
Nvidia与NetApp合作打造深度学习GPU服务器芯片
NetApp和Nvidia已经推出了一个组合式的AI参考架构系统,与Pure Storage和Nvidia 合作的AIRI系统相竞争。
这款系统主要针对深度学习,与FlexPod(思科和NetApp合作的融合基础设施)不同,这款系统没有品牌名称。而且与AIRI不同的是,它也没有自己的机箱封装。
NetApp和Nvidia技术白皮书《针对实际深度学习用例的可扩展AI基础设施设计》定义了一个针对NetApp A800全闪存存储阵列和Nvidia DGX-1 GPU服务器系统的参考架构(RA)。此外还有一个速度慢一些的,成本更低的、基于A700阵列的参考架构。
高配的参考架构支持单个A800阵列(高可用性配对配置),5个DGX-1 GPU服务器,连接2个思科Nexus 100GbitE交换机。速度较慢的A700全闪存阵列参考架构支持4个DGX-1和40GbitE。
A800系统通过100GbitE链路连接到DGX-1,支持RDMA作为集群互连。A800可横向扩展为24节点集群和74.8PB容量。
据说A800系统可实现25GB /秒的读取带宽和低于500微秒的延迟。
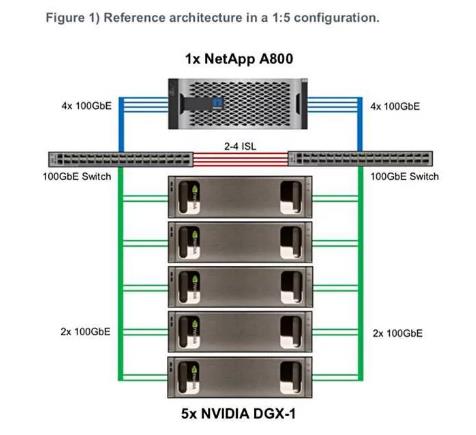
NetApp Nvidia DL参考架构配置图
Pure Storage和Nvidia的AIRI有一个FlashBlade阵列,支持4个DGX-1。FlashBlade阵列提供17GB /秒的速度,低于3毫秒的延迟。这与NetApp和Nvidia合作的参考架构系统相比似乎较慢,但A800是NetApp最快的全闪存阵列,而Pure的FlashBlade则更多地是一款容量优化型闪存阵列。
和Pure AIRI Mini一样,NetApp Nvidia DL RA可以从1个DGX-1起步,扩展到5个。 A800的原始容量通常为364.8TB,Pure的AIRI原始闪存容量为533TB。
AIRI RA配置图如下所示:
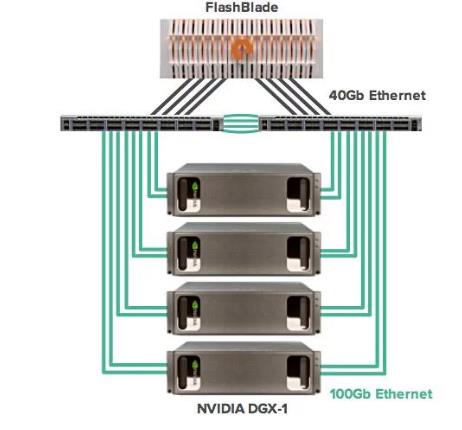
Pure Nvidia AIRI配置图
NetApp和Pure都对他们的这两个系统进行了基准测试,并且都包含Res-152和ResNet-50运行使用合成数据、NFS和64批量大小。
NetApp提供了图表和数据,而Pure只提供图表,所以对比起来有点困难。不过,我们可以通过将这些图表放在一起做个粗略的估计。
合成的总图表并不漂亮,不过确实提供了一些对比:

NetApp和Pure Resnet性能对比
至少从这些图表可以看出,NetApp Nvidia RA的性能优于AIRI,但让我们吃惊的是,由于NetApp/Nvidia DL系统与Pure AIRI系统相比具有更高的带宽和更低的延迟,分别是25GB/s的读取带宽和低于500微秒以下,后者分别17GB/s和低于3毫秒。
价格对比很好,但没有人透露给我们这方面的数据。我们猜测Nvidia可能会宣布更多深度学习方面的合作伙伴关系,就像NetApp和Pure这样的。HPE和IBM都是很明显的候选对象,还有像Apeiron、E8和Excelero等NVMe-oF这样的新兴阵列初创公司。
好文章,需要你的鼓励


星际之门AI数据中心建设雄心遭遇现实挑战
2025年1月,OpenAI、软银、甲骨文和MGX联合宣布"星际之门"计划,承诺投资5000亿美元,部署高达10GW算力基础设施。如今,该项目已从白宫发布会上的宏大承诺,演变为一场前所未有规模的基础设施建设实验。项目已扩展至德克萨斯、威斯康星、俄亥俄等多地,并延伸至阿布扎比和挪威。然而,融资争议、合作伙伴摩擦、能源压力及政策监管收紧,正考验着这一"AI工业园"模式能否真正落地。

阿里巴巴让AI图像生成模型“自我进化“:Qwen-Image-2.0-RL是如何让机器学会审美的?
阿里Qwen团队通过引入强化学习和在线策略蒸馏,将Qwen-Image-2.0升级为Qwen-Image-2.0-RL,让图像生成模型真正学会人类审美,文生图Elo评分提升78分,图像编辑提升93分。

OKX推出AI智能体招聘与支付市场平台
加密货币交易所OKX正式推出AI智能体交易市场OKX AI,允许AI代理相互雇佣、自主结算,并建立基于区块链的可携带信誉档案。该平台经过50家早期服务商封测后向开发者开放,依托稳定币和链上支付基础设施,支持全天候微支付。OKX创始人徐明星表示,传统金融基础设施为人类而建,智能体经济需要为自主软件专门设计的基础设施。

港科大联手快手,让AI画图“减减肥“:一个让图像生成更真实的小技巧
港科大与快手联合提出NormGuard,针对流匹配模型强化学习训练中速度范数膨胀问题,通过训练时单向惩罚约束,在保留奖励的同时改善图像真实感。
2018
06/07
07:35
分享
点赞

星际之门AI数据中心建设雄心遭遇现实挑战
OKX推出AI智能体招聘与支付市场平台
AI编程Token成本将与开发者薪资持平,企业如何应对?
机器学习项目全生命周期管理的成功实践
SVT Robotics的Softbot平台交易量突破40亿笔
Agibot第15000台人形机器人下线,具身AI量产加速
杜尔为大众汽车建设跨工厂集成CO?高效涂装车间
AI对就业的影响:大规模裁员背后的真相与数据
AI重复申请问题推动电网转向"承诺优先"规划
美国消费品安全委员会拟出台电动自行车电池安全新规
江波龙:建设完成mSSD月产能百万交付能力!mSSD高速存储介质赋能端侧AI规模应用
从IO500双榜第一,看国产存储的系统级突破
