
面向数据科学 NVIDIA借助RAPIDS拓展GPU新的应用场景 原创
至顶网服务器频道 10月29日 新闻消息(文/李祥敬):毋庸置疑,我们处于一个数据大爆炸的时代,企业也在数据驱动的策略进行更多业务创新。于是,以分析、深度学习、机器学习为代表的数据科学市场迎来了快速发展发展的机遇期。为了抓住这样的商业机会,NVIDIA针对大规模数据分析和机器学习推出了RAPIDS开源GPU加速平台。
GPU瞄准新的市场
如今 ,虽然业界对于算力的需求不断加大,凭借其强大的并行计算能力,GPU在高性能计算市场表现出色。目前,包括美国Summit、Sierra;日本ABCI;欧洲的Piz Daint在内的诸多全球顶级超级计算机都采用了NVIDIA GPU作为其算力核心。而且,目前已有70%的通用HPC程序已经实现GPU加速。
同时,当前以人工智能为代表的新技术席卷各行各业,而GPU在深度学习方面具有独特的优势,NVIDIA在人工智能市场得到迅猛发展,GPU计算加速了深度学习革命。
NVIDIA亚太区解决方案架构高级总监赵立威告诉记者,整个市场还在持续快速发展,面向数据科学和机器学习的服务器市场每年价值约为200亿美元,加上科学分析和深度学习市场,高性能计算市场总价值大约为360亿美元。
除了数据科学市场,现在零售、金融、医疗等行业也在努力从数据中获得更多价值,也就是我们常说的大数据分析。“其实几乎每一家企业都在用数据驱动来增强自己的核心竞争力,而这离不开所谓的大数据决策支持系统。”赵立威说。
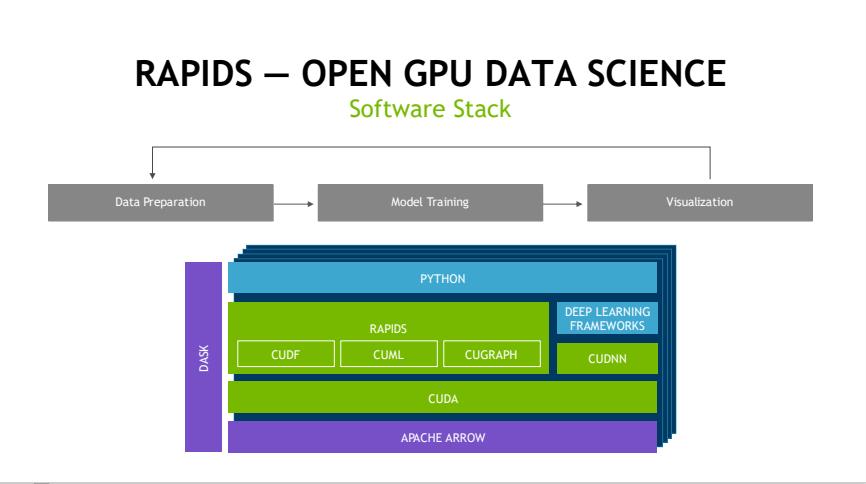
面对广阔的市场机会,NVIDIA GPU将目标瞄准了数据科学和机器学习市场。于是,我们看到了RAPIDS的问世。RAPIDS为GPU加速分析和机器学习提供了一整套开源库,为数据科学家提供了他们需要用来在GPU上运行整个数据科学管线的工具。
RAPIDS加速数据价值实现
赵立威表示,大数据分析一般经过三个步骤,一个是数据准备,这个过程数据特征的提取、数据合并、数据降维等等;第二步,训练。这是一个不断的循环过程,我们要不断优化,进行参数的调整,训练过程精度会更高,可预测的结果会更准确;第三步,推理,上线运营。
在这三个步骤中,业界产生了很多相应的工具,可以加速相应的过程实现。但是这些工具大多是依托处理器的计算,并没有有效利用加速器。于是,NVIDIA通过与开源社区合作,实现了GPU加速数据分析。“GPU可以给数据科学家的机器学习项目提供更多的加速支持。”赵立威说。
最初的RAPIDS基准分析利用了XGBoost机器学习算法在NVIDIA DGX-2系统上进行训练,结果表明,与仅有CPU的系统相比,其速度能加快50倍。这可帮助数据科学家将典型训练时间从数天减少到数小时,或者从数小时减少到数分钟,具体取决于其数据集的规模。
赵立威总结说,在方兴未艾的数据科学领域,RAPIDS具有显著的特点:无缝整合,数据科学家只需要进行非常少的代码修改就可以带来显著的性能加速;可以直接运行在NVIDIA近几年的GPU产品上面;减少数据处理等待时间,数据科学家可以将精力用在模型训练和优化;开源,更好地融入社区,获得更多人的智慧,丰富基础特性,服务更多场景。
据悉,为了推动RAPIDS的广泛应用,NVIDIA正努力将RAPIDS与Apache Spark进行整合,数据可视化将是下一个目标。
广泛的生态系统支持及应用
目前,RAPIDS已经被HPE、IBM、Oracle、Databricks等采用。在Databricks公司,开展的多个项目都在将Spark更好地与本地加速器进行整合,其中包括借助Project Hydrogen实现的Apache Arrow的支持以及GPU调度。
RAPIDS构建于Apache Arrow等流行的开源项目之上,为最流行的Python数据科学工具链带来了GPU提速。得益于CUDA及其全球生态系统以及与开源社区紧密合作,RAPIDS GPU加速平台已与全球最流行的数据科学库及工作流无缝整合,可加速机器学习。如同深度学习一样,GPU正在不断地为端到端的数据科学和机器学习流程提速。
全套RAPIDS开源库现在即可官网上获得,代码经Apache许可公布。容器化RAPIDS版本也可在NVIDIA GPU Cloud container registry上获取。
好文章,需要你的鼓励



南京理工大学、浙江大学、新加坡国立大学联合研究:给机器人装上“双重记忆“,让它真正记住自己在干什么
LaMem-VLA是南京理工大学等三所高校提出的双重记忆机器人框架,通过将短期视觉记忆和长期语义记忆融入模型推理过程,显著提升机器人执行长程任务的成功率。


京东氧气AI商品中台:用千亿规模的AI大脑,让每一件商品都被精准理解
京东氧气AI商品中台(Oxygen AIIC)通过大语言模型与视觉语言模型,构建了覆盖千亿级商品知识资产的全链路生产与服务系统,将商品信息丰富度提升至3.35倍。
2018
10/29
10:00
分享
点赞

面壁智能将密度定律带入具身智能
龙磁科技拟投3.58亿元扩建越南永磁铁氧体基地
首创一层Scale-up网络256卡全互联,摩尔线程MTT C256超节点为万卡及十万卡级集群夯实底座
从高血压诊疗入手,北京安贞医院让医疗大模型走出聊天框
西门子肖松:以场景为牵引,推动工业AI从单点实效迈向生产力跃迁
打造Token极致性价比 新华三震撼亮相2026世界人工智能大会
机器人管家系统上线!傅利叶携多款康养陪伴新品方案亮相WAIC 2026
赛那德“ 自主作业机器人天团” 登陆 WAIC:iLoabot-X+模型双升级,秀出具身场景落地硬实力
西门子Eigen工程智能体中国首发首展,荣获2026 WAIC SAIL之星奖
NVIDIA Cosmos 推动物理 AI 前沿发展
PPIO亮相WAIC 2026:发布智能模型网关,打造面向Agent时代的智能Token工厂
端侧感知、私有闭环、量子协同, NVIDIA全栈异构计算范式“接管”实体产业底座
