
CVPR | NVIDIA宣布推出NVIDIA DALI和NVIDIA nvJPEG
在计算机视觉与模式识别(CVPR)大会上,NVIDIA宣布推出全新的数据增强库和图像解码库。
- NVIDIA DALI:GPU加速的数据增强和图像加载库,可优化深度学习框架的数据管道
- NVIDIA nvJPEG:用于JPEG解码的高性能GPU加速库
基于深度学习的计算机视觉应用程序包括复杂的多阶段预处理数据管道,该管道包括诸多计算密集型步骤,如:从磁盘加载和提取数据、解码、裁剪和调整大小、上色、空间转换和格式转换。
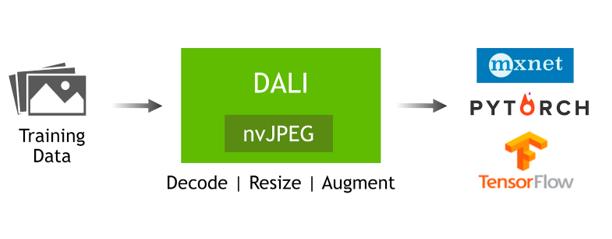
利用GPU加速数据增强,NVIDIA DALI解决了当今计算机视觉深度学习应用的性能瓶颈问题,这些应用程序一般会包括复杂的多阶段数据增强步骤。借助DALI,深度学习研究人员可以在图像分类模型上扩展训练性能,如:具备MXNet的ResNet-50、TensorFlow、适用于所有Amazon Web Services P3 8 GPU实例的PyTorch或带有Volta GPU的DGX-1系统。得益于各框架之间一致的高性能数据加载和增强,框架用户将大大减少代码重复的情况。
DALI依靠全新的NVIDIA nvJPEG库进行高性能的GPU加速解码。nvJPEG支持单一与批量图像的解码、颜色空间转换、多相位解码以及采用CPU和GPU的混合解码。与仅通过CPU的解码相比,采用nvJPEG解码的应用具有更高的吞吐量和更低的延迟率。
DALI的优势包括:
- 能够与面向MxNet、TensorFlow 和PyTorch的直接插件轻松实现框架整合
- 便携式培训工作流程支持多种数据格式,如:JPEG、原始格式、LMDB、RecordIO和TFRecord
- 带有可配置图形和自定义操作符的定制数据管道
- 利用nvJPEG的高性能单一与批量JPEG解码
nvJPEG优势包括:
- 采用CPU和GPU混合解码
- 单一图像和批量图像解码
- 颜色空间转换至RGB、BGR、RGBI、BGRI和YUV
- 单一和多阶段解码
来源:业界供稿
好文章,需要你的鼓励


如何根据工作需求选择合适的戴尔AI笔记本电脑
购买笔记本电脑时,用户现在需要了解Copilot+ PC、NPU和本地AI处理等新概念。搭载专用神经处理单元(NPU)的Copilot+ PC能提供至少40 TOPS的AI算力,支持实时字幕翻译、视频通话优化、AI图像编辑等功能,同时提升续航表现。戴尔最新产品线涵盖多种选择:Dell 14 Plus适合学生和通勤族,Dell 16 Plus适合多任务办公用户,XPS 14面向轻度创作者,XPS 16则以31小时超长续航和3.6磅轻薄机身成为内容创作者的旗舰之选。

上交大&爱丁堡大学联手破解AI“记忆过载“难题:让大模型推理时“记住该记的,忘掉该忘的“
上交大与爱丁堡大学提出InfoKV,将信息熵与注意力权重结合用于KV缓存压缩,让大模型在仅保留12.5%缓存的条件下实现接近甚至超越完整缓存的长推理性能。

微软量子计算突破遭学界质疑,Majorana芯片成果存疑
圣安德鲁斯大学博士Henry Legg在《自然》杂志发表同行评审论文,对微软拓扑间隙协议(TGP)框架提出质疑,认为该框架在推断Majorana粒子量子态存在方面存在缺陷,且实验数据分析结论可能有误。微软此前宣称将于2029年实现可扩展量子计算机,并推出Majorana 2芯片。对此,微软坚持立场,表示已发表正式反驳并获《自然》收录,对研发路线图充满信心。

训练完AI助手,竟然还藏着一把免费的“评分钥匙“?威斯康星大学麦迪逊分校揭秘强化学习的隐藏宝藏
强化学习训练AI时悄悄留下的"进展优势"信号,可作为免费的步骤级评分器,无需额外训练,在多个智能体任务上超越专用奖励模型。
2018
06/25
10:29
分享
点赞

NVIDIA Blackwell 现已在云端全面可用
为“代理式AI”装上“护栏” NVIDIA打造“三重防线”
黄仁勋现身北京致辞:60年后,计算机正被重新定义
CES 2025 | NVIDIA Isaac GR00T Blueprint 让人形机器人“加速进化”
未来,就在我们手中
CES 2025 | 代理式AI崛起:NVIDIA定义下一代“代理式 AI Blueprint”
深度学习最佳 GPU,知多少?
NVIDIA推出用于多语言生成式人工智能的NeMo Retriever微服务
NVIDIA 初创加速计划 | 2024 NVIDIA 创业企业展示完美收官!
老黄掏出“迷你版AI超算”,每秒67万亿次运算,仅售2070元人民币
