
京东如何处理数据中心网络对于应用性能的影响
随着现代数据中心规模的不断扩张,网络拓扑和路由转发变得越来越复杂。传统的数据中心使用大型机和小型机,网络规模相对较小,普通的机框式交换机就能满足网络的需求。随着CLOS集群架构的普及,标准的x86服务器集群以低成本和高扩展性逐渐取代大型机和小型机而成为数据中心的主流。
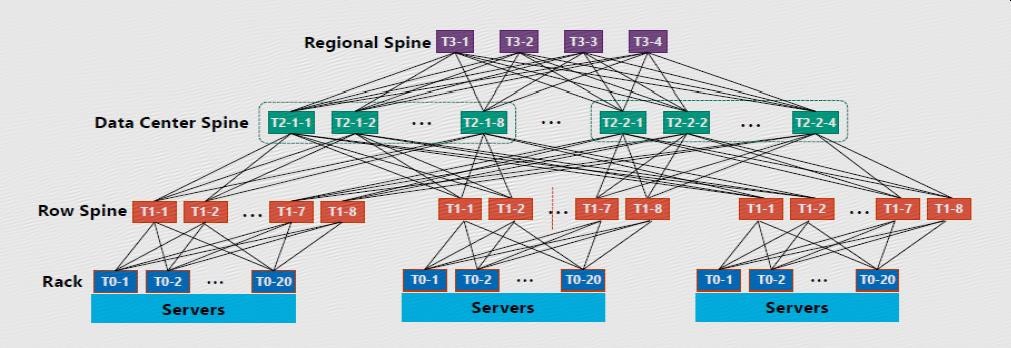
下图就是一个典型的基于CLOS架构的数据中心解决方案,在这样的大规模网络中,如何让数据在传输过程中能以最快的速度从发送端到接收端,成为网络性能调优的关键因素。
京东IT资源服务部举办的未来数据中心核心技术研讨会上,京东人工智能,大数据,云计算团队的多位研发总监,技术骨干人员,针对网络影响应用性能的话题,展开了深入的讨论。
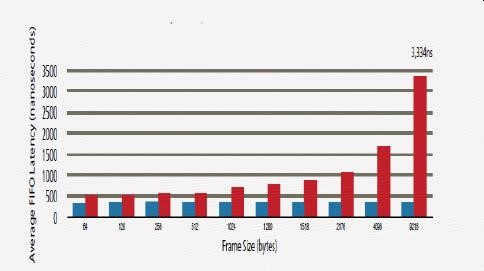
网络影响应用性能的一个原因,是处理器的性能越来越高,应用到应用之间,点对点延迟越来越低。比如在高性能计算和AI应用中用到的MPI 协议,点对点传输的延迟可以小于1微秒(1us), 而现在多数交换机的单个Hop延迟超过了3微秒。
从上面那张拓扑图中可以看到,同一数据中心需要经过5个Hop(从Rack ToR到Row Spine,到Data Center Spine,再到Row Spine,到Rack ToR),这需要消耗15微秒的延迟。1微秒比15微秒,在运行应用的过程中超过90%的时间消耗到了网络上,这种情形还不包括网络上有任何丢包导致的重传。
如何减小网络对于应用性能的影响
1、采用高性能的交换机
如果交换机的性能能从3微秒降低到0.3微秒,这样的话,整个网络的延时会降低到原来的十分之一。
2、采用性能高而且稳定的交换机
有的交换机转发性能不稳定,在不同的包大小情况下,会有不同的转发性能,在小包的情况下可以有低的延迟,在大包的情况下延迟会大幅增加,导致网络性能不可预测。有的交换机转发性能可以不随着包大小的变化而波动,一直维持在低延迟的状态。
3、避免出现多对一通讯时的不公平现象
如果出现这种不公平现象,会导致网络转发速度不均,出现先到后得的现象。

4、建立快速的网络拥塞控制机制
在大型的网络中,拥塞是不可避免的,如何能有效的管理拥塞和降低拥塞带来的丢包和重传,是现在网络管理中非常重要的一个技术难点。
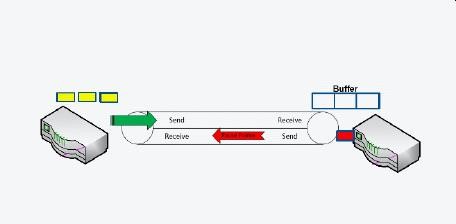
5、降速慢传数据策略优于丢包重传数据
在网络中,降速慢传和丢包重传是两种被用来解决拥塞的方式,实践证明,慢传比丢包重传更能有效的解决拥塞问题。
对网络拥塞的管理和控制
通过研讨会上的讨论我们可以发现,应用的属性决定了网络中的通讯方式,如存储应用中的多个initiator访问单个或多个target,MPI应用中的多对多通讯,machine learning中的worker和parameter server通讯,CDN中的一对多通讯等。
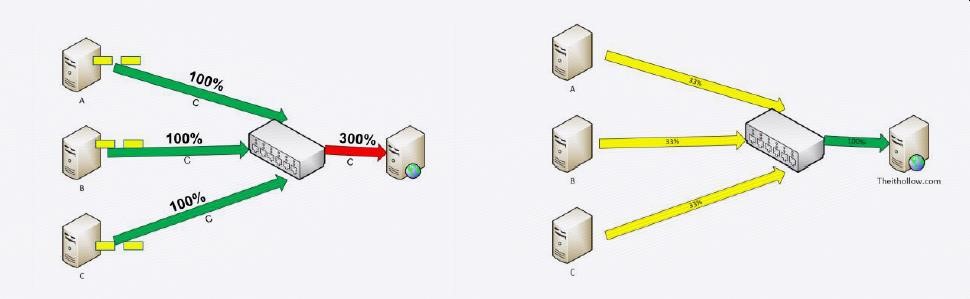
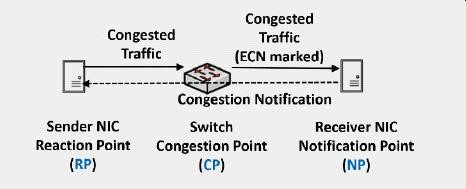
当多对一的情况发生时,为了减少丢包导致的重传,我们需要采取措施来降低发送端的速度,来减少对交换机buffer的压力。在网络的拥塞管理和控制上,业界通常采用PFC(Priority based Flow Control)和ECN(Explicit Congestion Notification)两种方式来实现。
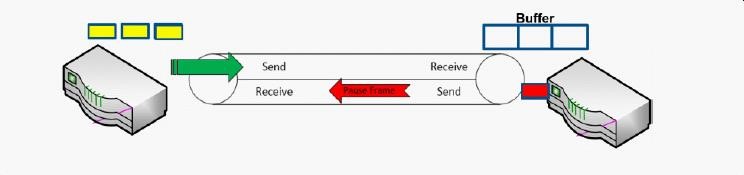
1、PFC 是在交换机入口(ingress port)发起的拥塞管理机制
在通常无拥塞情况下,交换机的入口buffer不需要存储数据。当交换机出口(egress port)的buffer达到一定的阈值时,交换机的入口buffer开始积累,当入口buffer达到我们设定的阈值时,交换机入口开始主动的迫使它的上级端口降速。由于PFC是基于优先级的控制,所以这种反压可能导致同样优先级的应用受到影响。
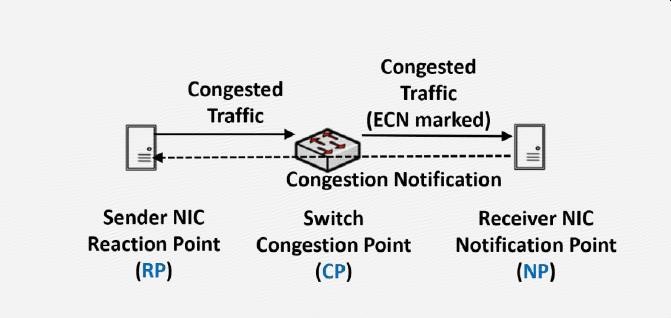
2、ECN是在交换机出口(egress port)发起的拥塞控制机制
当交换机的出口buffer达到设定的阈值时,交换机会改变数据包头中的ECN位来给数据打上ECN标签,当带ECN标签的数据到达接收端以后,接收端会生成CNP(Congestion Notification Packet)并将它发送给发送端,CNP包含了导致拥塞的flow或QP的信息,当接收端收到CNP后,会采取措施降低发送速度。
可见ECN是基于TCP flow或RDMA QP的拥塞控制机制,它只对导致拥塞的flow或QP起作用,不会影响到其他的应用。
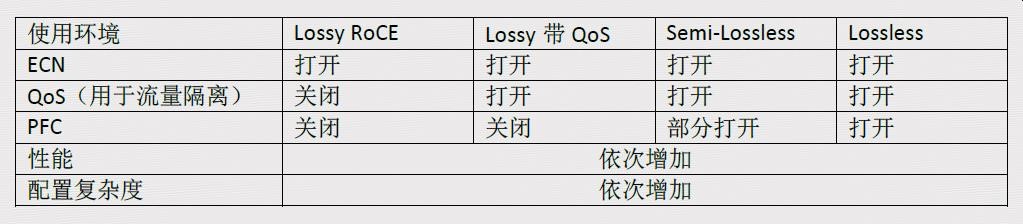
京东IT资源服务部的硬件系统部技术负责人王中平提出:在管理网络的拥塞中,应该综合应用PFC 和ECN 两种方式,来有效的实现性能和操作性的平衡。具体的实施过程中可参考以下推荐:
京东IT资源服务部负责人吕科说:“如何降低网络对于应用性能的影响是一个非常复杂的问题,也是所有的数据中心管理者一直在力求解决的问题。最好的方式就是我们的网络人员和应用人员一起来讨论应用对于网络的需求,我们专业的技术团队会针对需求,测试和选择最合适的网络产品和网络方案。”
好文章,需要你的鼓励


图灵奖得主Patterson:摩尔定律的真相,CPU、GPU、TPU的诞生与分工
2026年7月13日,软件工程师Ryan Peterman在他的播客The Peterman Pod上发布了一期与David Patterson的长对话。

NVIDIA推出“三模式“AI语言大脑:一个模型同时兼顾速度与准确,彻底打破现有推理瓶颈
英伟达推出Nemotron-Labs-Diffusion三模式语言模型,将逐字生成、并行扩散与自猜自验融于一体,单用户吞吐量最高达Qwen3-8B的4倍,同时保持相近准确率。

豪声电子泰国电声工厂初步投产:2500万泰铢项目进入产能爬坡
今天讲的出海案例是生产微型扬声器、受话器和音响产品的豪声电子,其计划投资2500万泰铢的泰国音响类电声工厂已经进入初步投产阶段。

华东师范大学等多家机构联合出手:让机器人训练数据“少而精“,原来靠这个秘密武器
SIEVE是一种面向机器人模仿学习的数据筛选方法,通过发现可复用行为原语和转换接口,用50%数据和训练量超越全量训练效果。
2017
08/21
15:12
分享
点赞

Uber今年将部署500辆数据采集车辆,助力自动驾驶发展
Uber、Wayve与Waymo的伦敦无人驾驶出租车大战即将开启
Mobileye计划2027年在美国推出自动驾驶出租车服务
Waymo召回近4000辆无人出租车,原因是其进入高速公路施工区域
特斯拉在奥斯汀开始测试无方向盘无踏板Cybercab量产版
图灵奖得主Patterson:摩尔定律的真相,CPU、GPU、TPU的诞生与分工
Omdia报告:Dell PowerProtect助力企业三年期网络弹性TCO最高降低61%
“驯服”千亿模型,鏖战“黑猴打瓦”,龙虾“一键接管” ,锐龙AI Max+ 395开启全能桌面AI主机“王炸”时刻
豪声电子泰国电声工厂初步投产:2500万泰铢项目进入产能爬坡
地瓜机器人将560TOPS端侧算力,加载到了20+头部团队机器人中
WAIC 2026主论坛(下午场)重磅揭晓!
AI评测初创公司Braintrust遭入侵,敦促所有客户轮换API密钥
