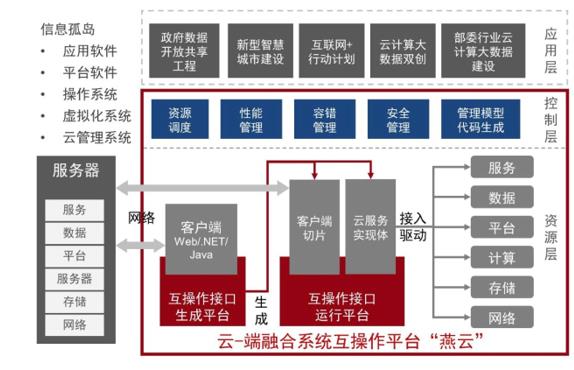
云-端融合系统资源互操作平台“燕云”系统
因特睿作为北京大学系统软件技术成果的转化与创新基地,将该技术成功转化为“燕云DaaS”系列产品,可在数据库封闭、源代码缺失、无原厂支持等情况下,智能生成给定系统的读写接口(API),构建数据和功能“管道”,实现数据的实时流动和功能的无缝集成,解决了制约互联网+政务发展的信息孤岛瓶颈问题,实现了系统的互联互通和数据的交互共享,平均可为用户节省超过90%以上的项目沟通协调时间,缩短50%的项目实施周期。燕云DaaS已经与神州控股等企业联合推出了20多种产品和解决方案。在国家政务信息系统整合共享、国家互联网+政务服务试点、国家安全和国防等重大工程和任务中广泛应用于科技部、工信部、农业农村部等10余个部委和北京、上海、贵州、浙江等20多个省市自治区,累计打破5000多个政务信息孤岛,成为支撑我国大数据产业生态发展的一项共性关键技术。创造了显著的经济社会效益,具有广泛的应用前景。
未来,因特睿将继续加大研发和应用力度,不断提升燕云系列产品的技术水平和应用能力,深入探索能源工业、医疗卫生、教育教学、金融科技等更多领域,为建立自主可控、物理分散、逻辑统一的大数据共享、融合、开放、创新体系提供关键基础平台支撑。
产学研协同创新,加速核心技术转化及产业应用,践行数字中国
谈及此次荣膺国家级大奖,神州控股董事局主席兼首席执行官郭为表示,“神州控股自成立之初便以数字中国为使命,不断以自主创新技术的产业化应用驱动行业发展。除却依托自身技术团队的研发创新之外,神州控股通过与国内外知名高校、科研院所合作,围绕产业需求,开展大数据、云计算、人工智能等新一代技术攻关、项目孵化,在新形势下探索产学研协同创新模式,为技术创新提供源动力,打通科技成果转化‘最后一公里’。为了提升创新技术的产品化和产业化应用,神州控股投资了因特睿,并于2016年成立了‘北京大学—神州控股协同创新中心’,进一步围绕大数据创新技术及在多领域的创新应用进行探索,产学研结合,促进科技创新和科技成果转化。”
作为一家以“数字中国”为使命,致力于以前沿科技赋能行业数字化转型的科技企业,神州控股十分注重核心技术的研发和积累,坚持以创新驱动发展。在从整合IT服务商向大数据服务商升级的征途上,神州控股以资本和科技为驱动,依托大数据、人工智能的核心技术能力,在智慧城市、智慧供应链、智慧金融、智慧医疗、智慧农业、智能制造等行业的关键应用场景上实现了多项突破,成绩斐然。
来源:业界供稿
好文章,需要你的鼓励


Thinking Machines Lab发布能边说边听的AI交互模型
前OpenAI首席技术官Mira Murati创办的AI初创公司Thinking Machines Lab宣布推出"交互模型"技术。不同于现有AI的轮流对话方式,该模型采用"全双工"技术,能在接收输入的同时生成响应,实现类似真实电话通话的自然交互。其模型TML-Interaction-Small响应速度达0.40秒,优于OpenAI和谷歌同类产品。目前仍处于研究预览阶段,计划数月内开放有限测试,年内正式发布。

AI竟然能“感知“自己在扮演谁?香港大学揭开大模型社会角色的隐藏维度
香港大学与哈尔滨工业大学联合发布的这项研究(arXiv:2605.06196)发现,大语言模型在扮演不同社会层级角色时,内部神经网络存在一条清晰的"粒度轴",从普通个人视角延伸至全球机构视角。这条轴是AI角色空间的主导几何方向,可被测量、被跨模型复现,并通过激活引导技术加以操控,为AI社会模拟的可信度评估和角色视角的主动调控提供了新工具。

澳大利亚多州要求数据中心投资风能和太阳能以抵消用电需求
澳大利亚各州及联邦能源部长在近期会议上达成共识,要求数据中心通过投资新建可再生能源和储能设施,完全抵消其电力需求。除昆士兰州外,所有州均支持该提议。联邦能源部长克里斯·鲍文表示,数据中心是新增能源需求的最大驱动力之一,应成为电网的助力而非负担。澳大利亚能源市场委员会将于7月前提交具体实施建议。数据显示,到2030年数据中心用电量预计将增至现在的三倍。

废话也能帮AI变聪明?华盛顿大学研究发现“乱码前缀“让AI推理能力大幅提升
华盛顿大学研究团队发现,在AI数学推理训练中,将随机拼凑的拉丁文占位词(Lorem Ipsum)添加到题目前,能帮助AI突破"全部答错、训练停滞"的困境,在多个模型上平均提升推理得分2.8至6.2分。研究揭示了有效扰动的两个关键特征:使用拉丁语词汇避免语义干扰,以及保持较低困惑度确保AI能正确理解题目内容。
2019
01/09
13:50
分享
点赞

Thinking Machines Lab发布能边说边听的AI交互模型
Opera浏览器支持本地下载运行大语言模型,超150款可选
Unify:帮助开发者找到最适合任务的大语言模型
Human Native AI:打造AI训练数据授权交易市场平台
Converge Bio融资550万美元,打造生物科技大语言模型"全能平台"
ChatGPT语音创造者创业,致力打造现实版"Her"中的AI语音技术
高带宽内存左移测试策略助力AI芯片良率提升
AI加速器测试依赖可测性设计创新
算法将驱动一切:边缘AI智能体如何重塑智能系统
人工智能、物联网与机器人技术在现代制造业中的融合
迪士尼+计划转型为集购票、购物、游戏于一体的"超级应用"
tvOS 26为Apple TV 4K新增五大自定义功能
