
强化敏捷与大规模交付 浪潮海外首发InCloud OpenStack 5.5
当地时间,5月21日,浪潮在2018 OpenStack温哥华峰会上正式发布全新InCloud OpenStack 5.5,融合最新的容器技术实现了OpenStack的容器化部署,在规模化部署、简单易用和智能化运维上带来更出色的表现,帮助全球云计算用户更好的构建先进的云基础设施。
此次InCloud OpenStack 5.5海外首发,OpenStack基金会执行总裁Jonathan受邀出席了本次新品发布会,并对新品和浪潮在社区的贡献给予了高度认可。Jonathan表示:作为OpenStack基金会黄金会员的浪潮,对于OpenStack 的贡献在逐年增加,有很多来自浪潮的专家投入到OpenStack中,为数十个的不同项目做出了贡献,浪潮从市场和技术两个维度都为OpenStack做出了很大贡献。
在云计算已成为智慧时代基础设施的当下,浪潮通过与自身服务器、存储产品体系的深度融合,凭借完整的计算虚拟化、软件定义存储、软件定义网络产品体系及整体交付能力,致力于为用户交付敏捷、开放、融合、安全的软硬一体化云基础设施。
峰会现场,浪潮集团副总裁Jay Zhang出席InCloud OpenStack 5.5发布仪式并发表精彩演讲,据Jay Zhang介绍:最新发布的产品更加强调敏捷交付与大规模部署,可满足行业用户对于大规模部署稳定运行、智能化运维、两地三中心等诉求,进一步显示出浪潮持续优化InCloud OpenStack原生产品的创新能力,以及基于行业实践和面向未来的技术发展洞察。
简单易用:一键式容器化部署,资源图形化编排
InCloud OpenStack在安装部署方面,基于容器化技术封装各个组件为独立于宿主操作系统的容器化镜像,依靠统一分发实现一键式批量部署。基于数据可视化组件,实现服务编排可视化拖拽,可基于系统模板或自定义拖拽创建编排模板,通过所见即所得的方式完成资源的编排,提升用户友好度。
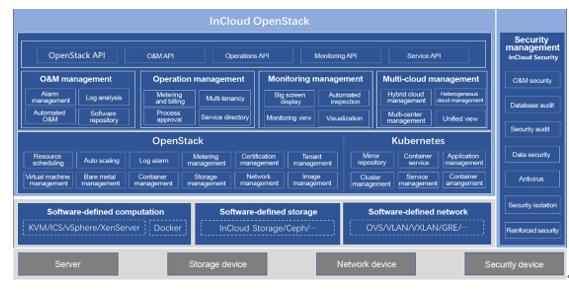
InCloud OpenStack 5.5架构图
云管理:虚拟机、裸机、容器的统一管理
InCloud OpenStack 5.5基于OpenStack架构实现了虚拟机、裸机、容器三种计算资源的同平台统一管理和对外提供服务,进行三种资源的并行调度,实现集计算、存储和网络资源的融合共享,降低运维与管理成本。
针对虚拟机服务支持自定义RAID、支持多租户、裸金属与VPC内的虚拟机互通等,有效提升系统性能及灵活性。针对容器高效部署和管理K8S集群,支持容器应用的自动化部署、容器镜像管理、服务目录管理、监控和弹性伸缩以及容器的持久化存储等功能。
单集群1000+节点大规模交付能力
目前,随着稳定性、易用性以及集成友好度的显著提升,OpenStack从测试环境到生产环境的转变速度越来越快,但大规模部署依然对OpenStack的管理及稳定运行带来挑战。浪潮InCloud OpenStack 5.5为了满足大规模数据中心交付能力,从两个维度对原生OpenStack产品进行了优化。一方面,采用多Region方式实现大集群的分而治之,所有的Region使用一套Keystone系统,解决因集群规模扩大而带来keystone系统瓶颈,从独立部署Keystone和Token认证两个维度进行优化;另一方面,为了增加单Region的集群规模,采用分离方案对数据库、消息通信机制进行优化,使得单集群规模大于1000+节点。
两地三中心容灾能力
InCloud OpenStack 两地三中心方案可对外提供同城150KM双中心双活,异地数据中心主备的容灾能力;方案采用浪潮自研的网络设备、集中式存储设备和云管理平台可以从数据、网络、业务层面稳定高效的保证客户业务连续性。该方案可以有效的帮助客户节约成本、提高业务高可靠、采用可视化一键式故障切换方案实现高效故障管理等能力。
目前,基于InCloud OpenStack 5.5的“两地三中心”云数据中心解决方案已成功交付,帮助客户构建起单集群超过1000节点、总规模达1400+节点的全球领先云基础设施。
好文章,需要你的鼓励


Uber年度遗失物报告揭示:数千件物品遗留在无人驾驶出租车中
Uber年度失物报告首次纳入无人驾驶出租车数据。过去一年,乘客在Uber平台的机器人出租车中遗留了数千件物品,包括手机、钥匙、钱包等常见物品,以及假牙、15磅溜溜球等奇特物件。乘客可通过App联系客服找回失物,支付15美元即可享受同城配送,或前往车辆停放站自取。Uber表示,将依托现有运营体系为自动驾驶业务提供全面支持,计划2025年底前在全球15座城市开通无人驾驶打车服务。

当AI学生卡在难题前:LinkedIn等机构如何让AI通过“偷师学艺“突破学习瓶颈
TREK方法通过引入外部验证解法对AI进行短期校准,解决了GRPO训练在困难题目上因无法探索正确解法区域而陷入瓶颈的问题,在数学推理和智能体任务上均取得明显提升。

Uber今年将部署500辆数据采集车辆,助力自动驾驶发展
Uber周三发布了一款基于现代Ioniq 5改装的数据采集原型车,搭载14个摄像头、8个固态激光雷达和9个雷达,通过英伟达双驱Thor计算机处理数据。Uber计划今年在全球部署500辆此类车辆,每月可采集200万英里高保真驾驶数据,供Avride、Waymo、WeRide等30余家自动驾驶合作伙伴使用。这是Uber自2020年出售自动驾驶部门以来首次自主组装车辆,也是其AV Labs部门的重要进展。

LMMs-Lab与NTU MMLab联手微软:让AI智能体“一句话自我进化“的秘密
SkillOpt-Lite通过将智能体技能优化形式化为零阶优化问题,提出极简流水线:把执行轨迹存为文本文件,让AI直接用文件系统工具翻日志、找规律、改技能,配合独立验证门控,比复杂的多智能体优化框架跑得更快效果更好,并自然延伸至执行框架自动优化(HarnessOpt),使轻量模型能够超越大模型。
2018
05/24
14:01
分享
点赞

Uber年度遗失物报告揭示:数千件物品遗留在无人驾驶出租车中
Uber今年将部署500辆数据采集车辆,助力自动驾驶发展
Uber、Wayve与Waymo的伦敦无人驾驶出租车大战即将开启
Mobileye计划2027年在美国推出自动驾驶出租车服务
Waymo召回近4000辆无人出租车,原因是其进入高速公路施工区域
特斯拉在奥斯汀开始测试无方向盘无踏板Cybercab量产版
图灵奖得主Patterson:摩尔定律的真相,CPU、GPU、TPU的诞生与分工
Omdia报告:Dell PowerProtect助力企业三年期网络弹性TCO最高降低61%
“驯服”千亿模型,鏖战“黑猴打瓦”,龙虾“一键接管” ,锐龙AI Max+ 395开启全能桌面AI主机“王炸”时刻
豪声电子泰国电声工厂初步投产:2500万泰铢项目进入产能爬坡
地瓜机器人将560TOPS端侧算力,加载到了20+头部团队机器人中
WAIC 2026主论坛(下午场)重磅揭晓!
