
全球超级计算机500强:美国三甲不入 原创
至顶网服务器频道 06月20日 新闻消息: 瑞士的Cray系统现在成了世界超级计算机的老三,位于两台中国超级计算机后面。
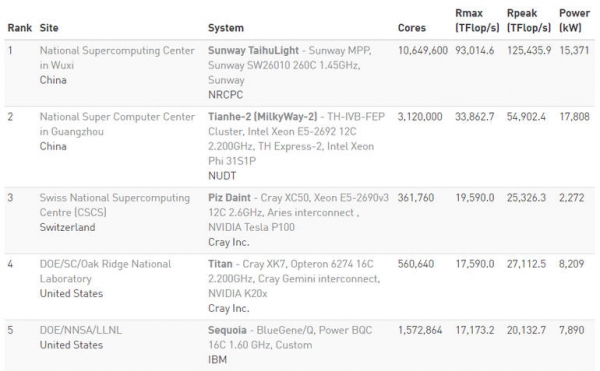
美国仍占据500强前五名的两个位置,但两台超级计算机都三甲不入
既是说,根据2017年6月的排名,美国的高性能计算系统21年来首次未进超级计算机基准测试项目Top500(500强)超级计算机的前三。
上一次美国超级计算机未进Top500排名前三是1996年,当时美国的超级计算机不敌三台日本超级计算机。
中国的神威·太湖之光排500强的第一位,太湖之光是目前全球浮点运算速度最快的计算机,即所谓的flops速度。太湖之光由中国国家平行计算机工程技术研究中心(英文缩写为NRCPC)研发,在Linpack性能测试下速度达93 petaflop,或93万亿flops。
太湖之光的flops速度自2016年6月启用以来一直未变,值得一提的是用的处理器是中国设计。
排在第二位的超级计算机是中国国防科技大学的天河二号,又名银河二号,速度达33.9 petaflops。
瑞士国家超级计算中心的Cray XC50系统最近的Nvidia GPU升级到Piz Daint,砍下第三位,排在美国能源部(DOE)橡树岭国家实验室Cray XK7超级计算机Titan的前面。
Top500指,Titan自2012年启用以来其Linpack得分保持在17.6 petaflops。Piz Daint在 11月份的得分为9.8 petaflops,Nvidia Tesla P100 GPU升级后得分翻了一番。
这次美国的排名顺序下滑其实是在预料之内。去年12月美国能源部和国家安全局举行了一次会议后曾有报告指,美国的10年投资需“激增”,以应对来自中国在高性能计算领域高速发展的竞争,否则美国在高性能计算领域的领先地位将面临威胁。
报告提出的警告称,如无激增,“美国的HPC能力差距预计在不到十年的时间内将出现并扩大”。 HPC能力差距将影响美国发展武器和国家安全系统的能力,而且对一些依赖HPC的行业(如汽车,航空航天和制药研究)产生连锁效应。
报告指出,中国将发展HPC本土化能力定为国策里的战略目标。报道的作者表示,以前中国的超级计算机“除了运行基准测试”外并无“惊人之处”,但太湖之光却“不是炫技”之举。值得注意的是,排位第一的超级计算机的硬件和软件均是中国制造。
不过目前美国依然在一些数字上领先中国。美国超级计算机在500强的前10里占了五席。此外,500强的169台超级计算机是美国的,比中国的160台多。
其他顶级超级计算机国家包括日本,拥有33台超级计算机,而德国有28台,法国17台,英国17台。
Top500榜单中绝大多数中心处理器芯片是英特尔至强或至强Phi处理器,500强里的464台超级计算机用的是英特尔至强或至强Phi处理器,其余的为IBM Power或AMD Opteron中心处理器。
而Nvidia GPU则是最流行的加速器,在使用了加速技术的91个系统里74个用了Nvidia GPU。 HPE是超级计算机的系统供应商霸主,提供 了500强里144台计算机,而Cray则统领系统性能,500强里占21.4%。
日本超级计算机则称霸绿色500强。这些超级计算机不是最强大的,但它们是最节能的。最绿色的超级计算机是东京科技大学的HPE ICE XA TSUBAME 3.0,在500强里排名61位。

美国能源部橡树岭国家实验室的Cray XK7超级计算机Titan排第四位,被挤出三强
雅虎日本的Exascaler kukai系统在绿色500强里排第二,排第三的是日本国家先进工业科学与技术研究所的NEC系统,名叫AIST AI Cloud(AIST 人工智能云)。
好文章,需要你的鼓励


OpenAI在版权诉讼中疑因隐瞒证据遭遇重大危机
OpenAI在与多家新闻机构的版权诉讼中陷入困境。以《纽约时报》为首的原告指控OpenAI在长达两年时间里向法庭撒谎,刻意隐瞒其已对ChatGPT日志进行大规模搜索的事实。据悉,OpenAI实际上已拥有包含1000万和7800万条记录的日志样本,并曾用于研究版权内容过滤器,却对外声称无法进行此类搜索。原告据此提出制裁动议,要求法院追责。OpenAI则否认相关指控,坚称其立场基于合理使用原则。

当AI学会“挑剔“:斯坦福与伯克利联手打造的智能验证框架,让AI自己检验自己的答案
斯坦福与UC伯克利提出LLM-as-a-Verifier框架,通过提取AI模型内部概率分布生成连续评分,在代码、机器人、医疗领域均达到最优性能,且无需额外训练。

外科医生远程操控人形机器人,完成全球首例活猪手术
美国加州大学圣地亚哥分校研究团队在《自然》期刊发表研究成果:外科医生通过远程操控宇树G1仿人机器人,成功完成两例活体猪胆囊切除手术,创下全球首例。与造价数十至数百万美元的达芬奇手术机器人相比,仿人机器人成本更低、体积更小,未来有望部署于农村、战地乃至太空等资源匮乏的医疗场景。但目前仍存在需频繁重新校准、机械臂活动范围受限等挑战。

字节跳动Seed团队发现:AI智能体学习新任务的速度,正以每三个月翻倍的惊人节奏增长
字节跳动Seed团队发现AI智能体在真实环境中学习的进步曲线精确遵循对数S形规律,R?达0.998,且前沿模型的学习速度每三个月翻倍。
2017
06/20
18:04
分享
点赞

OpenAI在版权诉讼中疑因隐瞒证据遭遇重大危机
外科医生远程操控人形机器人,完成全球首例活猪手术
OpenAI发布ChatGPT Work:AI助手可连续工作数小时
欧盟向Meta施压:关闭自动播放和无限滚动,否则面临巨额罚款
世界模型的潜力与局限:它真的能模拟一切吗?
苹果起诉OpenAI:前员工利用系统漏洞窃取商业机密
如何利用开源AI智能体实现工作流程自动化
Cloudzy 云服务评测:VPS 性能与体验全面解析
这款PCIe插卡内置38核至强处理器与64GB内存,堪称完整服务器
是否该为企业招募数字员工?AI 智能体团队搭建全指南
AI赋能自主机器人:从工厂走向家庭的未来图景
数据中心能源需求威胁特朗普"美国制造"计划
AI模型竞赛持续升温,芯片需求掀起新一轮淘金热
中国LineShine超算登顶全球最快超级计算机榜首
英国超级计算机投资滞后,审计署警告落后于国际竞争对手
英国气象局云端超算服务运行一周年
伦敦"超级计算机"项目背后:脚手架场地与AI投资泡沫
英国政府斥资3600万英镑大幅提升Dawn超级计算机性能
NVIDIA说,我们8年前就把AI带到了PC,现在「桌面AI」有了更多新玩法
开箱 NVIDIA DGX Spark: 把'一千万亿次'运算,“塞进”iPad mini大小的盒子里
破局AI数据中心安全瓶颈:Fortinet联合NVIDIA引领隔离式加速新航向
SC25超级计算大会:AMD、英伟达、戴尔发布下一代超算产品
