
Nvidia GPU云延伸至高性能计算应用领域 原创
有超过500个高性能计算应用都采用了GPU加速,Nvidia把目标对准了让这些应用更易于访问。
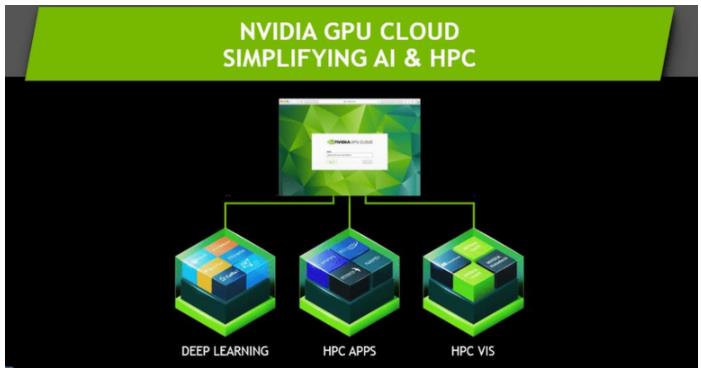
Nvidia开始涉足融合GPU加速的大量高性能计算(HPC)应用,本周一宣布在Nvidia GPU Cloud (NGC)容器注册表中增加了新的软件和工具,可以让科学家们快速部署科学计算应用和HPC可视化工具,
通常,希望使用这些应用的科学家们面临着耗费大量时间的安装问题以及资源密集的升级过程。现在,访问这些应用就像“从苹果应用商店下载一款应用一样简单”,Nvidia公司副总裁、加速计算总经理Ian Buck表示。
任何持有NGC帐户的人,都可以从NGC容器注册表获得HPC应用和HPC可视化容器。HPC容器可以运行在任何Nvidia Pascal和下一代Nvidia GPU加速的系统上。
Nvidia在丹佛举行的SuperComputing17大会上公布了这些工具,展示Nvidia正在越来越多地涉足高性能计算领域。
目前,已经有超过500个HPC应用是GPU加速的。来自分析师公司Interesect360 Research的报告,这其中包括TOP15以及70%的TOP50 HPC应用。从天文学到生命科学和医疗成像,GPU加速应用正在被用于广泛的科学领域,但是却难以安装。
Buck解释说:“这些应用是从很多不同的软件堆栈和库之上进行开发的,是由研究人员为他们自己开发的,而不一定是为大众发布开发的——这并不是他们的首要任务。”
Nvidia在深度学习和云社区领域解决了相同的问题,上个月,Nvidia发布了GPU Cloud for AI开发者工具,现在该工具已经成为容器注册表的一部分。
就NGC中的HPC应用来说,Nvidia是从小范围起步的,主要有5个应用:GAMESS、GROMACS、LAMMPS、NAMD和RELION,未来还有更多。
与此同时,在HPC可视化方面,Nvidia与ParaView合作推出了三个容器现在正处于测试阶段:ParaView with Nvidia IndeX是针对可视化大规模批量数据的;ParaView with Nvidia Optix是针对光线追踪的;Nvidia Holodeck则提供了交互式的实时可视化和高质量视觉效果。
本周一Nvidia还宣布基于Nvidia Volta架构的Tesla V100 GPU现在已经通过所有主流服务器厂商和主流云服务提供商提供,以交付人工智能和高性能计算,服务器厂商包括Dell EMC、HPE、华为、IBM和联想,云服务提供商包括阿里云、AWS、百度云、微软Azure、Oracle Cloud和腾讯云。
好文章,需要你的鼓励


OpenAI在版权诉讼中疑因隐瞒证据遭遇重大危机
OpenAI在与多家新闻机构的版权诉讼中陷入困境。以《纽约时报》为首的原告指控OpenAI在长达两年时间里向法庭撒谎,刻意隐瞒其已对ChatGPT日志进行大规模搜索的事实。据悉,OpenAI实际上已拥有包含1000万和7800万条记录的日志样本,并曾用于研究版权内容过滤器,却对外声称无法进行此类搜索。原告据此提出制裁动议,要求法院追责。OpenAI则否认相关指控,坚称其立场基于合理使用原则。

当AI学会“挑剔“:斯坦福与伯克利联手打造的智能验证框架,让AI自己检验自己的答案
斯坦福与UC伯克利提出LLM-as-a-Verifier框架,通过提取AI模型内部概率分布生成连续评分,在代码、机器人、医疗领域均达到最优性能,且无需额外训练。

外科医生远程操控人形机器人,完成全球首例活猪手术
美国加州大学圣地亚哥分校研究团队在《自然》期刊发表研究成果:外科医生通过远程操控宇树G1仿人机器人,成功完成两例活体猪胆囊切除手术,创下全球首例。与造价数十至数百万美元的达芬奇手术机器人相比,仿人机器人成本更低、体积更小,未来有望部署于农村、战地乃至太空等资源匮乏的医疗场景。但目前仍存在需频繁重新校准、机械臂活动范围受限等挑战。

字节跳动Seed团队发现:AI智能体学习新任务的速度,正以每三个月翻倍的惊人节奏增长
字节跳动Seed团队发现AI智能体在真实环境中学习的进步曲线精确遵循对数S形规律,R?达0.998,且前沿模型的学习速度每三个月翻倍。
2017
11/14
15:48
分享
点赞

OpenAI在版权诉讼中疑因隐瞒证据遭遇重大危机
外科医生远程操控人形机器人,完成全球首例活猪手术
OpenAI发布ChatGPT Work:AI助手可连续工作数小时
欧盟向Meta施压:关闭自动播放和无限滚动,否则面临巨额罚款
世界模型的潜力与局限:它真的能模拟一切吗?
苹果起诉OpenAI:前员工利用系统漏洞窃取商业机密
如何利用开源AI智能体实现工作流程自动化
Cloudzy 云服务评测:VPS 性能与体验全面解析
这款PCIe插卡内置38核至强处理器与64GB内存,堪称完整服务器
是否该为企业招募数字员工?AI 智能体团队搭建全指南
AI赋能自主机器人:从工厂走向家庭的未来图景
数据中心能源需求威胁特朗普"美国制造"计划
